플랫폼은 왜 계속 다시 설계되어야 할까 - Server Platform Team 이야기
서버 플랫폼 팀이 조직 성장에 맞춰 플랫폼을 계속 재설계하는 이유를 소개했습니다. AI 시대의 분석·개발·운영 변화와 그에 따른 가드레일까지 함께 다뤘습니다.
#SRE#CI/CD#Argo
8300

SRE 태그가 달린 국내 IT 기업 기술 블로그 글을 최신순으로 모았습니다.
20개 표시
서버 플랫폼 팀이 조직 성장에 맞춰 플랫폼을 계속 재설계하는 이유를 소개했습니다. AI 시대의 분석·개발·운영 변화와 그에 따른 가드레일까지 함께 다뤘습니다.
인프라 인입 이슈를 AI 트리아지로 자동 분류하고 런북으로 라우팅하는 설계를 정리했습니다.\n분류와 실행을 분리하고, 사용자 컨펌 전 외부 액션을 막는 안전한 운영 원칙을 소개했습니다.
SLI/SLO를 서비스 관점에서 정의하고 운영에 적용하는 방법을 정리했습니다. 오류 예산과 대시보드를 활용해 신뢰성과 개발 리소스 균형을 맞추는 사례를 소개했습니다.

라포랩스 Backend Chapter Leader의 커리어와 팀 운영 방식, AI Native 전환 방향을 소개했습니다. 시니어 엔지니어의 역할을 팀 임팩트와 리더십 중심으로 설명했습니다.
SRE 반복 작업과 문의 대응을 Slack 워크플로 중심의 봇으로 자동화한 개발기입니다. 배포와 일반 요청 처리 시간을 크게 줄이고 운영 가시성도 높였습니다.

SLI/SLO 도입 과정을 공통 프레임워크로 정리하고 사내 템플릿으로 확산한 사례를 소개했습니다. 또한 웹훅과 DB 기반으로 자동 갱신되는 서비스 상태 확인 도구 LINE Status를 만든 과정을 공유했습니다.

장애 심각도를 기술 지표가 아니라 사용자 경험과 비즈니스 영향으로 정의한 사례를 소개했습니다. CUJ와 CSP, SLI, SEV를 연결해 대시보드와 얼럿 운영까지 체계화했습니다.
3개 서비스에 맞는 SLO와 모니터를 데이터 기반으로 표준화하고, 배포 중 Error Budget이 소진되지 않도록 자동화했습니다. 오탐을 줄이고 실제 비즈니스 실패를 더 정확히 탐지하는 운영 체계를 구축했습니다.
장애 대응에서 가장 중요한 초동 조치와 이를 관리하는 라이프사이클을 정리했습니다. 시간 기반 메트릭으로 병목을 찾고 운영 개선으로 연결하는 방식을 소개했습니다.
외부 온콜 솔루션의 비용과 안정성 한계를 해결하기 위해 서버리스 기반 온콜 시스템을 구축했습니다. 이메일 트리거, 큐 기반 제어, SMS 이중화로 안정성과 비용 효율을 함께 높였습니다.

AWS re:Invent 2025에서 AI 에이전트와 이를 지원하는 인프라·플랫폼의 방향을 정리했습니다. 개발자는 AI를 보조 도구로 활용하되, 검증과 책임, 시스템 사고를 더 강화해야 한다고 강조했습니다.
기존 시스템 지표 모니터링의 한계를 보완하기 위해 서비스 이상 탐지 시스템을 도입했습니다. 중앙값 기반 탐지와 대응 자동화로 정밀도와 탐지율을 높이고 전파 시간을 크게 줄였습니다.
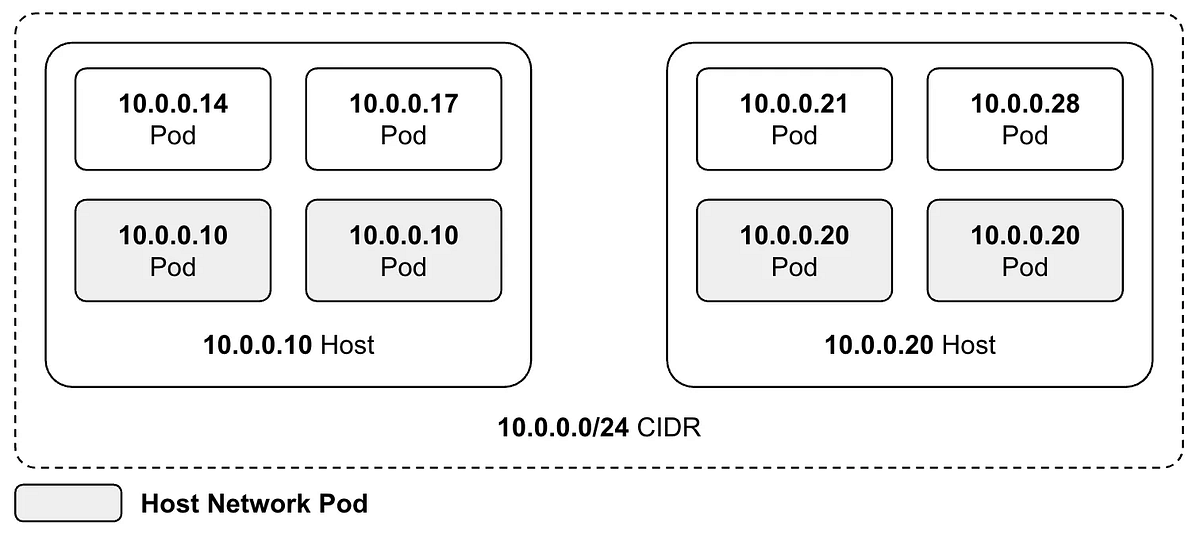
Kubernetes Pod의 Host Network 설정 개념과 장단점을 설명하고, DaemonSet과 Job Pod에 적용한 사례를 공유했습니다. IP 절감과 시작 속도 개선 효과를 얻었지만 포트 충돌 예외 처리가 필요했습니다.
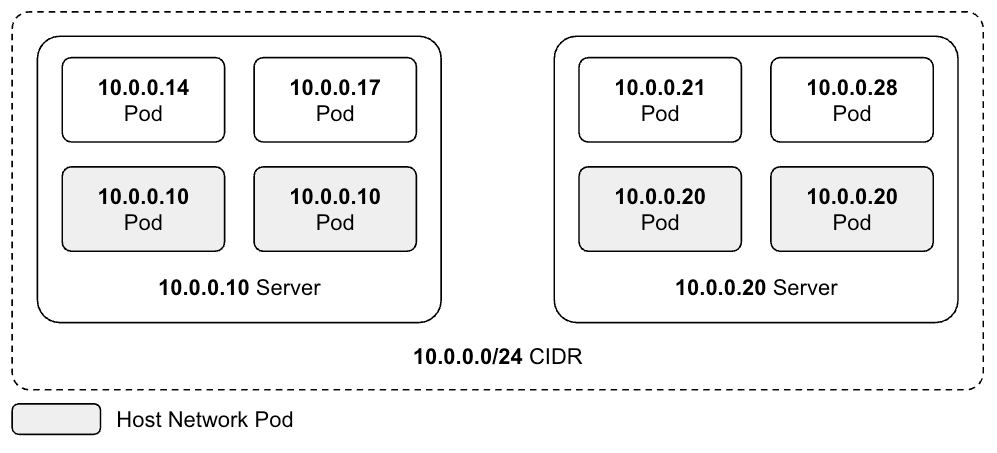
쿠버네티스 파드에 Host Network를 적용한 배경과 효과를 정리했습니다. DaemonSet의 IP 절약과 Job 파드의 생성 지연 개선 사례를 함께 소개했습니다.
카카오페이증권이 고객 관점의 장애 가시화와 대응 자동화를 위해 핑크와드를 구축했습니다. 장애 탐지부터 담당자 호출, 요약, 보고서 작성까지 통합해 대응 시간을 크게 줄였습니다.

서비스의 건강을 수치로 보기 위해 SLI와 SLO를 정의하고 운영하는 방법을 소개했습니다. 29CM 사례를 통해 지표 설계, 모니터링, 지속 개선 체계를 설명했습니다.

AI가 SRE의 역할을 장애 대응 중심에서 예측과 품질 관리 중심으로 바꾸고 있음을 설명했습니다. 메르카리와 AIOps 사례를 통해 AI 신뢰성과 인간 협업의 필요성을 정리했습니다.

AI가 SRE를 장애 대응자에서 예측·자동화 중심의 운영 전략가로 바꾸고 있습니다. 메르카리 사례처럼 품질 검증과 안전장치를 갖춘 인간-AI 협업이 중요합니다.
Kubernetes 기반 마이크로서비스의 가시성을 확보하기 위해 OpenTelemetry와 SigNoz를 활용한 Observability 구축 과정을 정리했습니다. Collector 파이프라인과 Auto-Instrumentation, 운영 효율 개선 포인트를 함께 소개했습니다.
AWS Summit Seoul 2025에서 클라우드 스케일링 자동화와 비즈니스 중심 모니터링 사례를 공유했습니다. 급격한 트래픽에 대비해 분류 기준, 증설 대상, 자동화 흐름을 정리했습니다.
