Alert 시스템을 표준화하고 IaC로 운영하기
Alert 생성과 전달, 대응 흐름을 IaC와 표준화된 Slack 메시지로 정리한 개선 과정을 소개했습니다. 반복 Alert 재사용, grouped Alert, AI 연동, 모니터링 자체 감시까지 운영 개선을 다뤘습니다.
#IaC#Grafana#Slack
200
Alert 시스템을 표준화하고 IaC로 운영하기
Grafana 태그가 달린 국내 IT 기업 기술 블로그 글을 최신순으로 모았습니다.
20개 표시
Alert 생성과 전달, 대응 흐름을 IaC와 표준화된 Slack 메시지로 정리한 개선 과정을 소개했습니다. 반복 Alert 재사용, grouped Alert, AI 연동, 모니터링 자체 감시까지 운영 개선을 다뤘습니다.
Slack 봇 창식이를 통해 하네스 엔지니어링과 컨텍스트/피드백 루프 설계를 실제 운영에 적용한 사례를 정리했습니다. MCP 채널, 지식 베이스, 교정 로그로 장기 작업의 정확도를 높인 구성이 핵심입니다.
Kubernetes Pod의 Request와 Limit을 실제 사용 패턴에 맞게 조정하는 Right-Sizing 기준 수립 과정을 다뤘습니다. P95, 버퍼율, 컴포넌트 특성, Throttling 지표를 함께 고려하는 방법을 정리했습니다.
StarRocks에서 Resource Group으로 멀티테넌트 워크로드를 분류하고 CPU 우선순위를 조절한 운영 경험을 정리했습니다. 서비스 SLA가 필요한 경우에는 exclusive_cpu_cores와 주의점을 함께 적용했습니다.

SLI/SLO 도입 과정을 공통 프레임워크로 정리하고 사내 템플릿으로 확산한 사례를 소개했습니다. 또한 웹훅과 DB 기반으로 자동 갱신되는 서비스 상태 확인 도구 LINE Status를 만든 과정을 공유했습니다.

Claude Code로 Slack·VS Code·Jupyter를 묶어 맥락이 이어지는 AI 비서를 설계하고 실무 자동화 사례를 소개했습니다. 개인 워크스페이스를 조직 자산으로 확장하는 방향과 AI를 대하는 실용주의도 함께 정리했습니다.
FCFS 기반 제휴 상품 연동의 한계를 보완하기 위해 SoAP 점수 체계를 도입했습니다. 주요 상품의 우선순위를 높여 연동 속도와 운영 효율을 개선했습니다.
Claude Code의 사용 패턴과 비용, 성능을 팀 단위로 모니터링하는 4가지 방법을 정리했습니다. OpenTelemetry, SigNoz, Datadog, claude-code-otel로 ROI와 활용도를 확인할 수 있습니다.

QA 자동화 결과를 DB와 Grafana로 관리하며 Fail 원인을 주간 단위로 분석하고 개선했습니다. 협업과 일정 관리를 더해 3Q 목표였던 Fail률 0.7% 미만을 달성했습니다.
LGTM 스택의 개요와 Mimir, Tempo, Loki의 구조를 처음 도입 관점에서 정리했습니다. 또한 배포 모드와 운영 시 주의할 점을 함께 소개했습니다.
입사 2일차에 실제 앱 기능을 배포하며 빠르게 실무에 적응한 프론트엔드 인턴 인터뷰입니다. 레거시 정리와 성능 개선, 모니터링 도구 활용을 통해 팀의 생산성과 안정성에 기여한 경험을 전했습니다.
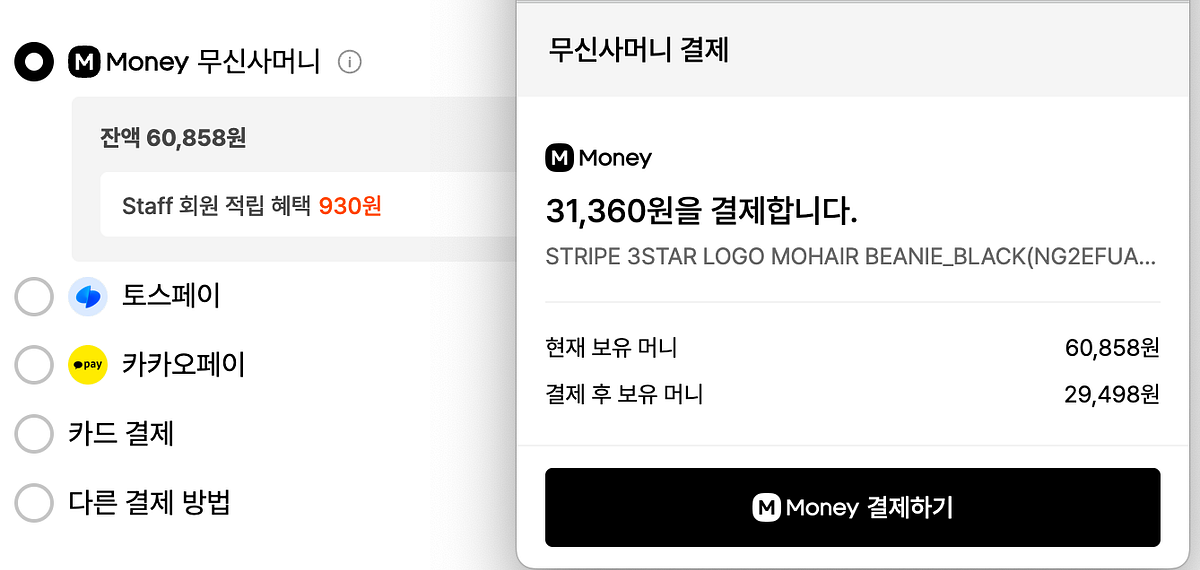
29CM 주문서에 무신사머니를 외부 서비스 연동으로 도입한 사례를 소개했습니다. 안정성과 연속성을 위해 폴백, 서킷 브레이커, 전략 패턴, 파드 증설을 적용했습니다.
29CM 주문서에 무신사머니를 외부 연동 방식으로 도입하며 안정성과 연속성을 우선해 설계했습니다. 점진적 기능 저하와 서킷 브레이커, 모니터링과 증설 전략으로 운영 안정성을 확보했습니다.
테스트 자동화 환경을 Master Jenkins와 Mac Node 구조로 통합했습니다. IP 변경, 장애 전파, 자원 분산 문제를 줄이고 운영 효율과 안정성을 높였습니다.

Kafka Broker request log와 METADATA API를 활용해 서비스와 Topic 연결을 실시간으로 추적하는 방법을 소개했습니다. ClickHouse, conntrack, Lag metric 조인으로 소스 수정 없이 MSA 관측성을 높였습니다.

검색서비스팀의 SCAR 모니터링 시스템 고도화와 전체 구조를 소개했습니다. 기존 로그 기반 방식의 한계를 짚고, 수집·집계·시각화 분리와 품질 지표 확장을 다뤘습니다.

서비스의 건강을 수치로 보기 위해 SLI와 SLO를 정의하고 운영하는 방법을 소개했습니다. 29CM 사례를 통해 지표 설계, 모니터링, 지속 개선 체계를 설명했습니다.

Nginx 설정을 공통화하고 멀티사이트 구조로 통합한 인프라 개선 사례를 소개했습니다. Promtail과 Loki, Ansible을 연계해 로그 수집과 배포 자동화까지 확장했습니다.

토스증권이 H100 GPU의 자원 낭비를 줄이기 위해 MIG 기반 GPU 가상화를 도입한 과정을 정리했습니다. Kubernetes 연동과 모니터링 설정까지 포함해 운영 관점의 적용 방법을 설명했습니다.

DevLake로 DORA Metrics 수집과 시각화를 도입한 사례를 정리했습니다. Jira 커스텀 필드와 쿼리를 내부 운영 기준에 맞게 조정한 과정도 다뤘습니다.