옴니채널 재고 정합성 한계에 대응하는 인벤토리 데이터 파이프라인 구축기
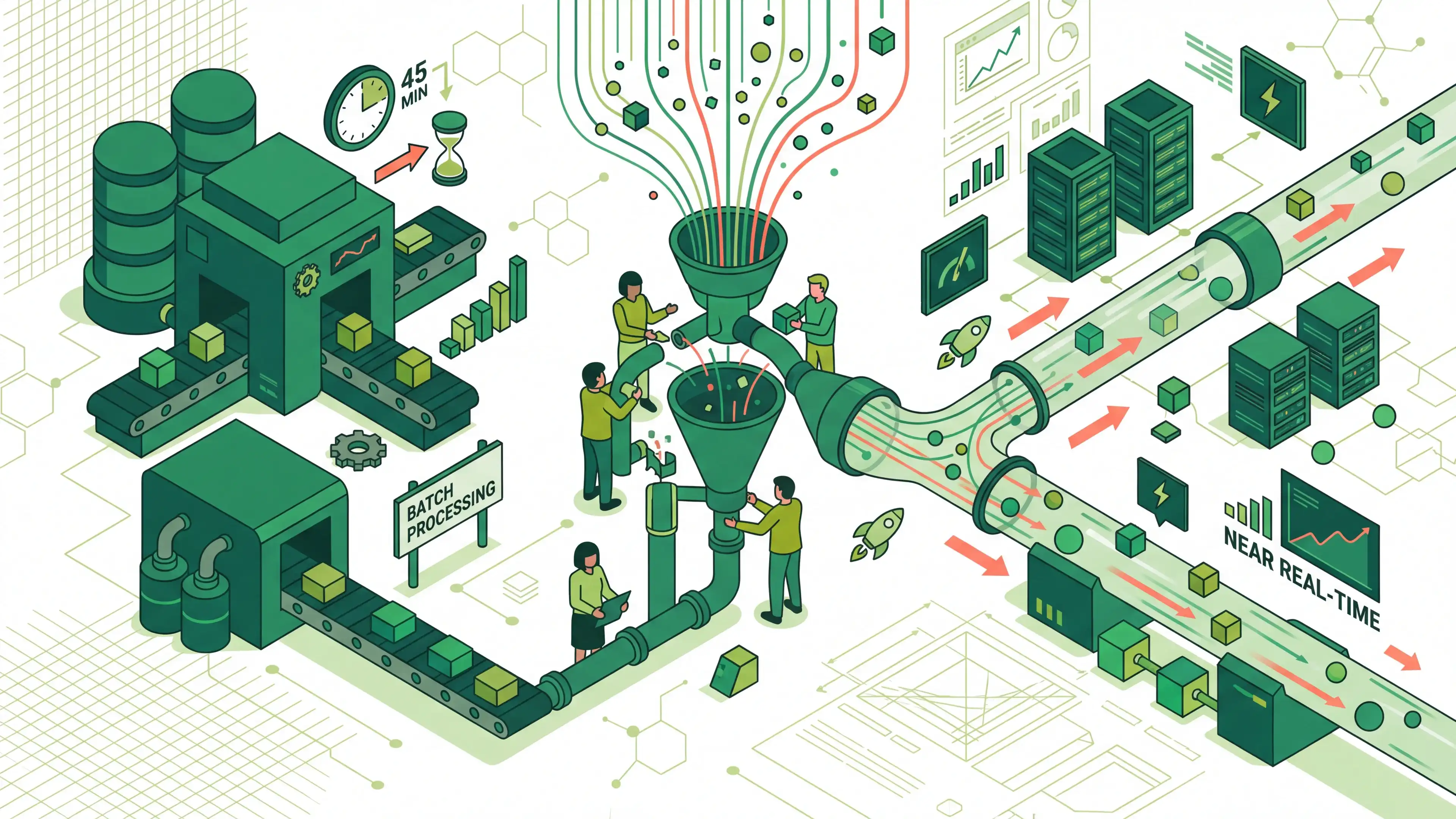
옴니채널 재고 정합성과 확장성 문제를 해결하기 위해 인벤토리 데이터 파이프라인을 이벤트 기반으로 재설계했습니다. Spring Batch, Kafka Fan-Out, Push/Pull 분리로 리드타임과 부하를 줄였습니다.
#Kafka#Spring Batch#AWS
800
옴니채널 재고 정합성 한계에 대응하는 인벤토리 데이터 파이프라인 구축기
Kafka 태그가 달린 국내 IT 기업 기술 블로그 글을 최신순으로 모았습니다.
20개 표시
옴니채널 재고 정합성과 확장성 문제를 해결하기 위해 인벤토리 데이터 파이프라인을 이벤트 기반으로 재설계했습니다. Spring Batch, Kafka Fan-Out, Push/Pull 분리로 리드타임과 부하를 줄였습니다.
의료 설문 플랫폼에서 설문 정의와 수집을 담당하는 서비스를 헥사고날 구조와 CQRS로 설계했습니다. Master/Snapshot, Kafka, Outbox 등을 적용해 정합성과 운영 안정성을 확보했습니다.
플랫폼팀이 코드 바깥의 환경 실체를 선언으로 만드는 방식을 설명했습니다. Kafka 토픽 선언과 검증, 추적 가능한 거버넌스 사례를 다뤘습니다.
Flava DBaaS의 쿠버네티스 기반 아키텍처와 운영 구조를 소개했습니다. 또한 마이그레이션 도구와 서버리스, AI 기반 확장 방향까지 설명했습니다.

MySQL 기반 광고 성과 집계의 확장성과 안정성 문제를 해결하기 위해 StarRocks를 도입했습니다.\n외부 원천, MV 설계, 아키텍처 전환으로 부하 분리와 복구 편의성을 확보했습니다.

Iceberg 운영에서 스냅샷 폭증과 Small File 문제를 어떻게 다뤘는지 정리했습니다. 작업 이력 관리와 메인터넌스 정책으로 비용과 성능을 개선한 사례입니다.
X

서버 플랫폼 팀이 조직 성장에 맞춰 플랫폼을 계속 재설계하는 이유를 소개했습니다. AI 시대의 분석·개발·운영 변화와 그에 따른 가드레일까지 함께 다뤘습니다.

KBO 리그 이닝 교체 때 몰리는 광고 요청을 분산하기 위해 prefetching과 내부 캐시 구조를 적용했습니다. 그 결과 외부 광고 서버 부하와 지연을 줄이고 버퍼링 지표도 개선했습니다.
Kafka 파티션 수를 처리량과 컨슈머 catch-up 기준으로 계산하는 산정식을 정리했습니다. 운영 환경 실측값을 반영해 토픽별 초기 파티션 수를 일관되게 정하는 방법을 제안했습니다.
카프카 파티션 수를 정하는 산정식과 기준값을 설계한 과정을 정리했습니다. 프로듀서 처리량, 컨슈머 catch-up, 운영 한도를 함께 고려해 초기 파티션 수 판단 기준을 제안했습니다.
테스트 인프라를 프로덕션 구조에 맞춰 variant와 스냅샷 캐시로 분리·재사용하는 방법을 정리했습니다. 경계를 깎아 교체 가능성을 만들면 CI와 개발 이터레이션이 함께 빨라졌습니다.
![[코드가 환경을 모르는 구조 7/7] Variant와 스냅샷 캐시, 그리고 다섯 축의 총합](https://flex.team/blog/og/main.jpg)
테스트 인프라에서 variant와 스냅샷 캐시로 프로덕션의 분리를 그대로 재현하는 구조를 설명했습니다. 경계를 명확히 하면 교체 가능성이 높아지고 실험 속도도 빨라진다고 정리했습니다.
![[코드가 환경을 모르는 구조 7/7] Variant와 스냅샷 캐시, 그리고 다섯 축의 총합](https://cdn.sanity.io/images/v31psllp/production/05ffda096002d40620c7bc75e64174185b7d8a1d-1684x1030.png)
MSA 환경에서 전체 시스템을 띄우지 않고 수정 중인 서비스만 로컬로 교체하는 Rewrite Host를 소개했습니다. 디버그 헤더로 라우팅을 바꾸고, 응답 헤더로 적용 여부를 알려주는 방식입니다.
![[코드가 환경을 모르는 구조 5/7] Rewrite Host — 공간 축을 교체한다](https://cdn.sanity.io/images/v31psllp/production/880cbd1201bc94d8f408147dcd135aef78e683b4-1684x1030.png)
HR SaaS에서 시간을 비즈니스 입력으로 보고, 요청 헤더와 `Clock` Adapter로 현재 시점을 교체하는 타임머신 구조를 설명했습니다. 비동기 경계 전파와 환경별 활성화, 서드파티 시계 호출의 한계도 함께 다뤘습니다.
StarRocks에서 Resource Group으로 멀티테넌트 워크로드를 분류하고 CPU 우선순위를 조절한 운영 경험을 정리했습니다. 서비스 SLA가 필요한 경우에는 exclusive_cpu_cores와 주의점을 함께 적용했습니다.

상품·쿠폰·증정·프로모션 데이터를 Kafka 기반 준실시간 구조로 전환한 사례입니다.\nRedis Pub/Sub, Aggregation Topic, Shadow Table로 정합성과 안전한 이관을 확보했습니다.
채널톡 메인 백엔드 서버의 CI 병목을 단계적으로 분해해 개선한 과정을 정리했습니다. 공유 상태 제거, prepare 분리, 동적 큐와 캐시로 실행 시간을 크게 줄였습니다.
AI가 코드를 빠르게 만들수록 CI 병목과 피드백 속도가 더 중요해졌습니다. 채널톡은 공유 상태 제거와 캐시, 동적 큐로 메인 백엔드 CI를 36.6분에서 15분대까지 줄였습니다.
Apache Flink와 RocksDB 튜닝으로 광고 Frequency Capping 실시간 집계를 7일 구간까지 확장한 사례를 다루었습니다. 세 개의 Flink 앱으로 분리해 병목을 각각 해결하고 Redis 단일 조회 구조로 단순화했습니다.