Agentic AIOps — RCA 에이전트 ‘SentryOn’ 도입기 (feat. Strands SDK)
MSA 장애 대응의 복잡성을 줄이기 위해 RCA 에이전트 SentryOn을 도입한 과정을 소개했습니다. 도메인 지식, 데이터 정제, Skill 분리, 프롬프트 캐싱으로 정확도와 효율을 높였습니다.
#AIOps#AWS#EKS
500
Agentic AIOps — RCA 에이전트 ‘SentryOn’ 도입기 (feat. Strands SDK)
Elasticsearch 태그가 달린 국내 IT 기업 기술 블로그 글을 최신순으로 모았습니다.
20개 표시
MSA 장애 대응의 복잡성을 줄이기 위해 RCA 에이전트 SentryOn을 도입한 과정을 소개했습니다. 도메인 지식, 데이터 정제, Skill 분리, 프롬프트 캐싱으로 정확도와 효율을 높였습니다.
테스트 인프라를 프로덕션 구조에 맞춰 variant와 스냅샷 캐시로 분리·재사용하는 방법을 정리했습니다. 경계를 깎아 교체 가능성을 만들면 CI와 개발 이터레이션이 함께 빨라졌습니다.
![[코드가 환경을 모르는 구조 7/7] Variant와 스냅샷 캐시, 그리고 다섯 축의 총합](https://flex.team/blog/og/main.jpg)
테스트 인프라에서 variant와 스냅샷 캐시로 프로덕션의 분리를 그대로 재현하는 구조를 설명했습니다. 경계를 명확히 하면 교체 가능성이 높아지고 실험 속도도 빨라진다고 정리했습니다.
![[코드가 환경을 모르는 구조 7/7] Variant와 스냅샷 캐시, 그리고 다섯 축의 총합](https://cdn.sanity.io/images/v31psllp/production/05ffda096002d40620c7bc75e64174185b7d8a1d-1684x1030.png)
퀸잇 검색 시스템이 MySQL LIKE에서 시작해 Elasticsearch, 벡터 검색, RRF를 거친 하이브리드 구조로 진화한 과정을 정리했습니다. 성능과 품질, 복잡도의 균형을 실험과 장애 대응으로 개선한 사례를 담았습니다.
메리츠증권은 규제 준수와 성능을 함께 만족하는 AWS 기반 차세대 증권 플랫폼을 설계했습니다. EKS, MSK, ElastiCache, OpenSearch, Flink와 오픈소스 도구를 결합해 실시간 처리와 운영 자동화를 강화했습니다.

Elasticsearch 좌표 검색에 거리 기반 가중치를 더해 랭킹을 최적화하는 방법을 소개했습니다. 구간별 weight와 decay 함수를 비교하며 자연스러운 노출을 위한 주의점을 설명했습니다.
레거시 인프라를 정리하고 OpenStack 기반 프라이빗 클라우드를 새로 구축했습니다. AWS와 Active-Active 하이브리드로 운영하며 자동화와 고가용성을 확보했습니다.

Elasticsearch 롤링 재시작 시 캐시 미준비 노드로 트래픽이 유입돼 지연과 장애가 발생하는 문제를 다뤘습니다. search-coordinator 프록시로 워밍업 완료 노드에만 검색 트래픽을 보내는 구조를 소개했습니다.
대규모 거래 데이터를 빠르게 서빙하기 위해 Elasticsearch, Druid, StarRocks를 역할별로 조합한 사례를 다뤘습니다. 집계·조인·검색을 분리하고 최적화해 응답 속도와 운영 효율을 높였습니다.

Elasticsearch 데이터 노드 재시작 시 캐시 미적재로 레이턴시가 급증하는 문제를 다뤘습니다. search-coordinator와 웜업 절차로 배포 중에도 안정적으로 트래픽을 받도록 개선했습니다.
레거시 검색 시스템을 OpenSearch 기반 MSA로 분리해 안정성과 운영성을 높였습니다. 대규모 마이그레이션과 문서화, 모니터링 체계를 정비해 향후 AI 검색 확장 기반도 마련했습니다.
자연어 질의에 맞지 않던 기존 검색 구조를 개선하기 위해 하이브리드 인덱스를 설계했습니다. OpenSearch와 임베딩 기반 벡터 검색을 결합해 검색 품질과 운영 효율을 높였습니다.
결제 SDK의 연동 복잡성과 운영 문제를 해결하기 위해 V2 SDK를 다시 설계했습니다. 계층 분리와 계약 중심 구조로 안정성, 확장성, 명확성을 강화했습니다.

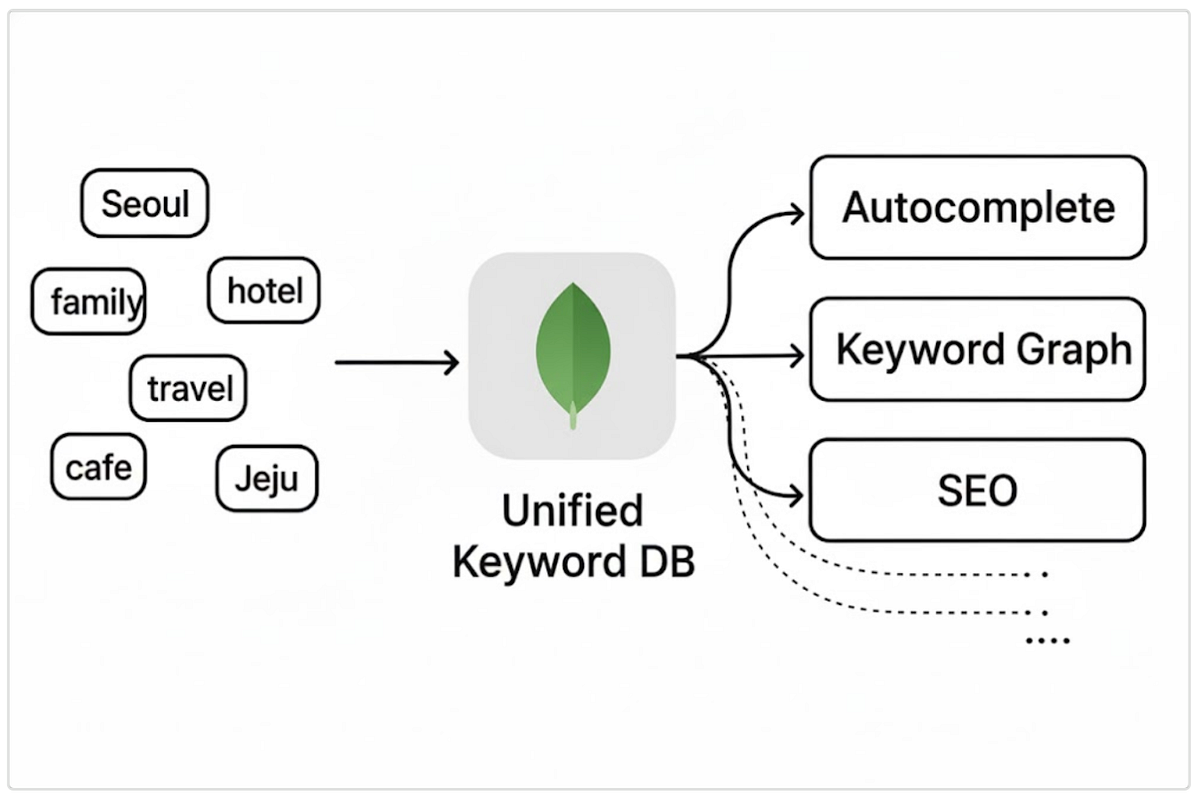
여기어때가 분산된 검색 키워드 데이터를 MongoDB 기반 단일 허브로 통합한 사례를 소개했습니다. 데이터 관리 일관성과 자동완성 구조 단순화를 통해 확장성을 높였습니다.
검색 광고의 랭킹 부스트 기능을 설계하고, 노출 수 예측 대신 순위 상승 보장 방식으로 전환했습니다.\n데이터 수집, Delta Score 계산, Elasticsearch 가중치 주입과 A/B 테스트 검증 과정을 정리했습니다.

LLM과 벡터 검색을 결합해 마케터의 자연어를 실행 가능한 세그먼트로 바꾸는 Seg Lens 개발기를 소개했습니다. 기존 수동 조건 생성의 한계를 줄이고 의미 기반 탐색과 권한 제어를 함께 구현했습니다.
대규모 검색 API를 멀티모듈 구조로 리팩토링한 사례를 정리했습니다. 도메인 분리와 의존성 정리를 통해 유지보수성과 협업 효율을 높이는 방법을 설명했습니다.
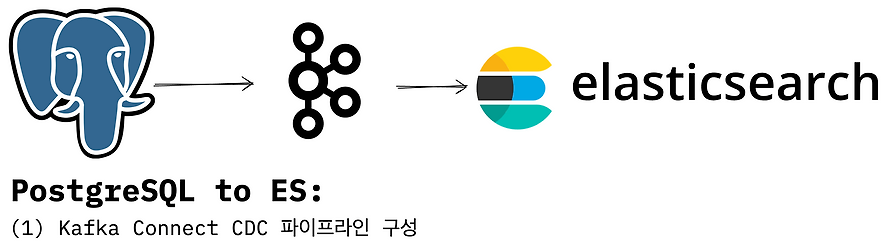
PostgreSQL 데이터를 Elasticsearch로 동기화하는 Kafka Connect CDC 파이프라인 구성 글입니다. 10년 넘게 운영한 레거시 시스템의 검색 연동 맥락을 소개합니다.
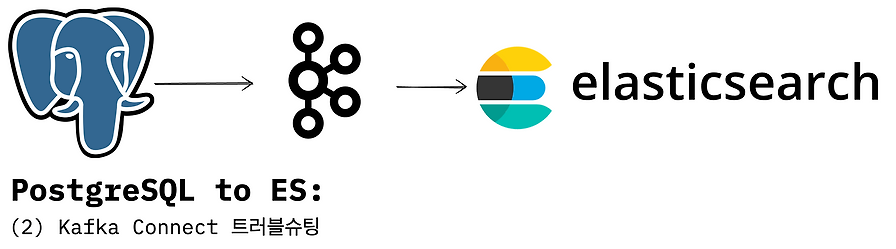
PostgreSQL에서 ES로의 CDC 파이프라인을 Kafka Connect로 구성한 뒤의 트러블슈팅 글입니다. 제공된 본문만으로는 구체적 문제와 해결 내용은 확인되지 않습니다.
검색서비스팀의 SCAR 모니터링 시스템 고도화와 전체 구조를 소개했습니다. 기존 로그 기반 방식의 한계를 짚고, 수집·집계·시각화 분리와 품질 지표 확장을 다뤘습니다.
