에러로그 하나에 깨던 새벽에서 벗어나기까지 — 상품 모니터링 진화기
상품 모니터링 체계를 Slack 알림 중심에서 DLQ 재처리, Workflow 자동 분석, 정합성 자동화로 진화시켰습니다. 사람이 개입할 일을 줄이고 장애 판단과 대응 속도를 높인 사례를 공유했습니다.
#Datadog#DLQ#Slack
700
에러로그 하나에 깨던 새벽에서 벗어나기까지 — 상품 모니터링 진화기
CDC 태그가 달린 국내 IT 기업 기술 블로그 글을 최신순으로 모았습니다.
20개 표시
상품 모니터링 체계를 Slack 알림 중심에서 DLQ 재처리, Workflow 자동 분석, 정합성 자동화로 진화시켰습니다. 사람이 개입할 일을 줄이고 장애 판단과 대응 속도를 높인 사례를 공유했습니다.
테스트 인프라를 프로덕션 구조에 맞춰 variant와 스냅샷 캐시로 분리·재사용하는 방법을 정리했습니다. 경계를 깎아 교체 가능성을 만들면 CI와 개발 이터레이션이 함께 빨라졌습니다.
![[코드가 환경을 모르는 구조 7/7] Variant와 스냅샷 캐시, 그리고 다섯 축의 총합](https://flex.team/blog/og/main.jpg)
Hexagonal Modular Monolith 구조 위에서 Outbox와 CDC로 도메인 간 이벤트 일관성을 보장하는 방식을 설명했습니다. 멱등 컨슈머와 공통 라이브러리로 신뢰성 있는 이벤트 레일을 만든 사례를 다뤘습니다.
![[미래를 담아낸 뼈대 2/7] 모듈 경계를 넘는 이벤트](https://cdn.sanity.io/images/v31psllp/production/1a44cf6f463c5690a413e9454bd7747d831f131f-1684x1030.png)
기획서가 없는 블랙박스 시스템을 내재화하며, 입력·출력 정의와 병렬 검증으로 동일성을 증명했습니다. Kafka와 CDC, OpenSearch를 활용해 조회·업데이트·E2E 전환을 안전하게 검증했습니다.

전수 적재의 지연과 정합성 문제를 해결하기 위해 CDC 기반 증분 복제 파이프라인을 설계했습니다. 전체 로우 해시와 사후 검증으로 멱등성과 신뢰도를 높이고, 시간 단위 배치로 최신성을 개선했습니다.
NiFi 기반 CDC 파이프라인의 확장성과 안정성 한계를 해결하기 위해 Debezium과 Flink로 재설계했습니다. Kafka, 체크포인트, 메트릭 모니터링을 결합해 정합성과 처리량을 높였습니다.
ODI 배치 기반 캠페인 동기화를 OGG와 Kafka 기반 CDC로 전환한 사례를 다뤘습니다. 메시지 순서 문제는 Retry, DLT, 복구 배치로 보완했고 실시간 정합성과 운영 모니터링을 강화했습니다.
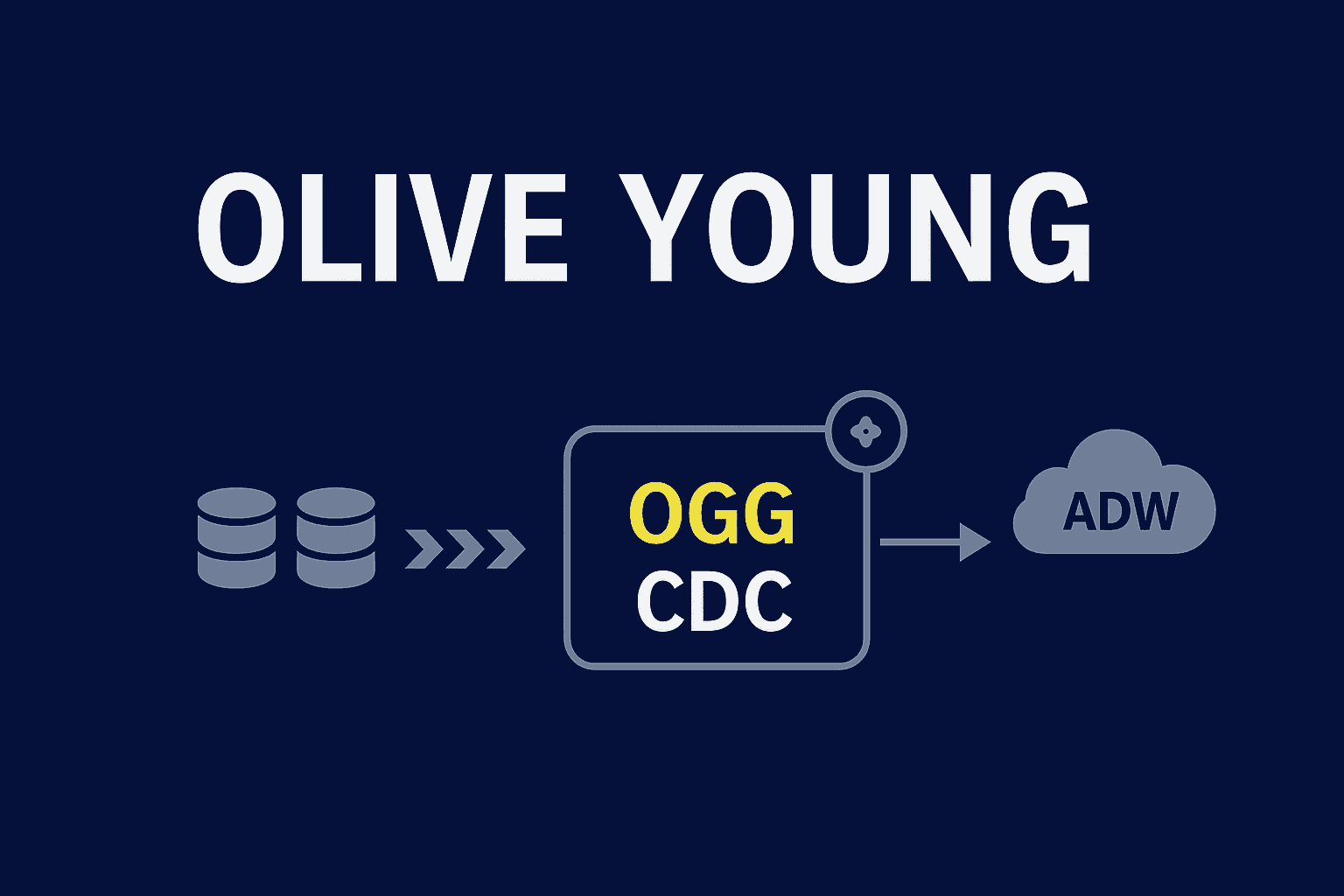
Karrot가 MongoDB 적재 방식의 한계를 해결하기 위해 CDC를 도입한 과정을 공유했습니다. 변경 로그 기반으로 BigQuery 적재를 구성하되, 초기 스냅샷은 별도 도구 활용을 검토했습니다.
MongoDB 덤프의 DB 부하와 SLO 문제를 해결하기 위해 CDC를 도입했습니다. Flink CDC와 Spark, 이중 테이블 구조로 적재와 스키마 변경, 정합성 검증을 묶었습니다.
네이버페이 주문의 DB CDC 복제 도구를 ergate로 전환한 경험을 공유했습니다. Flink와 Spring으로 복제, 검증, 복구를 분리해 성능과 운영 편의성을 개선했습니다.
Kafka 소비 결과를 Parquet으로 변환해 S3에 적재하는 실시간 수집 파이프라인을 설계하고 구축했습니다. 또한 Flush, 커밋, 모니터링 체계를 통해 누락 없이 안정적으로 운영하는 방법을 정리했습니다.

리멤버앤컴퍼니가 Aurora MySQL의 분석 부하를 줄이기 위해 S3 Tables 기반 CDC 데이터 레이크를 구축한 과정을 다뤘습니다. 기존 데이터 이관, Debezium·MSK·Iceberg Kafka Connect 설정과 운영상 주의점을 정리했습니다.

PostgreSQL 데이터를 Elasticsearch로 동기화하는 Kafka Connect CDC 파이프라인 구성 글입니다. 10년 넘게 운영한 레거시 시스템의 검색 연동 맥락을 소개합니다.
PostgreSQL에서 ES로의 CDC 파이프라인을 Kafka Connect로 구성한 뒤의 트러블슈팅 글입니다. 제공된 본문만으로는 구체적 문제와 해결 내용은 확인되지 않습니다.
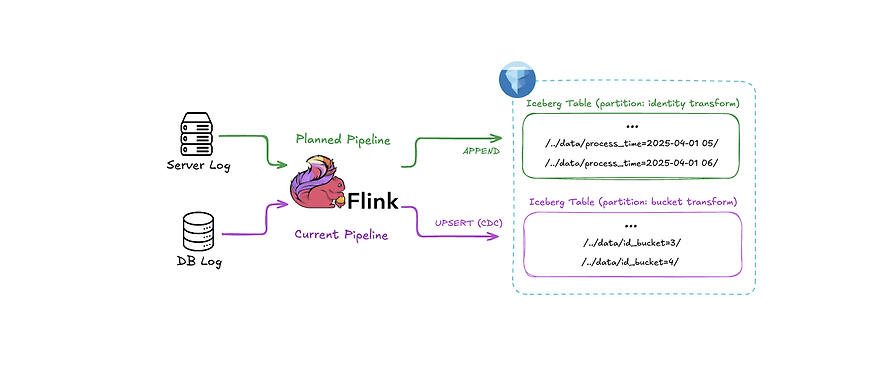
Iceberg CDC에서 발생하는 정합성 이슈와 원인을 정리하고, Position Delete 중심의 처리 원칙을 설명했습니다. Kafka key 설정, Commit Timeout, Schema Evolution 대응으로 중복 문제를 해결한 사례를 공유했습니다.

뮤직카우가 Amazon RDS와 Amazon Redshift를 Zero-ETL로 연결해 준실시간 CDC 파이프라인을 구축한 사례를 공유했습니다. DMS 대비 관리 부담과 비용을 줄이고 자동 복구까지 활용한 설정 방법과 주의사항을 정리했습니다.

DBT와 CDC, Airflow로 클라이언트 여정을 추적하는 `data_logs` 테이블 구축 사례를 소개했습니다.복잡한 조인과 스캔 비용을 줄이기 위해 증분 모델링과 파티션 최적화를 적용했습니다.
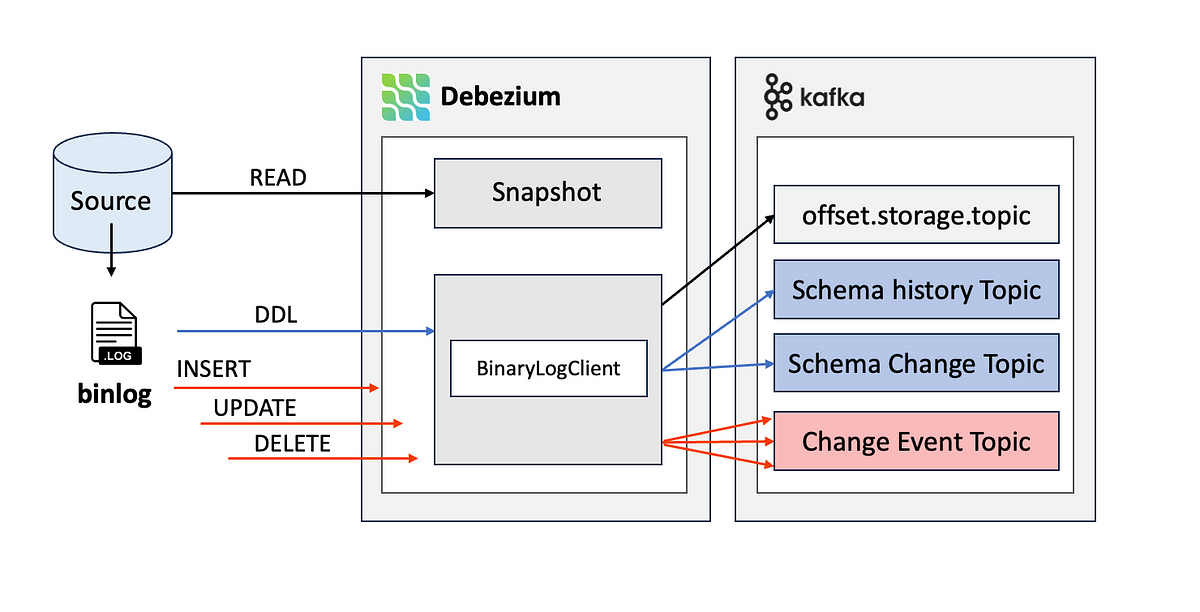
기존 배치 적재의 지연을 줄이기 위해 Debezium 기반 실시간 CDC 파이프라인을 구축한 과정을 정리했습니다. Kafka Connect 구조, 스냅샷, 오프셋 관리와 성능 개선 포인트까지 살펴보았습니다.
쿠폰 적용 가능 상품을 실시간으로 조회하기 위해 이벤트 기반 반정규화와 Elasticsearch 인덱싱 구조를 구축했습니다. 복잡한 매핑과 갱신 조건을 단순화하고 검색 성능과 운영성을 함께 개선했습니다.

X