현대오토에버의 Amazon Bedrock으로 구축한 빅데이터 클러스터 장애 대응 자동화 에이전트 구축기
LangGraph와 Amazon Bedrock, OpenSearch를 결합해 빅데이터 클러스터 장애 대응을 자동화했습니다. 병렬 RCA와 반증 검증으로 진단 품질을 높이고 MTTA를 줄였습니다.
#Amazon Bedrock#LangGraph#Amazon OpenSearch Service
6000

FastAPI 태그가 달린 국내 IT 기업 기술 블로그 글을 최신순으로 모았습니다.
20개 표시
LangGraph와 Amazon Bedrock, OpenSearch를 결합해 빅데이터 클러스터 장애 대응을 자동화했습니다. 병렬 RCA와 반증 검증으로 진단 품질을 높이고 MTTA를 줄였습니다.
AI를 서비스와 인프라에 어떻게 적용하고 운영할지 다룬 기술 소식 모음입니다. 공공 AI 인프라, 프레임워크 비교, 플랫폼 재설계와 Agent 구축 흐름을 소개했습니다.

Python 기반 AI API Gateway에서 FastAPI와 Robyn의 성능을 비교했습니다.\n고부하 상황의 지연 안정성과 연결 생존력에서 Robyn의 장점을 확인했습니다.
![[비교분석] FastAPI는 충분히 빠르지 않다? Robyn과의 성능 차이 직접 비교](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fd51Qdr%2FdJMcaffegwA%2FAAAAAAAAAAAAAAAAAAAAABQpmOP7LSCwKCElS8wD7hQwBtr2oAvG2GBO0CQwvpdg%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DTHNXmCuMMNdpE6SgXDeFHiUKQdE%253D)
이직 스트레스로 고민을 털어놓을 GIGACHAD 채팅봇을 만들었습니다.\n비밀 보장, 저비용 운영, Gemini Flash 2.0 선택 이유를 정리했습니다.

AWS와 리멤버 해커톤에서 영업팀용 AI 에이전트 샐리 개발 사례를 공유했습니다.리드 발굴과 반복 업무를 자동화하고, 멀티 에이전트 구조를 단순화해 성능을 개선했습니다.

항공권 환불 규정 계산을 AI와 코드로 분담해 자동화한 사례를 다뤘습니다. 최종적으로 응답 시간을 5초 이내로 줄이고 고객 경험도 개선했습니다.
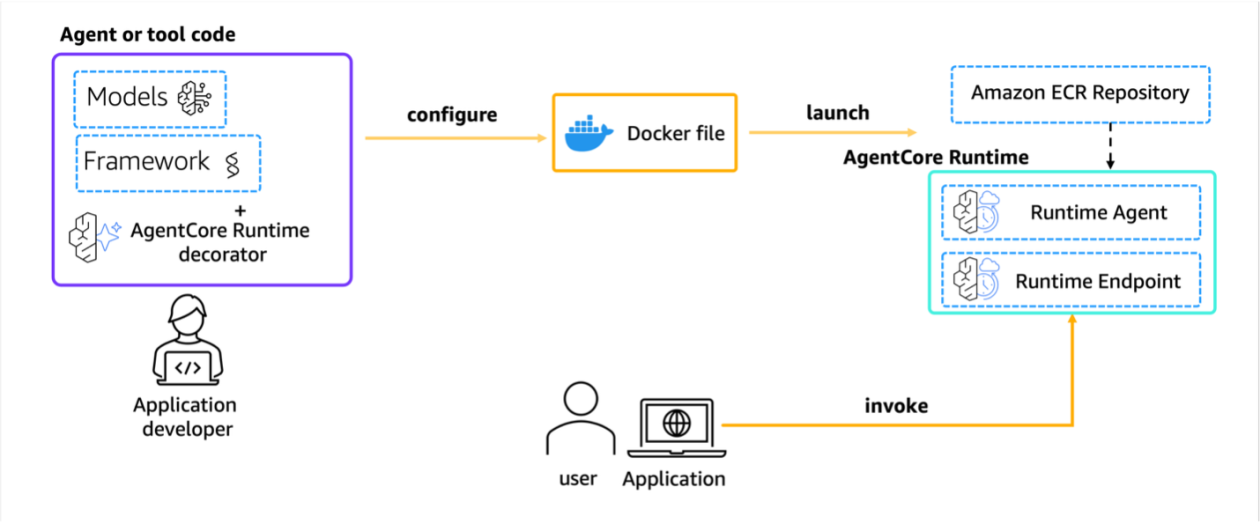
Amazon Bedrock AgentCore Runtime으로 AI 에이전트를 프로토타입에서 프로덕션까지 빠르게 배포하는 방법을 소개했습니다. SDK, Starter Toolkit, FastAPI 예시와 함께 세션 격리, 프로토콜 지원, 운영 포인트를 설명했습니다.
Cursor AI를 활용해 Backend API를 빠르게 구성하는 방법을 소개했습니다. FastAPI와 AWS EC2 예시로 테스트와 피드백을 통한 개선 포인트도 함께 다뤘습니다.

Yappi로 FastAPI 서버의 병목을 찾아 성능을 개선한 사례를 다뤘습니다. JSON 직렬화와 변환 경로를 줄여 CPU 사용률과 응답 시간을 크게 낮췄습니다.
해커톤에서 AI 채용 도우미 AIVA를 만들며 이력서와 과제 분석, 코드 실행 검증까지 실험했습니다. 프롬프트 설계와 캐싱, 토큰 제한을 고민하며 AI 시대 개발자의 자세도 함께 성찰했습니다.

티오더가 Amazon Bedrock과 MCP로 운영 플랫폼을 구축한 사례를 소개했습니다. 자연어 기반 도구 호출과 알람 자동 요약으로 장애 대응과 운영 효율을 높였습니다.

Kubeflow로 추천 시스템의 데이터 수집, 학습, 서빙, 튜닝까지 전체 흐름을 구성한 사례를 소개했습니다. 오프라인 추론 전환과 파이프라인 자동화로 응답 속도와 운영 효율을 개선했습니다.
RAG는 외부 문서를 검색해 LLM 답변에 반영하는 방식으로, 최신성 부족과 환각 문제를 보완했습니다. 실전 적용 시에는 데이터 품질, 검색 성능, 지연 시간, 보안까지 함께 고려해야 했습니다.
Poetry와 UV를 실제로 비교하며 속도와 사용성을 점검했습니다.\nUV는 더 간결했지만 극적인 차이는 아니어서 신규 프로젝트부터 시험 도입하는 접근이 적합했습니다.

UV를 PIP 대체 도구로 소개하며 설치와 기본 사용법, 주요 명령어를 정리했습니다. 가상환경 자동화와 빠른 성능, 의존성 및 Python 버전 관리 기능을 함께 설명했습니다.

FastAPI의 Depends()로 의존성 주입을 적용하는 방법을 설명했습니다. 비즈니스 로직과 구현체를 분리해 유연성과 테스트 용이성을 높이는 구조를 소개했습니다.

FastAPI와 SQLite로 사용자 관리 API를 빠르게 만들고, 모듈화된 구조로 기능을 분리하는 방법을 소개했습니다. 의존성 주입과 예외 처리, 자동 문서화를 활용해 유지 보수성과 프로토타이핑 속도를 높였습니다.

FastAPI 프로젝트에서 service와 router를 분리해 결합도를 낮추는 구조를 소개했습니다. 모듈 독립성과 테스트 용이성을 높여 유지보수성과 확장성을 개선하는 방법을 정리했습니다.

쿠버네티스로 검색추천 시스템을 컨테이너화하고 미디어 에이전트 서비스에 적용한 사례를 소개했습니다. 클러스터 구성, 배포, 모니터링, 운영 이슈 대응까지 함께 정리했습니다.

LLM 기반 대화형 애플리케이션을 위한 자체 프레임워크 Aide 개발 과정을 소개했습니다. 멀티턴 대화와 Workflow 추상화로 복잡성을 줄이고 확장성을 높인 점을 정리했습니다.
