AI 시대의 개발 능력은 검증력으로 결정된다, Flava API Gateway 개발 중 배운 빠른 검증과 로컬 환경 구성 전략
AI 코딩 시대에는 빠른 생성보다 빠른 검증이 더 중요하다고 설명했습니다. 스펙 주도 개발과 로컬 검증 환경으로 에이전트의 실수를 줄인 사례를 공유했습니다.
#OpenAPI#REST API#Git
8600

REST API 태그가 달린 국내 IT 기업 기술 블로그 글을 최신순으로 모았습니다.
20개 표시
AI 코딩 시대에는 빠른 생성보다 빠른 검증이 더 중요하다고 설명했습니다. 스펙 주도 개발과 로컬 검증 환경으로 에이전트의 실수를 줄인 사례를 공유했습니다.
AWS 공간 데이터 관리로 건물 검사 결과를 공간 참조 데이터로 구조화하는 방법을 소개했습니다. 이미지와 메타데이터, 추론 결과를 연결해 장기 보존과 재분석 가능성을 높였습니다.

HR SaaS에서는 시간이 급여와 연차 결과를 바꾸는 입력이므로 요청 단위로 교체 가능하게 만들었습니다. Clock 포트와 헤더 기반 Adapter, 비동기 컨텍스트 전파, 환경별 활성화로 타임머신을 구현했습니다.
![[코드가 환경을 모르는 구조 4/7] 타임머신 — 시간 축을 교체한다](https://cdn.sanity.io/images/v31psllp/production/6a70f8e2c090762cbd4b1a9d470f573cbc0fc038-1684x1030.png)
도메인에 의존하지 않는 채팅 플랫폼 MessagingHub의 설계와 연동 구조를 소개했습니다. 웹 기반 공통 클라이언트와 정책 분리로 확장성과 이식성을 높였습니다.

AI 네이티브 엔지니어 채용을 위해 기존 코딩 테스트를 재설계한 과정을 소개했습니다. 수강신청 시스템 과제로 동시성·설계·문서화 역량을 평가하는 철학을 설명했습니다.
Confluence 기획서를 기반으로 Jira 티켓을 자동 생성하는 AI 워크플로우 Tasky를 소개했습니다.\nPRD 표준화와 태스크 세분화로 품질을 높이고 준비 시간을 줄인 사례입니다.
Amazon Connect로 고객 응대와 업무 처리를 함께 수행하는 Agentic AI 컨택센터 구축 방안을 소개했습니다. MCP 통합, 보안 제어, 관찰성으로 셀프서비스와 상담원 지원을 함께 운영할 수 있습니다.

비개발 직군도 참여할 수 있는 n8n 기반 업무 자동화 입문 워크숍을 소개했습니다. 구글 시트 분석, 이메일 분류 등 실습 중심으로 반복 업무 자동화 방법을 다뤘습니다.
![[2.27/추가모집] 코딩은 몰라도 자동화는 하고 싶어: 비전공자를 위한 n8n AI 워크플로 자동화 입문](https://tech.goorm.io/wp-content/uploads/2026/01/BLOG_thumbnail-1.jpg)
비개발 직군을 위한 n8n 업무 자동화 워크숍을 소개했습니다. 구글 시트 분석과 이메일 분류 실습으로 코딩 없이 워크플로를 설계하는 방법을 다뤘습니다.
Sherpa는 완전 자동화보다 검증 가능한 구조를 우선해 설계했습니다. HTML을 기준 진리로 삼고 단계별 파이프라인과 검증 뷰어로 신뢰성을 높였습니다.
Claude Code를 REST API로 감싸 세션 복원, 스트리밍 분리, MCP 도구 연동 구조를 정리했습니다. 기존 AI SDK 도구를 재사용하면서 웹 환경에서 에이전트를 운영하는 방법을 공유했습니다.
무신사, 29CM, 솔드아웃의 분리된 회원 시스템을 하나의 통합 ID로 연결하는 런치 여정을 소개했습니다.\nFederated Identity, 점진적 롤아웃, 자동화 검증으로 무중단 전환과 안정성을 확보했습니다.
토스페이먼츠가 Open API를 장기 운영 관점에서 설계한 원칙과 지원 체계를 소개했습니다. 개발자 경험, 보안, 내부 표준화를 통해 안정성과 확장성을 함께 확보했습니다.

Jira Automation으로 반복적인 티켓 관리와 필드 입력을 줄이는 방법을 소개했습니다. 트리거, 조건, Smart Value, 웹 요청을 활용한 Slack 알림 사례도 다뤘습니다.
당근페이는 이용내역 개편을 위해 서버 드리븐 UI에서 클라이언트 주도 구조로 전환하고 GraphQL을 도입했습니다. 단계적 마이그레이션과 명확한 스키마 원칙으로 안정성과 확장성을 함께 확보했습니다.
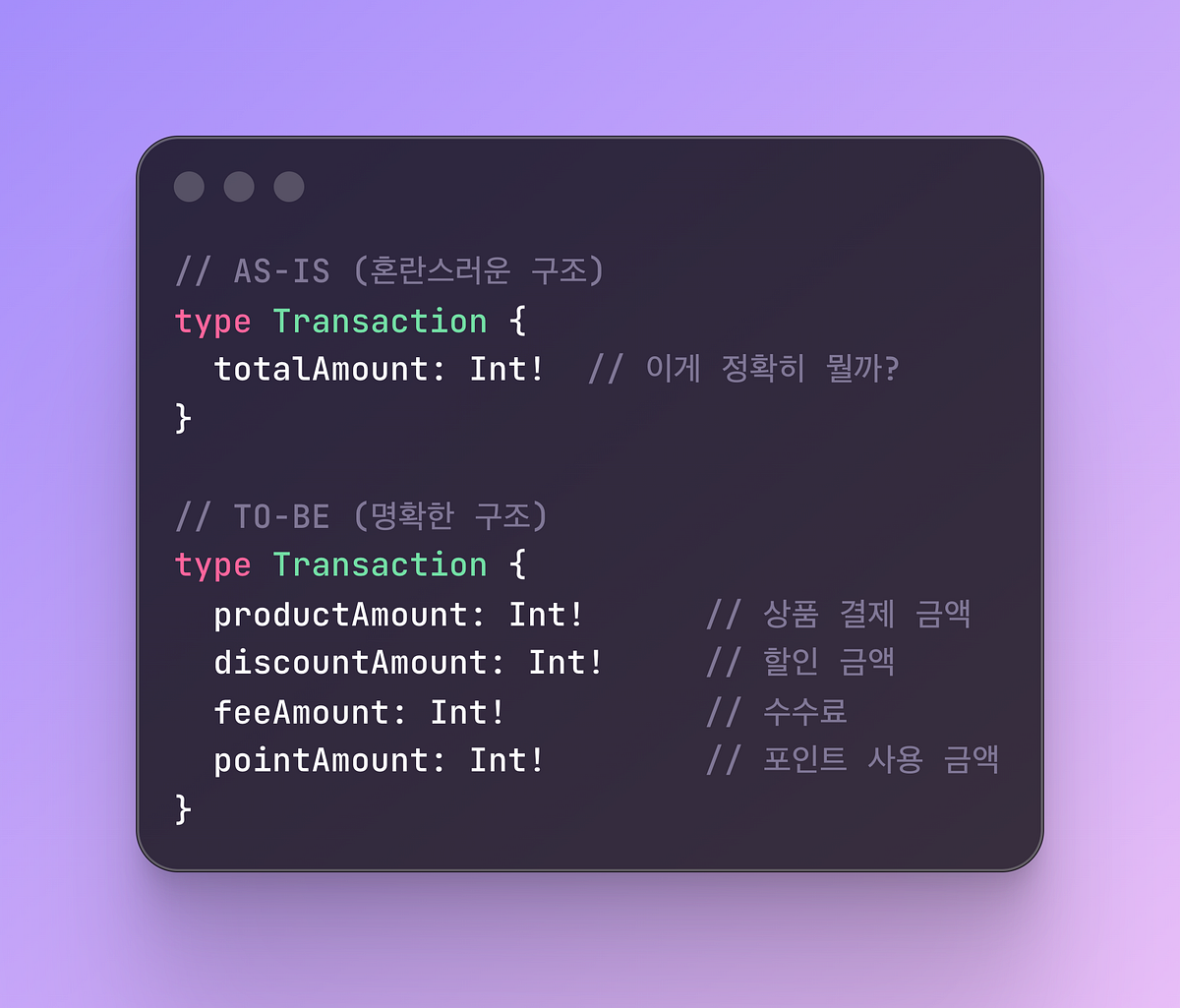
토스페이먼츠가 20년 레거시 결제 시스템을 현대적 아키텍처로 개편한 과정을 소개했습니다. 점진적 전환과 표준화, 자동화로 안정성과 성능을 함께 끌어올렸습니다.

서비스 점검 중 공지만으로 작업을 막기 어려워 애플리케이션 레벨 차단 도구를 만들었습니다. 이후 Redis 캐싱으로 RDBMS 의존성을 줄이며 점검 상황에 대응했습니다.
Claude Code를 자율형 코딩 에이전트로 소개하며 개발 전 과정을 자동화하는 흐름을 설명했습니다. MCP, 터미널 통합, 다중 에이전트로 생산성과 학습 효율을 높이는 활용법도 정리했습니다.

사내 Confluence 문서를 자연어로 찾는 LLM Agent 개발 과정을 소개했습니다. 검색 쿼리 생성, 요약, 캐싱, OCR 등 운영 최적화 포인트도 다뤘습니다.

올리브영이 외부 WMS 의존을 벗어나 GMS를 제로베이스로 구축한 과정을 소개했습니다. Kafka와 Kafka Streams로 Out-of-Order Events를 완화하고 출고 성능과 운영 안정성을 개선했습니다.
