

Amazon EKS에서 NVIDIA OSMO 기반 Physical AI 워크플로 운영하기
Amazon EKS에서 NVIDIA OSMO를 활용한 Physical AI 워크플로 운영 레퍼런스 아키텍처를 소개했습니다. GPU 스케줄링, 아티팩트 보존, 모니터링, 보안을 함께 다루는 방법을 설명했습니다.
#Amazon EKS#NVIDIA OSMO
25005분
Amazon EKS에서 NVIDIA OSMO를 활용한 Physical AI 워크플로 운영 레퍼런스 아키텍처를 소개했습니다. GPU 스케줄링, 아티팩트 보존, 모니터링, 보안을 함께 다루는 방법을 설명했습니다.

MSA 장애 대응의 복잡성을 줄이기 위해 RCA 에이전트 SentryOn을 도입한 과정을 소개했습니다. 도메인 지식, 데이터 정제, Skill 분리, 프롬프트 캐싱으로 정확도와 효율을 높였습니다.
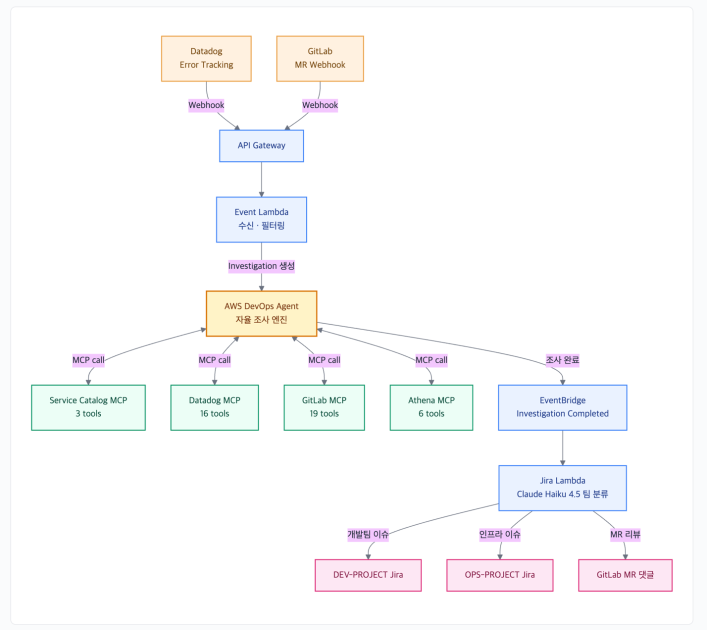
HYBE는 AWS DevOps Agent와 Custom MCP 서버로 인시던트 조사와 Jira 생성을 자동화했습니다. 서비스 카탈로그와 Skill을 더해 분산된 도구와 이름 불일치 문제를 해결했습니다.

딜라이트룸은 EKS Auto Mode로 멀티 클러스터 운영 복잡도를 크게 줄였습니다. 또한 로그 수집과 진단 자동화를 더해 장애 대응력도 높였습니다.

EKS + ALB 환경에서 Blue/Green과 기본 Canary의 Promote 시 503이 발생하는 원인을 분석했습니다. Argo Rollouts Canary PingPong으로 selector 변경 없이 weight만 교대해 문제를 해결했습니다.

GS리테일이 Amazon Bedrock과 MCP로 AIOps Agent를 구축해 인시던트 분석을 자동화했습니다. 평균 분석 시간을 약 30분에서 약 2분으로 줄이고 RCA 보고서와 Teams 알림까지 자동화했습니다.
Job 워크로드는 중단에 취약해 EKS 노드그룹 오토스케일링이 어려웠습니다. 이를 해결하기 위해 PodAffinity로 bin-packing을 유도하고, 애노테이션으로 축소 중 종료를 막았습니다.
Job 워크로드를 위한 EKS Node Group 오토스케일링 적용 과정을 정리한 글입니다. Bin-packing과 강제 종료 방지, kubelet maxPods 조정까지 함께 다뤘습니다.

EKS 애플리케이션 로그를 Athena와 Amazon Bedrock으로 자동 분석하는 파이프라인을 구축했습니다. 수작업 로그 분석을 줄이고 장애 원인과 패턴을 빠르게 파악하도록 구성했습니다.

EKS 장애를 자동 감지해 AWS DevOps Agent 조사로 연결하는 Operator 활용법을 소개했습니다.\n로그와 이벤트를 즉시 수집해 MTTR을 줄이고, Runbook과 GitHub 연동으로 원인 분석을 고도화했습니다.
여기어때는 Secrethub를 EKS 환경에 먼저 적용하고 ESO로 Secret을 자동 동기화하도록 설계했습니다. Spring Boot 공통 Loader와 Shadow Jar를 통해 전사 확산과 의존성 충돌 방지를 함께 해결했습니다.
민감 정보가 서비스별로 흩어져 있던 한계를 해결하기 위해 중앙 관리 플랫폼 Secrethub를 구축했습니다. 접근 통제와 감사, 권한 일원화, 개발 편의성을 위해 외부 솔루션 대신 자체 개발을 선택했습니다.