

티로의 Amazon Bedrock과 RDS를 활용한 대화 기록 기반 Ask Tiro 구현
Amazon Bedrock과 RDS for PostgreSQL로 대화 기록 기반 질의응답 기능을 구현한 사례를 소개했습니다. 의도 분석, 벡터 검색, 답변 생성 흐름으로 정확도와 다국어 대응을 높였습니다.
#Amazon Bedrock#Amazon RDS
60005분
Amazon Bedrock과 RDS for PostgreSQL로 대화 기록 기반 질의응답 기능을 구현한 사례를 소개했습니다. 의도 분석, 벡터 검색, 답변 생성 흐름으로 정확도와 다국어 대응을 높였습니다.

Arize Phoenix로 Bedrock 멀티 에이전트의 실행 경로를 통합 추적하고 평가하는 방법을 소개했습니다. 지연시간, 토큰, 비용, MCP 동작까지 함께 관측해 디버깅과 최적화를 돕습니다.


엔터프라이즈 AI 에이전트는 전통적인 LLM 평가만으로는 충분히 측정하기 어려웠습니다. NEXA는 LLM-as-a-Judge로 도구 정확성과 효율성을 평가하는 방식을 적용했습니다.
엔터프라이즈 AI 에이전트는 전통적 LLM 평가만으로는 성능 측정이 어려워 전용 평가가 필요했습니다. NEXA는 Langfuse의 LLM-as-a-Judge로 도구 정확성과 효율성을 함께 평가했습니다.


Context Engineering을 LLM 성능을 높이는 핵심 역량으로 정리하고 Prompt Engineering과의 차이를 설명했습니다. Cursor AI와 Claude Code 사례를 통해 실무 적용 방식과 컨텍스트 관리 방법을 소개했습니다.


사람인 내부 데이터를 활용해 LLM 챗봇을 구축하고, RAG와 Function Calling으로 답변 정확도를 높였습니다. 또한 LangGraph와 멀티테넌시, 모니터링으로 운영성과 확장성을 함께 개선했습니다.

멀티턴 RAG에서 맥락 손실로 생기는 검색 오류를 쿼리 재작성으로 줄이는 방법을 다뤘습니다. Step-Back, HyDE, Multi-Query와 적응형 라우팅으로 품질과 속도를 함께 조정했습니다.

YouTube 댓글의 정보 과부하를 RAG로 해결하는 분석 시스템을 LangGraph와 Qdrant로 구현했습니다.댓글 수집, 의미 검색, 응답 생성을 분리하고 MVP 한계와 개선점까지 정리했습니다.

Amazon Bedrock 기반 AI Agent 솔루션 에이블의 AWS Marketplace 등록 소식입니다. 별도 설치 없이 클라우드에서 AI 에이전트를 생성·운영할 수 있고, 기업 데이터 벡터화와 지식 검색 기능을 제공합니다.


요기요는 사내 AI 챗봇 ‘조리’로 반복적인 IT/HR 문의와 일부 업무를 자동화했습니다. Slack 기반 멀티에이전트 구조와 외부 시스템 연동으로 응답과 액션을 함께 처리했습니다.
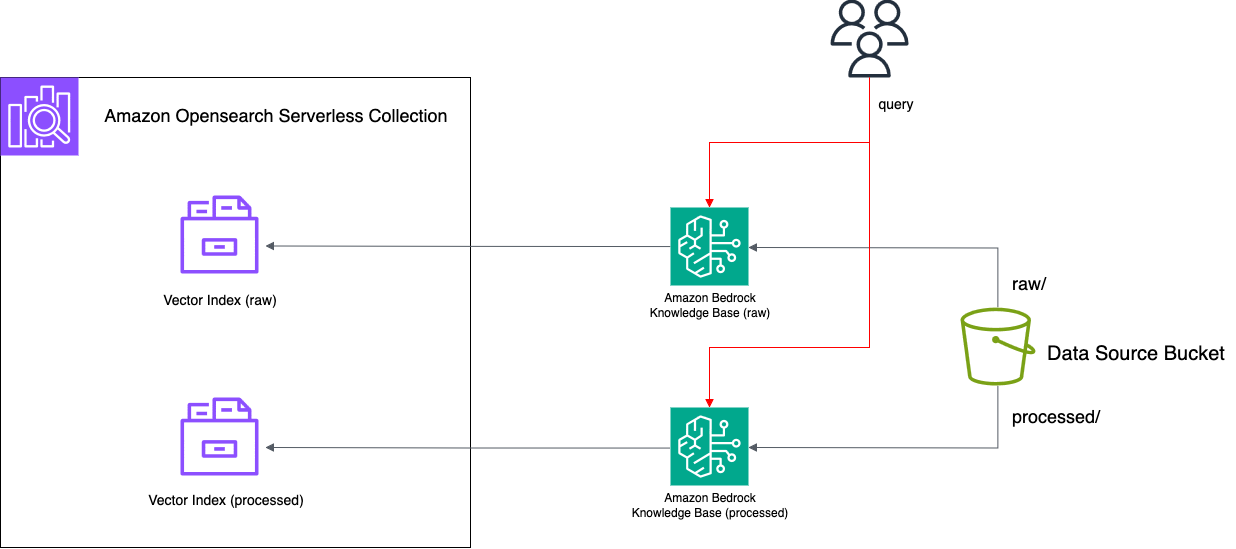
FAQ 같은 짧은 구조화 데이터는 일반 청킹보다 No Chunking이 더 적합했습니다.\nCSV와 메타데이터를 활용해 검색 정확도와 검증 편의성을 높이는 방법을 소개했습니다.

Text2SQL이 왜 어려운지 명시적·암묵적 맥락, 사용자 의도, SQL 방언 차이 관점에서 정리했습니다. ERP 데이터 시각화 Agent 맥락에서 실무적으로 고려할 점도 함께 짚었습니다.