AI
Amazon Bedrock Knowledge Bases: 데이터 특성을 고려한 분할 전략으로 검색 성능 최적화하기

두줄요약
FAQ 같은 짧은 구조화 데이터는 일반 청킹보다 No Chunking이 더 적합했습니다.\nCSV와 메타데이터를 활용해 검색 정확도와 검증 편의성을 높이는 방법을 소개했습니다.
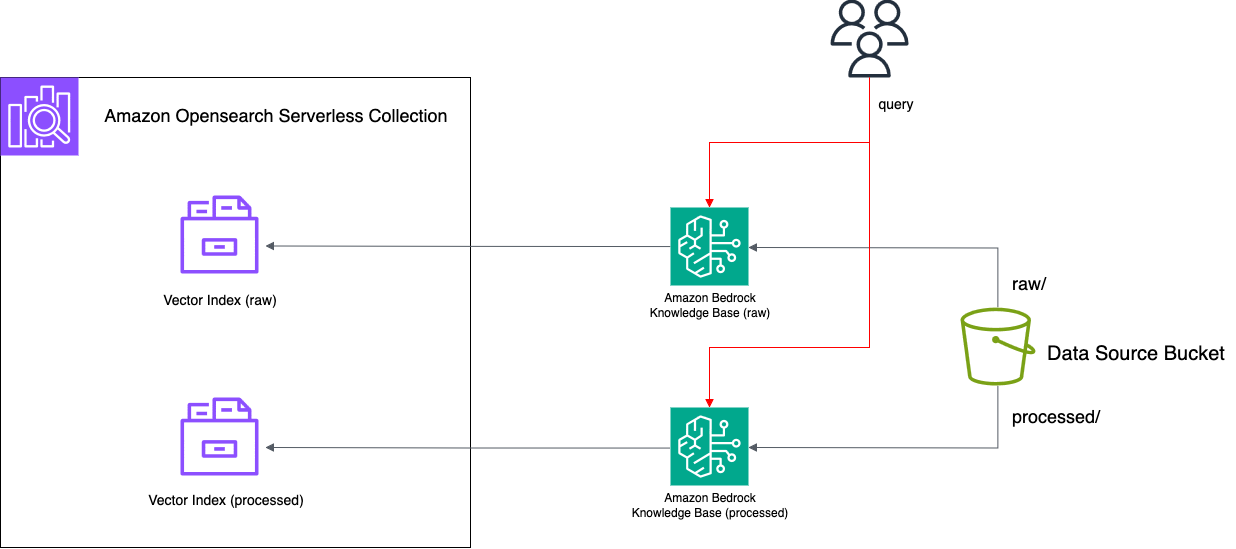
문제 상황
- FAQ, 팁, 짧은 가이드라인처럼 이미 구조화된 짧은 텍스트를 일반 청킹으로 나누면서 맥락 손실 발생
- 질문과 답변이 서로 다른 청크로 분리되거나, 서로 다른 레코드가 한 청크에 섞여 검색 정확도 저하
- 중복 청크 처리로 토큰 효율성 저하와 저장 구조 확인의 어려움
해결 방법
- CSV와 metadata.json을 활용해 레코드 기반 구조로 재구성
- contentFields를 지정하고 No Chunking을 적용해 각 행을 하나의 청크로 유지
- 메타데이터 필드로 service, question, answer 등을 포함해 필터링과 맥락 검색 강화
적용해볼 점
- FAQ, Q&A, 짧은 정책 문서에는 No Chunking + 구조화 메타데이터 검토
- OpenSearch Dashboard로 인덱스 저장 상태와 청크 구성을 직접 확인
- 데이터 특성에 맞춰 청킹 전략을 분리해 검색 품질과 디버깅 용이성 개선