Apache Iceberg 테이블 운영 실전기: 스냅샷 관리부터 Compaction까지
Iceberg 운영에서 스냅샷 폭증과 Small File 문제를 어떻게 다뤘는지 정리했습니다. 작업 이력 관리와 메인터넌스 정책으로 비용과 성능을 개선한 사례입니다.
#Apache Iceberg#Airflow#Spark
000
Apache Iceberg 테이블 운영 실전기: 스냅샷 관리부터 Compaction까지
Apache Iceberg 태그가 달린 국내 IT 기업 기술 블로그 글을 최신순으로 모았습니다.
14개 표시
Iceberg 운영에서 스냅샷 폭증과 Small File 문제를 어떻게 다뤘는지 정리했습니다. 작업 이력 관리와 메인터넌스 정책으로 비용과 성능을 개선한 사례입니다.
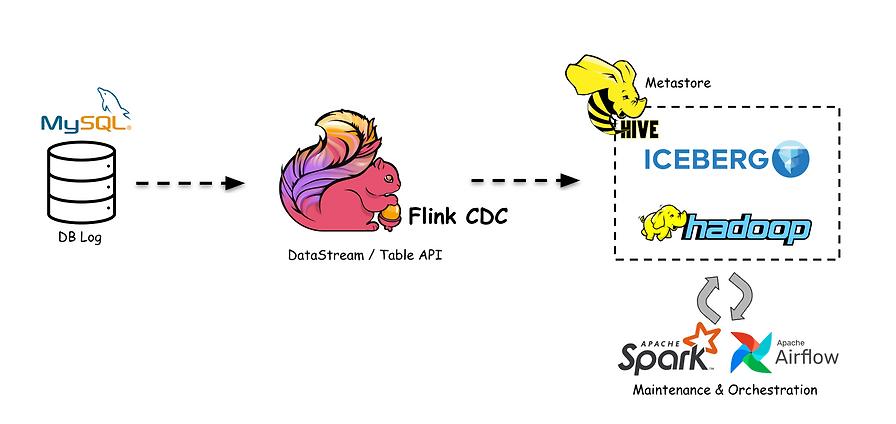
Hive 기반 전체 재작성 ETL의 한계를 Iceberg와 Flink로 개선한 사례를 소개했습니다. 체크포인트, 2PC, 파티셔닝 최적화로 데이터 반영 속도를 12배 높였습니다.

전수 적재의 지연과 정합성 문제를 해결하기 위해 CDC 기반 증분 복제 파이프라인을 설계했습니다. 전체 로우 해시와 사후 검증으로 멱등성과 신뢰도를 높이고, 시간 단위 배치로 최신성을 개선했습니다.
DynamoDB+S3 이중 저장을 Iceberg 단일 테이블로 통합해 비용을 약 91.5% 절감했습니다. 조회 성능과 서빙 안정성도 함께 개선하고, 컴팩션과 조회의 균형 중요성을 정리했습니다.
80TB 이중 저장 구조를 S3 기반 Iceberg 단일 테이블로 통합해 비용을 1/10로 낮추는 과정을 정리했습니다. Rowgroup, 버켓, 컴팩션, 파티션 조합으로 조회 파일 수를 크게 줄였습니다.
Redshift 단일 클러스터의 적재 지연과 리소스 경합 문제를 해결하기 위해 Iceberg 기반 데이터레이크를 구축했습니다.\nGCS, BigLake Metastore, Spark, BigQuery를 분리해 멀티 엔진 운영과 벤더 종속 완화를 노렸습니다.
Apache Iceberg 테이블 관리 작업 중 발생하는 S3 4xx와 503 SlowDown 이슈를 CloudWatch, Server Access Logging, Athena로 분석했습니다. 요청 분산을 위해 해시 또는 날짜 기반 prefix 설계를 적용하는 방안을 정리했습니다.

AWS Glue로 SAP OData 데이터를 S3 Tables의 Iceberg 테이블에 적재하고 SageMaker Unified Studio와 연계하는 방법을 소개했습니다. 대용량 SAP 데이터를 빠르게 분석하고 통합 활용하는 흐름을 정리했습니다.

DynamoDB 변경 이벤트를 Firehose와 Iceberg S3 Tables로 실시간 복제하는 파이프라인 구성을 소개했습니다. Athena와 QuickSight로 분석 가능한 구조와 권한 설정, 변환 시 주의점까지 정리했습니다.

Amazon S3 Tables의 자동 컴팩션이 작은 파일로 인한 읽기 오버헤드를 줄여 쿼리 성능을 높이는 방법을 소개했습니다. 테스트에서는 스토리지 집약적 워크로드에서 최대 3배 수준의 개선을 보였습니다.

StarRocks의 도입 배경과 내부 구조, 성능 최적화 방법을 정리했습니다.\nELT 전환과 Iceberg 연동, 파티셔닝·버킷팅·정렬 키 설계의 중요성을 설명했습니다.
Elasticsearch 기반 로그 저장 구조의 비용과 확장성 한계를 해결하기 위해 Iceberg 기반 Alaska를 도입했습니다. Kafka 로그를 오브젝트 스토리지에 직접 적재하고, 실시간 조회와 장기 보관을 분리해 운영 효율을 높였습니다.
Amazon S3 Tables의 발표 내용과 서비스팀 확인 사항을 정리한 글입니다. 분석 워크로드 성능 향상, 자동 유지보수, 비용과 한계를 함께 살펴보았습니다.

Apache Iceberg와 Flink CDC를 다루는 심층 탐구 글입니다. 발췌만으로는 구체적 내용 확인이 어려워 핵심 주제만 요약했습니다.