장시간 비동기 작업, Kafka 대신 RDB 기반 Task Queue로 해결하기

장시간 비동기 작업, Kafka 대신 RDB 기반 Task Queue로 해결하기
장시간 엑셀 생성 작업에서 Kafka Consumer 타임아웃으로 중복 발송이 발생했습니다. RDB 기반 Task Queue와 Heartbeat로 재시도와 장애 복구를 안정화했습니다.
#Kafka#RDB
32005분
장시간 엑셀 생성 작업에서 Kafka Consumer 타임아웃으로 중복 발송이 발생했습니다. RDB 기반 Task Queue와 Heartbeat로 재시도와 장애 복구를 안정화했습니다.

DBT와 Airflow로 데이터 계보 중심 파이프라인 Flow.er를 구축한 사례를 소개했습니다. 운영 비용 절감과 조직 확장을 위한 구성 요소와 개선 경험을 공유했습니다.
Kafka Consumer Group Protocol v2를 소개하고 v1의 문제점, v2의 장점과 마이그레이션 포인트를 다뤘습니다.\n서비스 조직에서 Kafka를 사용할 때 참고할 실무 팁을 정리했습니다.

Aurora에서 DELETE 후에도 스토리지 비용이 줄지 않는 원인과 파편화 문제를 설명했습니다. 스냅샷 복구로 클러스터를 재생성해 비용을 크게 절감한 사례를 공유했습니다.

토스는 서비스의 재무적 가치를 플랫폼 관점에서 측정하기 위해 MTVi 지표를 만들었습니다. LTV의 한계를 보완하고, DID와 세그먼트 분석으로 증분 가치를 정량화했습니다.
JVM JIT Compiler 웜업의 기본과 기존 API 호출식 웜업의 부작용을 짚고, 라이브러리만 데우는 방식을 소개했습니다. 구현과 검증을 통해 이점과 한계를 함께 정리했습니다.
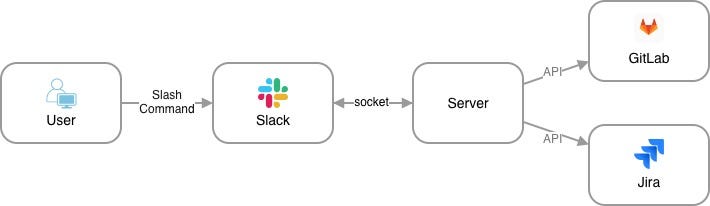

Slack 명령어로 Jira와 GitLab 작업을 묶어 배포 반복 업무를 자동화한 사례를 소개했습니다. 사전 검증과 일괄 머지로 실수를 줄이고 팀 가시성을 높였습니다.


AWS advanced JDBC wrapper의 플러그인 동작과 활용법을 정리했습니다. Aurora 초기 연결 전략과 Failover v2의 차이, 구성 시 주의점을 살펴보았습니다.
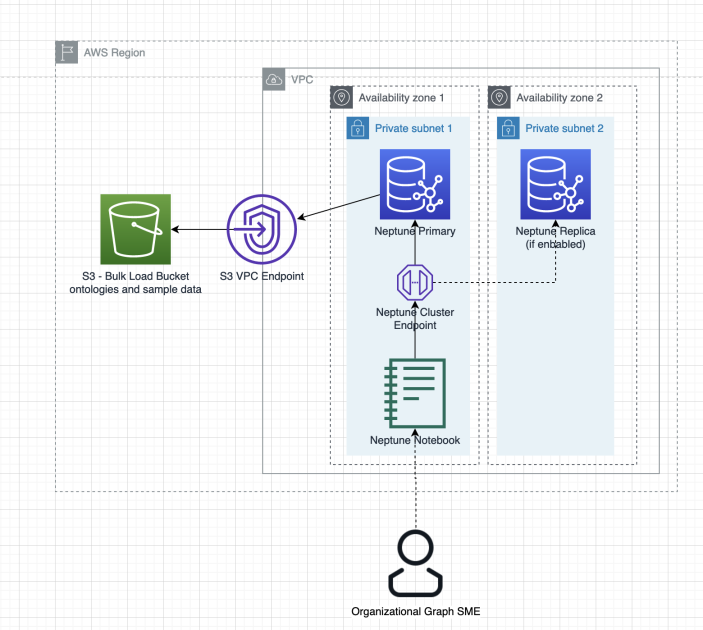
Amazon Neptune에서 OWL 온톨로지를 활용해 지식 그래프 모델을 만들고 검증하는 방법을 소개했습니다. SPARQL과 RDF 패턴을 이용해 인스턴스를 생성하고 규칙 위반을 점검하는 흐름을 설명했습니다.


여기어때는 고객 상담 시스템에 SendBird SDK와 Salesforce를 연동했습니다. 상담 상태 제어와 UI 분기를 위해 채널 metaData를 적극 활용했습니다.


SDUI의 트래픽 병목을 Caffeine과 Redis 이중 캐시로 해결한 사례를 소개했습니다. 백오피스 즉시 무효화와 프리워밍으로 1ms 미만 응답 성능을 확보했습니다.


정산시스템의 대용량 엑셀 출력에서 OOM과 재시도 폭주를 해결한 사례를 다뤘습니다. 날짜 단위 병렬 처리와 DB Cursor, S3 업로드로 메모리 부담 없이 비동기 다운로드 구조를 만들었습니다.