AI
Amazon Bedrock기반에서 Contextual Retrieval 활용한 검색 성능 향상 및 실용적 구성 방안

두줄요약
Amazon Bedrock에서 Contextual Retrieval로 RAG 검색 정확도를 높이는 방법을 설명했습니다. 전처리 컨텍스트 생성, 하이브리드 검색, 리랭킹, 프롬프트 캐싱까지 실무 구성을 함께 다뤘습니다.
핵심 내용
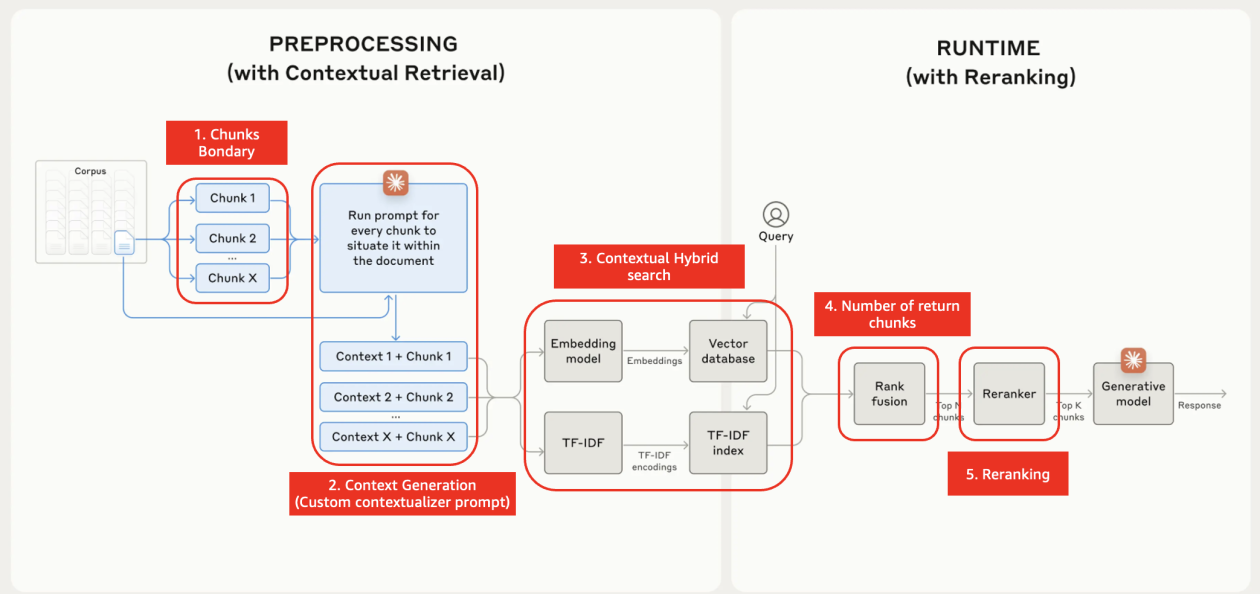
- Amazon Bedrock 기반에서 RAG 검색 성능을 높이기 위한 Contextual Retrieval 개념 정리
- 청크에 문서 전체 맥락을 덧붙여 검색 정확도를 개선하는 situated context와 chunk prepending 소개
- 전처리 단계의 컨텍스트 생성, 런타임의 하이브리드 검색과 리랭킹을 조합한 구성 설명
- 슬라이드 윈도우, parent-document, 청크 크기 조정, 프롬프트 캐싱 등 실무 고려사항 정리
적용해볼 점
- 복잡한 질문이 많은 RAG 환경에서 Contextual Retrieval 우선 검토
- Bedrock Knowledge Base, Titan 임베딩, Claude Haiku, Reranker 조합으로 구현 검토
- 문서 길이와 토큰 비용을 고려해 청킹 전략과 캐시 적용 여부 판단