LLM은 모델보다 하네스가 먼저다: 만득이 한 달 수습기

LLM은 모델보다 하네스가 먼저다: 만득이 한 달 수습기
업무용 LLM 봇에서는 모델보다 하네스가 더 중요하다는 점을 정리했습니다. 범위 설정, 근거 분리, 도구 실패 구분이 실제 운영 품질을 좌우했습니다.
#LLM#Claude
124005분
업무용 LLM 봇에서는 모델보다 하네스가 더 중요하다는 점을 정리했습니다. 범위 설정, 근거 분리, 도구 실패 구분이 실제 운영 품질을 좌우했습니다.


Claude Code의 CLAUDE.md를 토큰 효율 중심으로 관리하는 방법을 정리했습니다. 컨텍스트 부패를 줄이기 위해 핵심 규칙만 남기고 Hook과 Skills로 분리하는 전략을 제안했습니다.
![[AI가 읽을 수 있는 코드베이스 4/5] Acceptance 증명이 리뷰를 바꾼다](https://cdn.sanity.io/images/v31psllp/production/6705c41b0f4dc43d0e1f65c9a632db8d0f8246c7-1684x1030.png)

PR 리뷰의 첫 질문인 동작 확인을 E2E와 데모 녹화로 자동화했습니다. 그 결과 리뷰어가 설계와 구조 검증에 더 집중하도록 전환했습니다.
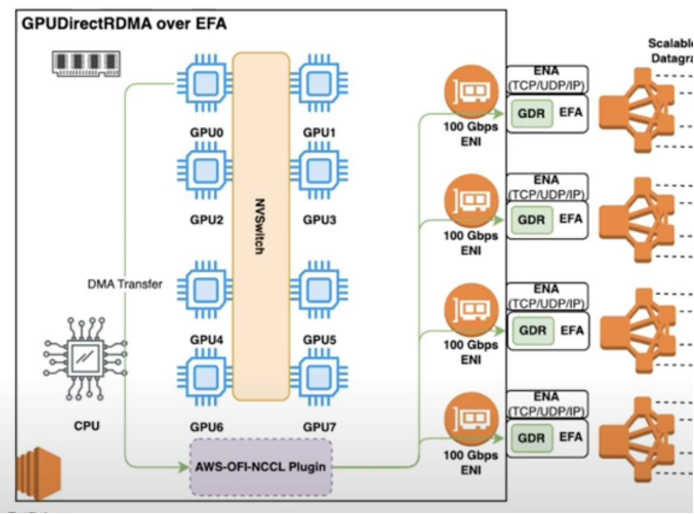

AWS 분산 트레이닝에서 GPU 간 통신 기술의 발전과 최적화 방향을 정리했습니다.\nMoE와 Dense 모델에 따라 NCCL, NVSHMEM, PPLX-kernels의 선택 기준을 설명했습니다.

Strands Agents와 AgentCore로 RDS for SQL Server 진단 스크립트를 에이전트화하는 방법을 소개했습니다. Deadlock과 Blocking을 조사하고 SNS 보고까지 자동화하는 흐름을 설명했습니다.
Slack 봇 창식이를 통해 하네스 엔지니어링과 컨텍스트/피드백 루프 설계를 실제 운영에 적용한 사례를 정리했습니다. MCP 채널, 지식 베이스, 교정 로그로 장기 작업의 정확도를 높인 구성이 핵심입니다.


LLM은 정답을 맞히는 능력만큼, 모를 때 멈추는 능력도 중요하다고 정리했습니다. 모델 크기나 추론 강화만으로는 부족해, 별도의 평가와 정렬 설계가 필요했습니다.

vLLM Tensor Parallelism으로 G5/G6의 24GB GPU 여러 장에 LLM을 분산 서빙하는 방법을 설명했습니다. 벤치마크에서 TP=4는 응답 속도와 처리량을 크게 개선했으며, 비용 효율적인 대안으로 제시했습니다.
중고 의류 디테일컷 자동 생성을 위해 VLM 대신 Detector와 규칙 기반 크롭을 선택했습니다.\n그 결과 공정 시간을 90% 줄이고 11만 개 상품에 일괄 적용했습니다.

GraphRAG Toolkit으로 지식 그래프를 쿼리하는 전략을 설명했습니다. 벡터 검색의 한계를 보완하기 위해 그래프 탐색과 retriever 선택 기준을 정리했습니다.
![[AI가 읽을 수 있는 코드베이스 2/5] 빌드 피드백이 AI를 가르친다](https://flex.team/blog/og/main.jpg)
AI 코딩 에이전트가 받는 빌드 피드백을 유형별로 비교하며 정보 품질 차이를 분석했습니다. 가장 중요한 규칙은 컴파일 타임에 강제하고, 에러 메시지와 테스트 실패를 더 명확하게 설계해야 한다고 정리했습니다.

여기어때가 디자인 시스템에 맞는 아이콘을 빠르게 만들기 위해 생성기와 벡터화 파이프라인을 구축했습니다. 실무에 바로 쓰이도록 프롬프트, 정제, UX까지 함께 최적화했습니다.