AI
분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – 분산 트레이닝을 위해 알아야 할 GPU 간 고속 통신 기술

두줄요약
AWS 분산 트레이닝에서 GPU 간 통신 기술의 발전과 최적화 방향을 정리했습니다.\nMoE와 Dense 모델에 따라 NCCL, NVSHMEM, PPLX-kernels의 선택 기준을 설명했습니다.
핵심 내용
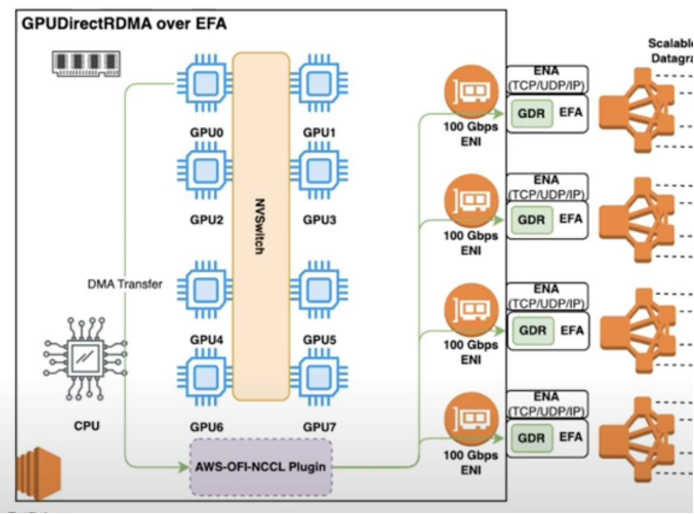
- AWS 분산 트레이닝에서 GPU 간 고속 통신의 발전 흐름 정리
- GPUDirect RDMA로 데이터 경로의 CPU 개입 제거, GPUDirect Async로 제어 경로의 CPU 개입까지 축소
- NVSHMEM, NCCL, GDRCopy, EFA, IBGDA의 역할과 조합 관계 설명
- MoE Expert Parallelism에서 DeepEP와 PPLX-kernels의 EFA/인피니밴드 최적화 차이 비교
구조와 흐름
- 데이터 경로와 제어 경로를 분리해 통신 병목 분석
- 집합 통신과 one-sided 통신의 적합한 사용 구간 구분
- AWS EFA와 인피니밴드의 설계 사상 차이에 따른 최적화 방향 정리
적용해볼 점
- Dense 모델 훈련은 NCCL + EFA 조합 검토
- MoE 서빙과 Expert Parallelism에는 pplx-garden, GDRCopy 활용 검토
- 네트워크 기능보다 환경에 맞는 통신 라이브러리 선택 우선