
대규모 서비스 환경에서의 이미지 콘텐츠 모더레이션(feat. 멀티모달 LLM)
대규모 서비스의 이미지 콘텐츠 모더레이션을 위해 멀티모달 LLM과 전통적 ML을 결합한 구조를 소개했습니다. 정확도, 지연 시간, 비용, 정책 유연성을 함께 개선하는 최적화 과정을 다뤘습니다.
#LLM#멀티모달
41005분
대규모 서비스의 이미지 콘텐츠 모더레이션을 위해 멀티모달 LLM과 전통적 ML을 결합한 구조를 소개했습니다. 정확도, 지연 시간, 비용, 정책 유연성을 함께 개선하는 최적화 과정을 다뤘습니다.


TwelveLabs Marengo 3.0의 멀티모달 비디오 검색 전략을 정리했습니다. 고정 가중치, 순위 기반 융합, 의도 기반 라우팅의 차이와 트레이드오프를 설명했습니다.

Amazon Bedrock의 TwelveLabs Marengo로 비디오를 멀티모달 임베딩으로 변환해 시맨틱 검색을 구현한 사례입니다. OpenSearch Serverless와 결합해 텍스트·이미지·오디오 질의로 관련 클립을 찾는 흐름을 소개했습니다.
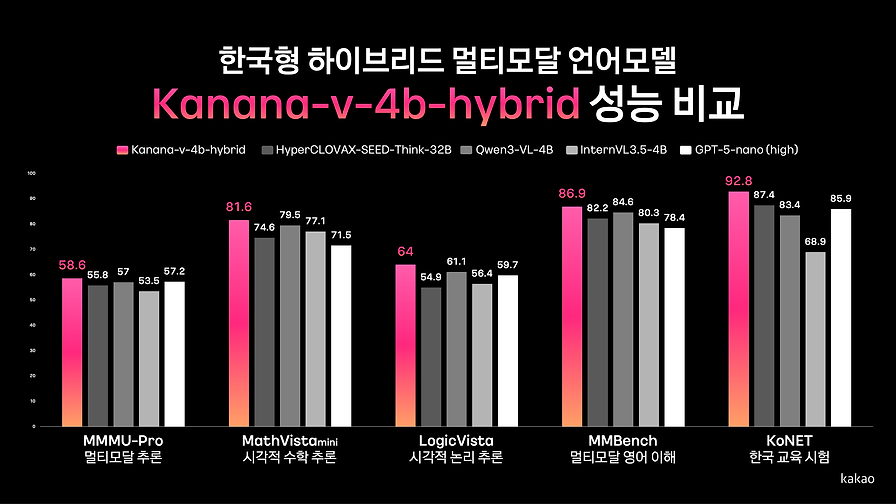

X

한국어 텍스트와 이미지를 함께 처리하는 멀티모달 임베딩 모델 개발기를 소개했습니다. 자연어 기반 사진 검색과 유사 상품 추천 사례를 중심으로 설명했습니다.

X

Amazon Bedrock으로 소셜 미디어 콘텐츠를 분석하는 멀티 에이전트 시스템 구축 사례를 소개했습니다. 스트리밍 처리와 브랜드 정규화, 모니터링 체계를 통해 확장성과 운영성을 높였습니다.


미리디는 멀티모달 AI 디자인 품질을 높이기 위해 프롬프트 엔지니어의 역할을 중요하게 보고 있습니다. 프롬프트 설계뿐 아니라 실험, 평가 지표, 협업 역량까지 요구하고 있습니다.

오디오, 이미지, 환경 정보를 결합한 멀티모달 AI로 블랙아이스를 감지하는 솔루션을 소개했습니다. 공공기관 평가에서 정검지율 96.7%를 기록하며 야간·악천후 상황의 한계를 보완했습니다.

GS리테일은 Amazon Bedrock으로 와인 라벨 이미지 검색 서비스를 구축했습니다. Claude와 멀티모달 임베딩, Elasticsearch를 결합해 다국어 라벨 검색 품질을 높였습니다.


CLIP과 BLIP의 구조와 용도를 비교하며 이미지-텍스트 유사도 계산 예시를 정리했습니다. CLIP은 직접 매칭에, BLIP은 캡션 생성 후 의미 비교에 적합했습니다.

Gemma 3n의 멀티모달 온디바이스 특징과 오디오·이미지 입력 예제를 소개했습니다. 다양한 입력 방식을 활용해 오프라인 환경에서도 응용할 수 있음을 보여주었습니다.