

나만의 맞춤법 검사기 만들기: 개발 과정과 노하우 공유
한컴오피스 맞춤법 검사기 자체 개발을 검토한 하이브리드 교정 프로젝트를 소개했습니다. 규칙 기반 교정과 KoBART, 검증 필터로 과교정을 줄이는 과정을 공유했습니다.
#Python#LLM
118005분
한컴오피스 맞춤법 검사기 자체 개발을 검토한 하이브리드 교정 프로젝트를 소개했습니다. 규칙 기반 교정과 KoBART, 검증 필터로 과교정을 줄이는 과정을 공유했습니다.


온디바이스 얼굴 식별 파이프라인의 병목을 정량 분석해 최적화한 사례를 소개했습니다. 연산 흐름 조정과 병렬화로 응답 시간과 처리량을 크게 개선했습니다.
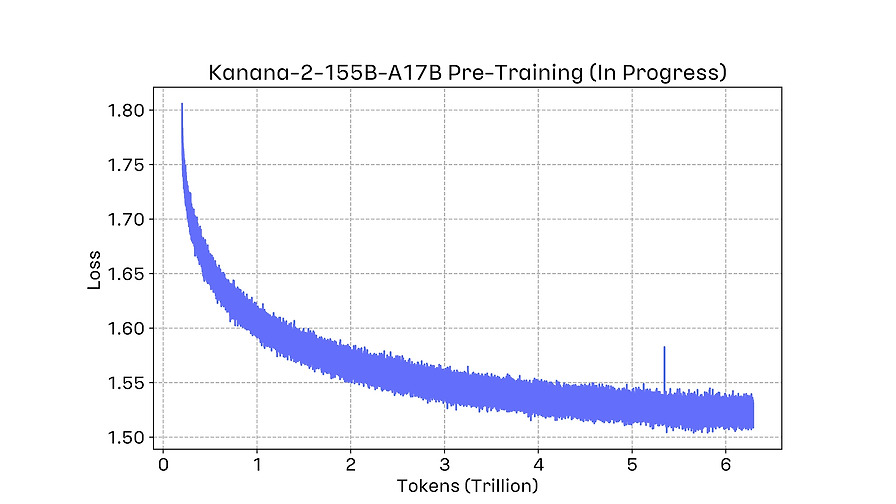

카카오의 차세대 언어모델 Kanana-2의 Pre-training 개발 과정을 의사결정 중심으로 정리한 글입니다. 시리즈의 첫 글로서 이후 post-training 개선 내용으로 이어집니다.
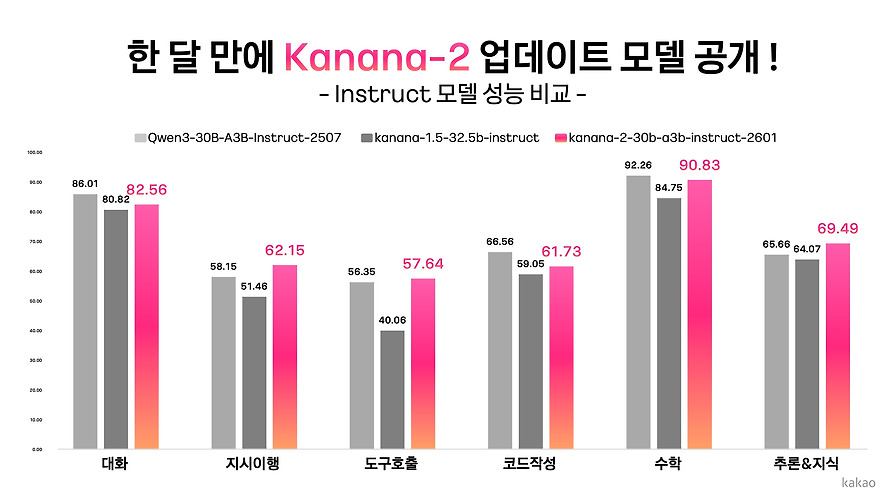
Kanana-2 개발기 시리즈의 두 번째 글로, 개선된 post-training recipe를 다룹니다. 다만 발췌만으로는 구체적 내용은 충분히 확인되지 않습니다.


NeurIPS 2025에서 스케일링 이후의 AI 흐름과 동질화, 평가 한계를 살펴보았습니다. XAI와 Causality를 통해 설명과 인과를 구분해 보는 시사점도 정리했습니다.
비즈니스 문제를 AI 문제로 바꾸는 완화 접근과 명시적 가정의 중요성을 설명했습니다. 아자르 추천 시스템 사례로 장기 매출을 대화 시간 예측 문제로 단계적으로 정렬하는 과정을 소개했습니다.

라포랩스가 4050 커머스 멀티채널 전략 강화를 위해 전 직군 경력직 약 50명을 채용했습니다. 합류 인재에게는 최대 2억 원 스톡옵션과 다양한 복지 제도를 제공합니다.
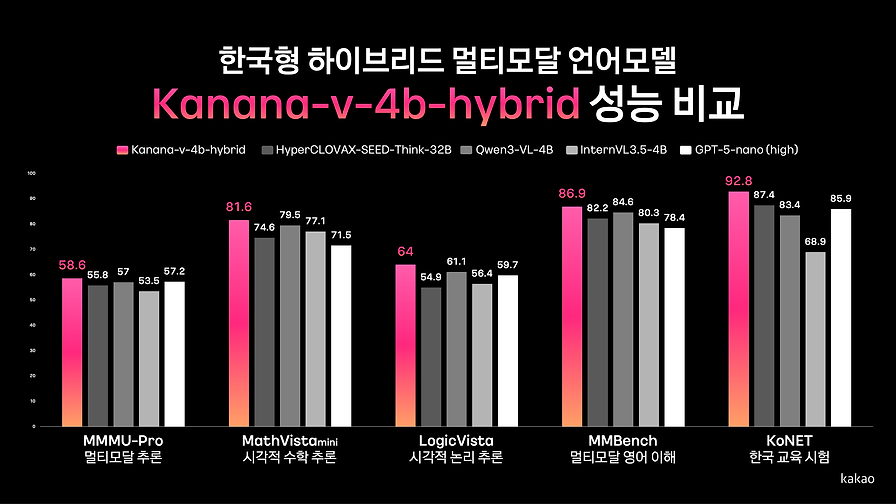
X
![[VOD] re:COMMIT AI 시대, 무엇을 맡기고 무엇을 지켜야 하는가](https://tech.goorm.io/wp-content/uploads/2026/01/REcommit_thumbnail.png)

AI 활용이 자연스러워진 시대에 사고력과 문해력을 어떻게 지킬지 다룬 VOD입니다. 과도한 의존의 문제를 짚고 주체적 사고를 회복하는 훈련법을 소개합니다.

토스가 NeurIPS 2025에 FedLPA 연구를 게재하며 연합학습 기술력을 입증했습니다. 데이터 주권과 불균형 분포 문제를 풀어 글로벌 금융 서비스 적용 가능성을 넓혔습니다.

채널 AI팀이 RAG 검색 성능을 평가하기 위해 자체 리트리벌 벤치마크를 만든 과정을 소개했습니다. 외부 벤치마크 한계를 보완하고 hybrid search 성능 개선도 확인했습니다.
AI 모델 성능 비교를 위해 상담 도메인에 맞는 리트리벌 벤치마크를 직접 제작했습니다. 벡터 검색과 BM25를 결합한 하이브리드 검색의 개선 효과도 정량적으로 확인했습니다.