

데이터카탈로그 PM이 ‘데이터 디스커버리’라는 가치를 풀어내는 방법
데이터카탈로그를 통해 데이터 디스커버리를 검색, 미리보기, 리니지의 3단계로 풀어낸 사례를 소개했습니다. 데이터 찾기뿐 아니라 이해와 신뢰 확보까지 연결하는 방향을 제시했습니다.
#검색#데이터베이스
46005분
데이터카탈로그를 통해 데이터 디스커버리를 검색, 미리보기, 리니지의 3단계로 풀어낸 사례를 소개했습니다. 데이터 찾기뿐 아니라 이해와 신뢰 확보까지 연결하는 방향을 제시했습니다.
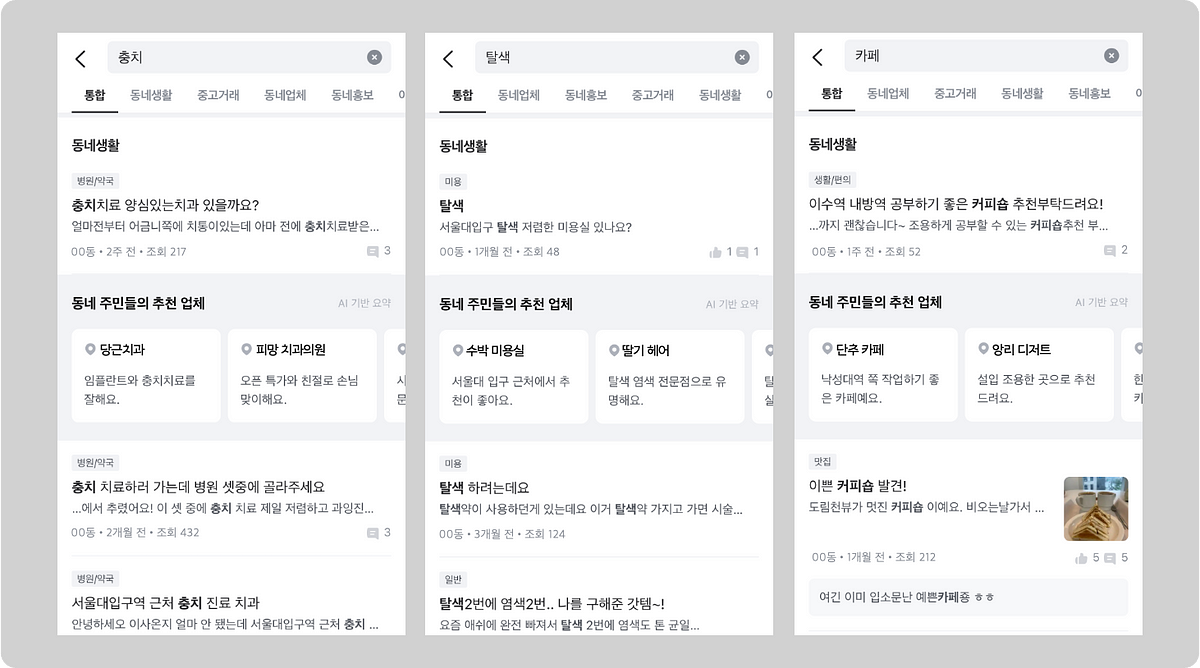
동네생활 게시글과 댓글에서 업체 추천 정보를 찾아 RAG 기반 검색 서비스로 연결했습니다.\n벡터 검색, LLM 요약, 적절성 필터링을 거쳐 신뢰도 높은 추천 결과를 제공했습니다.


여러 LLM의 응답을 계층적으로 결합해 최종 답변 품질을 높이는 MoA 기법을 소개했습니다. 기존 모델을 바꾸지 않고도 성능과 비용 효율성을 동시에 개선할 수 있음을 설명했습니다.

주소정제 서비스에서 단독건물 처리 로직과 주소 파싱 과정을 내재화한 과정을 설명했습니다. 행정구역 변경과 휴먼 에러에 대응하며 외부 호출을 줄이기 위한 안정화 전략도 다뤘습니다.
외부업체 주소정제 의존을 줄이기 위해 지번 요청과 LOW 레벨 주소를 내재화한 과정을 정리했습니다. 변경이력 DB와 백오피스 보정으로 계약 종료까지 안정적으로 마무리했습니다.

카카오모빌리티 사내 AI 해커톤 AI 카모톤의 운영 과정과 수상작 사례를 소개했습니다. 짧은 기간에 AI 도구로 프로토타입을 만들고 교육·심사·회고까지 진행한 행사였습니다.

DAN 24 DEVIEW 세션 영상이 공개되었습니다. 웹 성능 개선, 결제 시스템, AI 추천, 검색, 모델 서빙 주제를 정리해 소개했습니다.

텍스트를 숫자와 벡터로 표현하는 여러 방법과 문장 임베딩 기반 의미 검색을 정리했습니다. 또한 BERT, FAISS, 하이브리드 검색의 구조와 활용 방향을 소개했습니다.
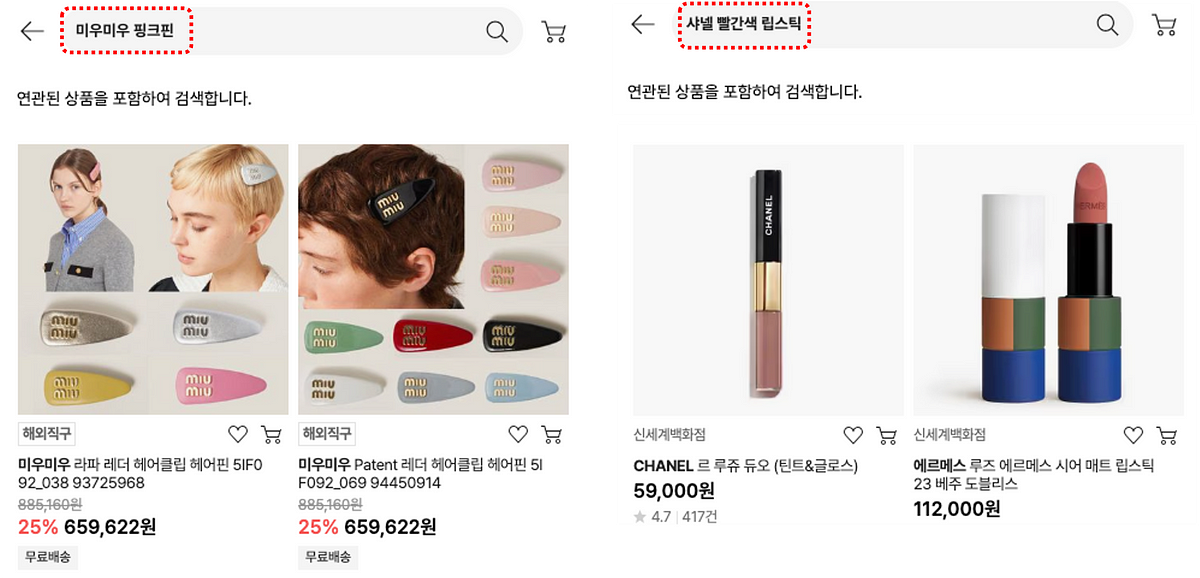

SSG.COM 검색 실패를 줄이기 위해 BERT 계열 모델과 벡터 DB 기반 매칭 방식을 도입했습니다. 적용 후 전체 검색 실패의 46%를 성공으로 전환했고 정확도 75%를 달성했습니다.

ES에 의존하던 LTR 구조를 분리해 rerank API와 model API로 재구성했습니다. gRPC, 응답 압축, 2단계 캐싱으로 성능과 운영 리스크를 함께 개선했습니다.
네이버 홈피드는 검색과 다른 서비스의 사용자 컨텍스트를 함께 활용해 개인화를 강화했습니다. LLM 기반 AiRScout로 관심 주제 추출과 검색 의도 세분화를 수행해 추천 품질을 높였습니다.
검색어와 문서를 함께 고려해 사용자 의도를 세분화하는 LLM 기반 모델을 설계했습니다. 이를 통해 추천의 맥락 정확도를 높이고 CTR도 개선했습니다.