


OpenShift에서의 Security Context Constraints(SCC) 이해하기
OpenShift의 SCC를 클러스터 보안 정책 관점에서 정리했습니다. 파드 생성 흐름, RBAC 연계, Kubernetes의 대체 메커니즘까지 함께 비교했습니다.
#OpenShift#Kubernetes
40005분
새로운 기술 블로그가 추가되었어요
OpenShift의 SCC를 클러스터 보안 정책 관점에서 정리했습니다. 파드 생성 흐름, RBAC 연계, Kubernetes의 대체 메커니즘까지 함께 비교했습니다.


Django REST Framework에서 django-modeltranslation으로 다국어 지원을 구현한 사례를 소개했습니다. DB 기반 번역 관리와 fallback 설정으로 유지 보수성과 사용자 경험을 높였습니다.

Polars는 Pandas와 비슷한 인터페이스를 유지하면서도 Rust 기반 최적화로 대용량 데이터 처리 성능을 높였습니다. Lazy Execution과 멀티코어 활용으로 로컬 환경에서도 빠른 전처리와 분석을 기대할 수 있습니다.
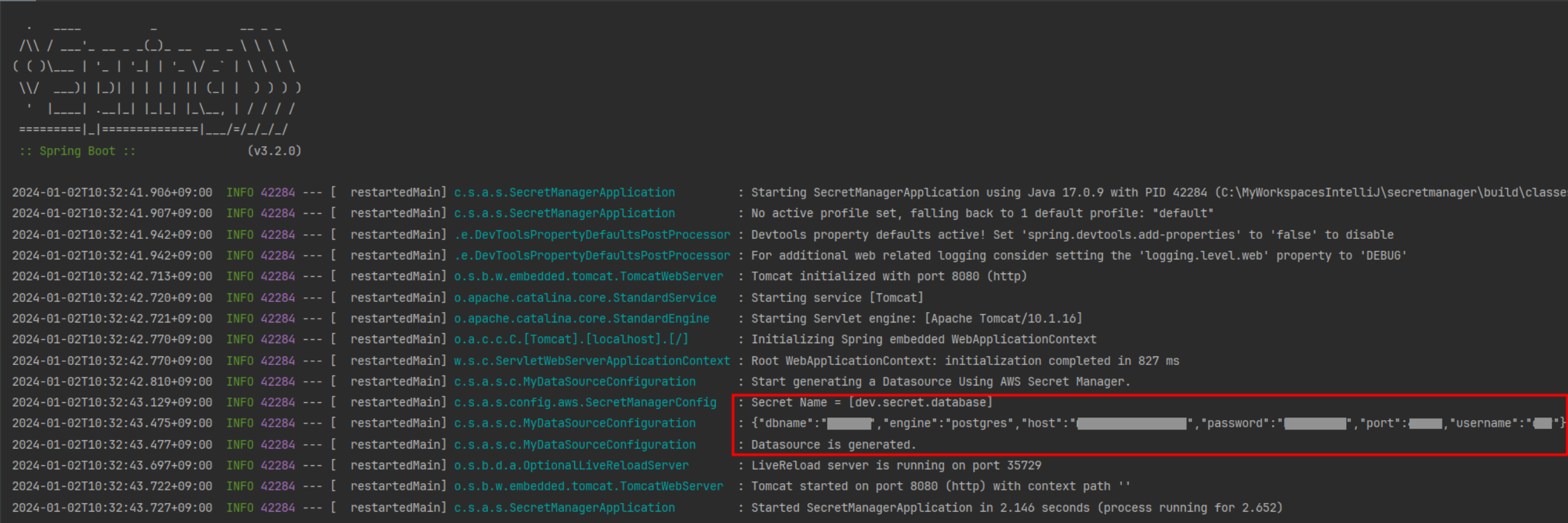

Spring Boot 시작 시 AWS Secrets Manager에서 DB 정보를 조회해 DataSource를 생성하는 방법을 소개했습니다. 자동 설정을 제외하고 Secret JSON을 파싱해 PostgreSQL 연결 정보를 주입하는 예시를 다뤘습니다.


Amazon OpenSearch Service OR1 인스턴스의 내부 구조와 데이터 흐름을 설명했습니다. Amazon S3 기반 원격 저장과 물리 복제로 처리량, 내구성, 복구 효율을 높이는 방식을 다뤘습니다.

Apache Airflow의 설치와 실행이 어렵다는 문제를 Astro CLI로 쉽게 줄이는 방법을 소개했습니다. 단 몇 개의 명령어와 템플릿, 테스트 도구로 로컬 개발 환경을 빠르게 구성할 수 있었습니다.

SSL 트러블슈팅에 자주 쓰는 openssl 명령어들을 한눈에 정리했습니다. 인증서 확인, 키 검증, 포맷 변환, 추출과 암복호화 예시까지 담았습니다.

약관 서버의 DB 부하를 줄이기 위해 Redis 캐시와 강한 일관성 전략을 적용했습니다. 캐시 무효화 실패와 이벤트 순서 문제는 트랜잭션 동기화와 정책으로 해결했습니다.

OpenAPI 3.0 스펙을 설계 우선 관점에서 작성하는 원칙과 주의점을 정리했습니다. 보안, 스키마 재사용, 예제, 코드 생성을 통해 API 계약 품질을 높이는 방법을 소개했습니다.
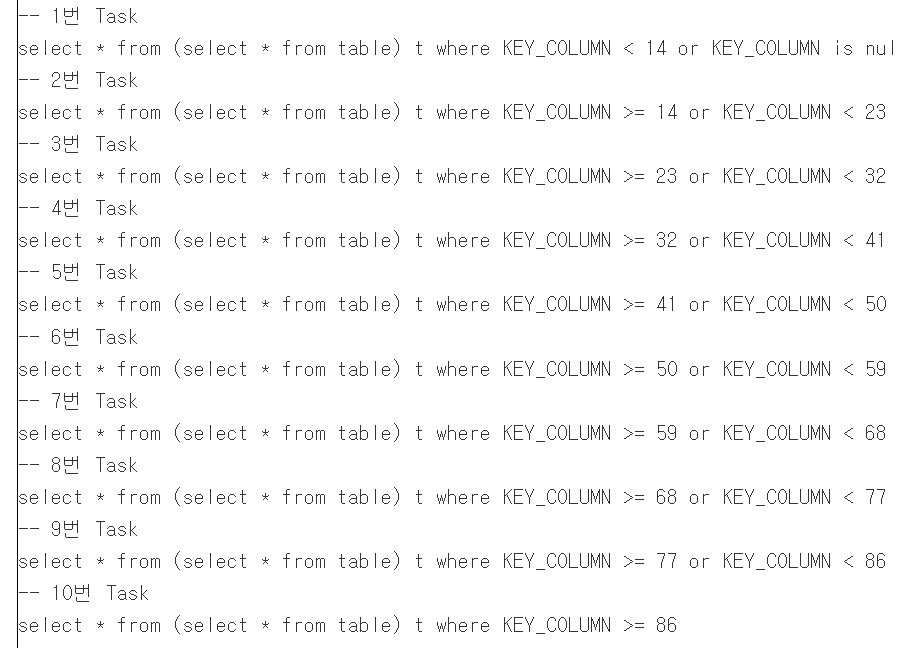
Spark JDBC 병렬처리의 기본 사용법과 파티션 분할 방식의 주의점을 설명했습니다. 소수점 버림으로 인한 skew를 줄이기 위해 upperBound 설정과 컬럼 분포 점검이 필요했습니다.

Spark에서 Rest API 데이터를 수집하는 두 가지 방법을 비교했습니다. 단순 requests 방식과 Spark UDF 방식의 장단점 및 대량 데이터 처리 시 고려점을 설명했습니다.
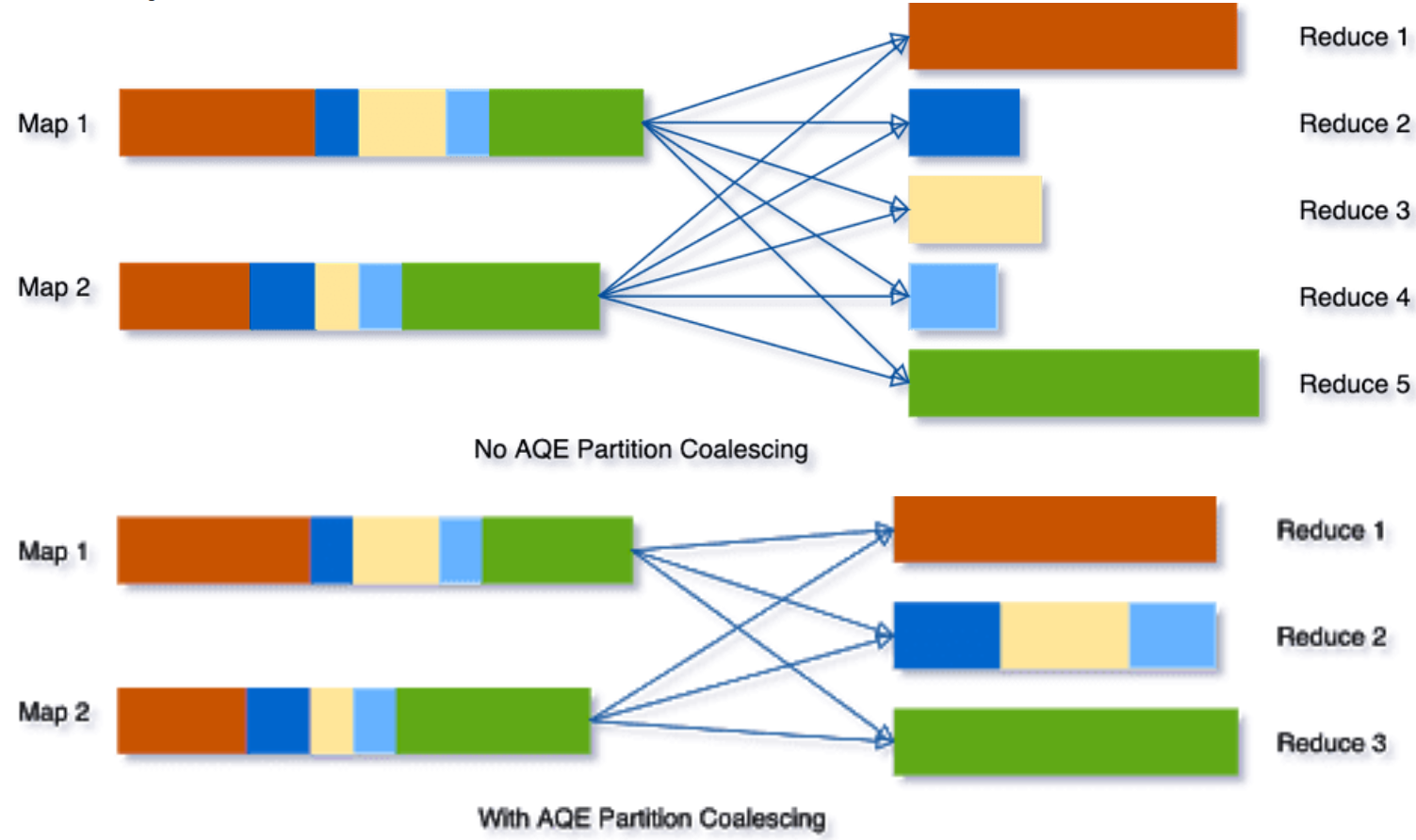
Spark 3.0의 AQE와 coalescePartitions로 셔플 파티션을 동적으로 최적화하는 내용을 소개했습니다. 셔플 파티션 크기에 따른 성능 저하 문제와 파티션 병합 방식도 설명했습니다.