

SDUI의 성능 병목을 넘어: 올리브영 로컬 캐시 기반 백엔드 최적화 성공기
SDUI의 트래픽 병목을 Caffeine과 Redis 이중 캐시로 해결한 사례를 소개했습니다. 백오피스 즉시 무효화와 프리워밍으로 1ms 미만 응답 성능을 확보했습니다.
#Kotlin#Spring Boot
232005분
SDUI의 트래픽 병목을 Caffeine과 Redis 이중 캐시로 해결한 사례를 소개했습니다. 백오피스 즉시 무효화와 프리워밍으로 1ms 미만 응답 성능을 확보했습니다.


정산시스템의 대용량 엑셀 출력에서 OOM과 재시도 폭주를 해결한 사례를 다뤘습니다. 날짜 단위 병렬 처리와 DB Cursor, S3 업로드로 메모리 부담 없이 비동기 다운로드 구조를 만들었습니다.
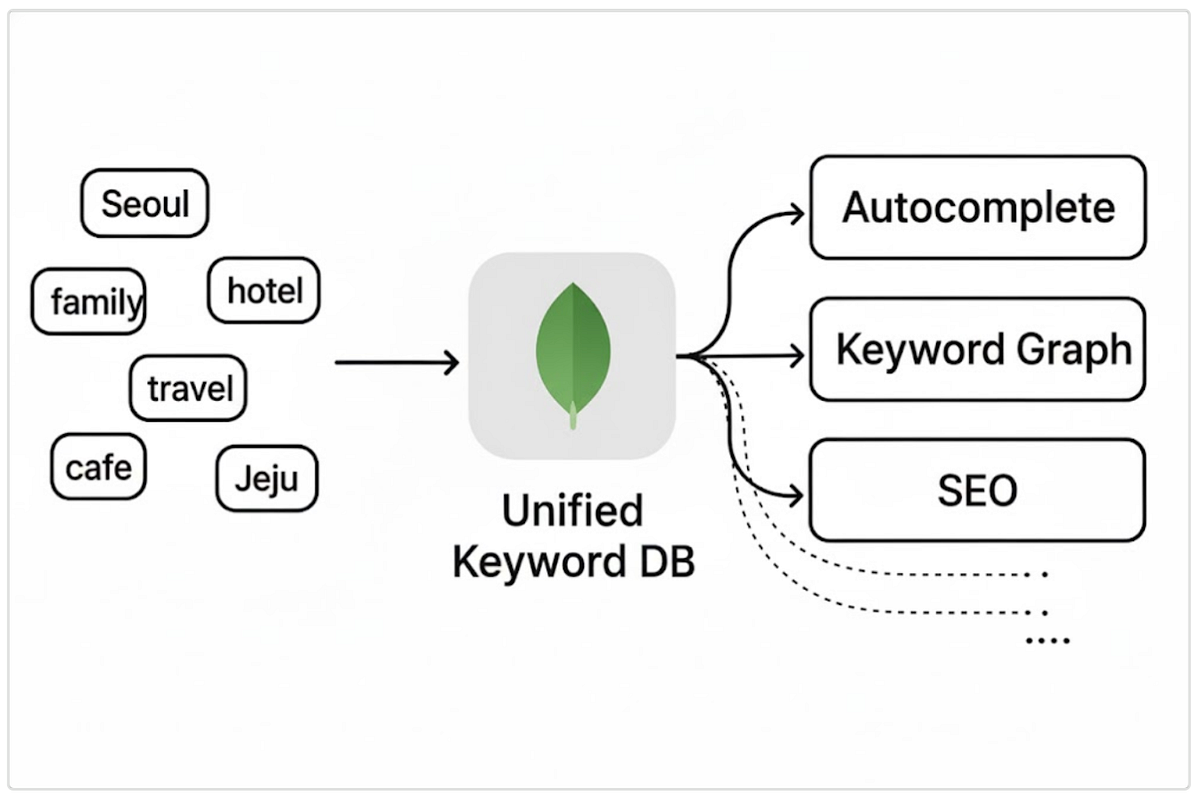

여기어때가 분산된 검색 키워드 데이터를 MongoDB 기반 단일 허브로 통합한 사례를 소개했습니다. 데이터 관리 일관성과 자동완성 구조 단순화를 통해 확장성을 높였습니다.


백엔드팀이 MSA 전환과 기술 고도화를 통해 빠르게 성장하는 서비스를 안정적으로 운영하는 과정을 소개했습니다. 검색 캐시 개선, DB 전환, 실시간 처리 최적화로 확장성과 성능을 함께 높였습니다.

카카오뱅크가 펀드 시스템 구축 과정에서 사내 Spring Boot Starter barcelona를 개발한 사례를 소개했습니다. FixedLength 전문, HTTP Client, 분산 트레이싱을 추상화해 생산성과 일관성을 높였습니다.
29CM QE팀이 QA 데일리 리포트를 Slack Bot으로 자동화한 사례를 소개했습니다. Jira와 TestRail 연동, 입력 검증, 비동기 처리로 효율과 안정성을 높였습니다.


Kafka 소비 결과를 Parquet으로 변환해 S3에 적재하는 실시간 수집 파이프라인을 설계하고 구축했습니다. 또한 Flush, 커밋, 모니터링 체계를 통해 누락 없이 안정적으로 운영하는 방법을 정리했습니다.

`equals`를 일부 속성만으로 정의하면 예상치 못한 버그가 생길 수 있음을 설명했습니다. 동일성인지 등가성인지 목적을 먼저 정하고, 필요한 부분은 별도 함수로 분리해야 합니다.

검색 광고의 랭킹 부스트 기능을 설계하고, 노출 수 예측 대신 순위 상승 보장 방식으로 전환했습니다.\n데이터 수집, Delta Score 계산, Elasticsearch 가중치 주입과 A/B 테스트 검증 과정을 정리했습니다.

7,000줄 PL/SQL 프로시저에 얽힌 교환·반품 로직을 Java 모듈로 점진 이관한 사례를 소개했습니다. Strangler Pattern과 Fallback, 모니터링 강화로 유지보수성과 확장성을 확보했습니다.

여러 MSA의 공통 설정 변경을 재배포 없이 반영하기 위해 Spring Cloud Config와 Bus-Refresh를 도입했습니다. 그 결과 배포 시간이 크게 줄고 운영 중 설정 변경 대응이 쉬워졌습니다.

`@CacheEvict(allEntries = true)`가 내부적으로 어떻게 동작하는지 Spring Cache와 Redis 구현 레벨에서 살펴보았습니다. 기본 `KEYS` 전략이 운영 환경에서 위험할 수 있어 대안도 함께 정리했습니다.