

Accelerating Coupang’s AI Journey with LLMs
쿠팡이 LLM을 활용해 이미지·텍스트 이해, 약한 라벨 생성, 상품 분류를 개선하는 사례를 소개했습니다. 또한 CJK 언어 특성과 ICL·RAG·SFT·CPT, Kubernetes 기반 훈련 흐름을 함께 설명했습니다.
#LLM#ML
34005분
쿠팡이 LLM을 활용해 이미지·텍스트 이해, 약한 라벨 생성, 상품 분류를 개선하는 사례를 소개했습니다. 또한 CJK 언어 특성과 ICL·RAG·SFT·CPT, Kubernetes 기반 훈련 흐름을 함께 설명했습니다.

고성능 GPU 클러스터에서 발생하는 통신 비용과 병목 구간을 하드웨어 관점에서 정리했습니다. 스토리지, 서버 내 GPU, 서버 간 통신에 맞춰 NVMe SSD, NVLink, NVSwitch, InfiniBand 선택을 제안했습니다.
무신사 2.0에서 시나리오 기반 설명 가능한 추천 시스템을 구축한 사례를 소개했습니다. 장기·단기 행동을 함께 반영해 개인화와 다양성을 높이고, A/B 테스트와 모니터링으로 운영했습니다.
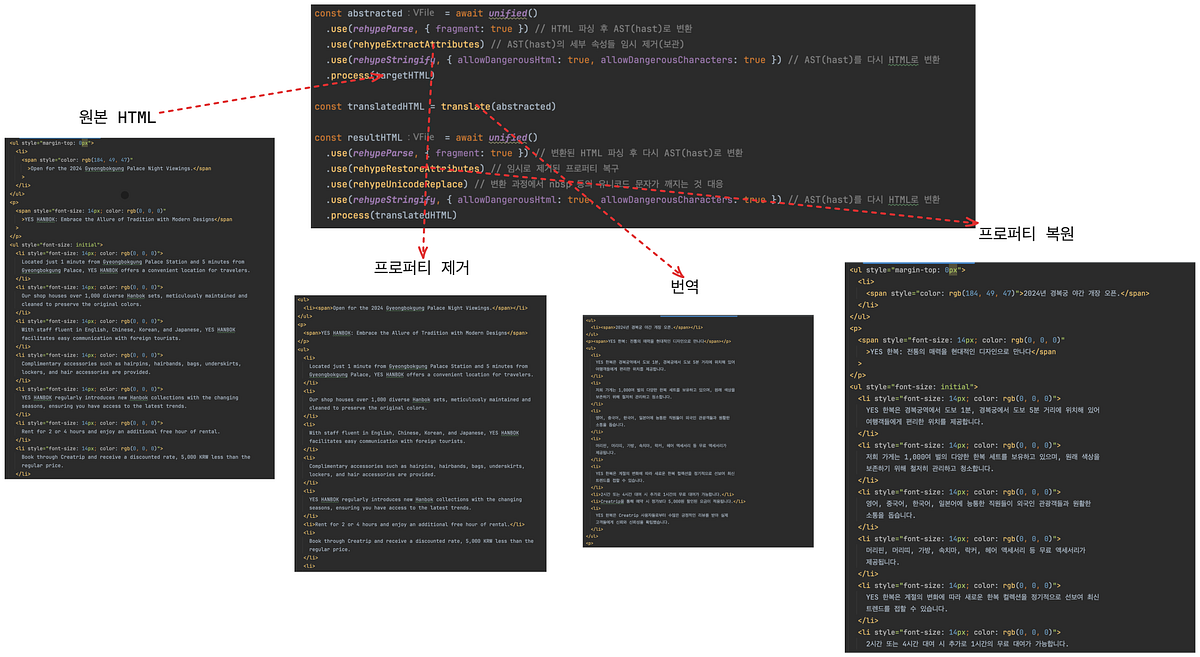

HTML 번역 전에 unified와 rehype로 속성을 분리해 LLM 입력을 최소화했습니다. 그 결과 토큰을 약 40% 줄이고 번역 오류 위험도 낮췄습니다.


RoPE 기반 LLM의 context length를 늘리는 Position Interpolation 방법을 소개했습니다. 제한 범위를 넘어갈 때의 attention score 폭발을 줄이고, 적은 finetuning으로 성능을 유지한 결과를 다뤘습니다.

LLM 기반 대화형 애플리케이션을 위한 자체 프레임워크 Aide 개발 과정을 소개했습니다. 멀티턴 대화와 Workflow 추상화로 복잡성을 줄이고 확장성을 높인 점을 정리했습니다.

Responsible AI의 개념과 핵심 원칙을 정리하고, ISO 42001과 주요 테크 기업의 적용 사례를 소개했습니다. AI의 윤리성과 투명성을 높이기 위한 관리 체계의 중요성을 설명했습니다.

LLM 발전으로 검색 서비스가 어떻게 바뀌고 있는지 주요 서비스 사례를 중심으로 정리했습니다. 에이닷 멀티 LLM 에이전트에서 Perplexity와 다른 모델을 함께 쓰는 방식도 소개했습니다.

삼성 리서치와 Team Atlanta가 DARPA AIxCC에 참가해 생성형 AI 기반 사이버 추론 시스템을 다뤘습니다. 본문은 오류 화면 때문에 상세 내용 확인이 어려웠습니다.

생성형 AI를 다루기 위한 LLM 원리와 프롬프트 엔지니어링의 핵심을 정리했습니다. 랭체인, RAG, ReAct 같은 확장 방법으로 더 지능적인 애플리케이션을 만드는 방향도 소개했습니다.

에이닷 홈 에이전트에 function call을 도입해 음식점·카페 추천 기능을 강화한 사례를 다뤘습니다. 사용자 발화와 실시간 API를 연결해 맥락 기반 추천을 제공하기 위해 프롬프팅과 fine-tuning을 반복했습니다.

안드로이드에서 Gemma 1과 Gemma 2를 On-Device로 실행하는 방법을 정리했습니다. MediaPipe와 MLC LLM의 설정 절차, 모델 실행 방식, 장점도 함께 소개했습니다.