unified + rehype 를 사용하여 경제적인 LLM번역 프로세스 구축하기

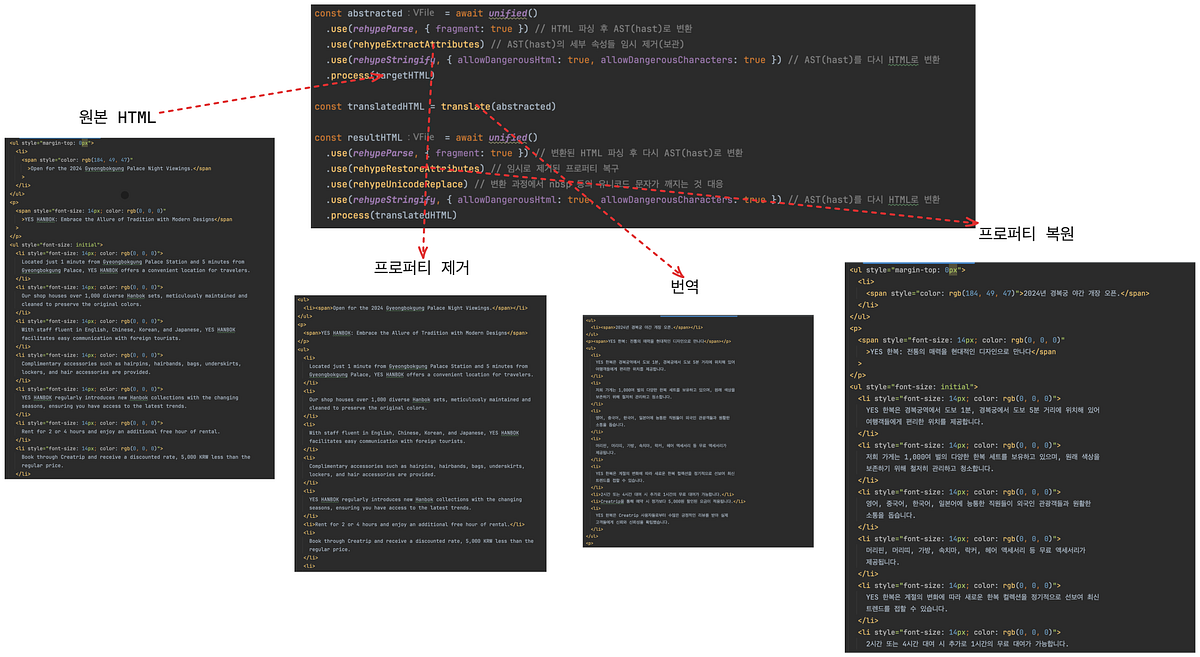
Open in app Sign up Sign in Write Sign up Sign in creatrip · Creatrip 기술 블로그입니다. unified + rehype 를 사용하여 경제적인 LLM번역 프로세스 구축하기 creatrip-jonghak · Subscribe Published in creatrip · 13 min read · Oct 10, 2024 -- Share 안녕하세요. 크리에이트립(Creatrip) FE 개발자 서종학입니다. 저는 공통 스쿼드에서 FE 업무뿐만 아니라 프로덕트 전반의 프로세스 개선에도 적극적으로 참여하여 운영 효율화와 비용 절감을 위해 노력하고 있는데요, 오늘은 그 업무 중 하나인 AI 번역 프로세스의 효율화에 관해 이야기해 보려고 해요. 배경 웹 콘텐츠는 글로벌한 독자층을 위해 다양한 언어로 제공되는 것이 중요해요. 특히 블로그와 같은 형태의 콘텐츠는 현지화가 잘 되어 있을수록 독자의 유입과 전환율이 높아지는데요, 저희 크리에이트립은 한국의 문화를 알리기 위한 여러 블로그 글을 14개 어권의 언어로 번역하여 제공하고 있어요. AI 번역 프로세스의 도입과 문제 기존에는 배포되는 블로그 컨텐츠의 내용을 콘텐츠 담당자분들이 WYSIWYG 에디터로 작성하고 직접 번역/검수 하는 방식을 사용했어요. 하지만 최근 LLM의 발달과 AI 번역 결과물의 자연스러움을 통해 크리에이트립은 점진적으로 LLM을 사용한 번역 프로세스를 구축해 나갔습니다. 이를 통해 한 어권의 담당자가 작성한 글을 빠르게 다른 어권의 언어로 번역해서 제공할 수 있게 되었어요. LLM을 사용한 AI 번역 프로세스는 콘텐츠 담당자분들의 리소스를 줄여주는 장점이 있었지만, 동시에 몇 가지 문제점도 갖고 있었어요. 첫째, HTML 형식의 콘텐츠를 번역하는 과정에서 LLM의 환각 현상으로 인한 태그 누락이나 속성값 손실과 같은 문제가 가끔 발생했어요. 둘째, HTML 자체를 번역에 사용하다 보니 단순 텍스트 번역에 비해 더 많은 토큰이 사용되었고, 이는 높은 비용과 사용량 제한의 문제로 이어졌어요. 이러한 문제들을 해결하기 위해, ‘번역에 필요한 최소한의 정보를 LLM에 전달하는 전처리 단계’ 가 필요하게 되었습니다. 전처리를 위한 기술 검토: unfied와 rehype unified unified는 다양한 도구와 플러그인들이 모여 있는 생태계로, 마크다운, HTML 등 여러 형식을 파싱하고 변환할 수 있는 강력한 환경을 제공해요. unified 생태계는 다양한 플러그인을 통해 텍스트를 구조화하고 변환하며, 다른 형식으로 출력하는 과정을 유연하고 효율적으로 수행할 수 있게 지원하는데요, 입력된 텍스트를 추상적인 구문 트리(Abstract Syntax Tree)로 변환한 후 다양한 조작을 통해 원하는 형태로 데이터를 가공할 수 있도록 인터페이스를 제공해요. 이를테면, 마크다운 문서를 HTML로 변환하거나, HTML에서 특정 요소를 제거하고자 할 때 unified 생태계의 인터페이스로 만들어진 유용한 플러그인과 도구를 사용할 수 있어요. 이를 통해 개발자들은 더 직관적이고 효율적으로 작업을 수행할 수 있어요. 또한 이미 unified 생태계 내부에 갖춰진 다양한 플러그인은 사용자의 필요에 맞게 쉽게 커스터마이즈 할 수 있는 직관적인 API를 제공하고 있어요. rehype rehype는 unified 생태계의 중요한 구성 요소 중 하나로, HTML 파싱 및 처리를 위한 플러그인 집합이에요. rehype를 사용하면 HTML 문자열을 파싱하여 AST로 변환하고, 이를 기반으로 HTML의 내용을 조작하거나 변환하는 작업을 쉽게 수행할 수 있어요. 특정 HTML 태그를 제거하거나 속성을 수정하는 등의 작업을 할 때 유용해요. rehype는 다양한 플러그인과 함께 동작하며 개발자가 원하는 방식으로 HTML을 변환하고 가공할 수 있는데요, 예를 들어 rehype-parse 플러그인은 HTML을 파싱하여 구문 트리로 변환하고, rehype-stringify 플러그인은 구문 트리를 다시 HTML 문자열로 변환합니다. 이런 방식으로 rehype는 HTML을 간소화하거나 특정 요소를 제거/수정하는 작업을 직관적으로 수행할 수 있게 도와주는 도구에요. unified와 rehype를 선택한 이유 LLM을 통한 번역 프로세스의 오류를 줄이고 토큰 비용을 절감하기 위해 HTML을 간소화하는 것이 매우 중요하다고 생각했는데요, 이러한 작업을 효과적으로 수행할 수 있는 도구와 생태계가 바로 unified와 rehype라고 생각했습니다. 직관적이고 유연한 API를 제공하여 사용이 편했을 뿐만 아니라, 풍부한 생태계에 이미 갖춰진 다양한 플러그인을 통해 원하는 작업을 빠르게 구현할 수 있다고 생각했어요. 코드의 간결성과 유지보수성이 향상되며, 필요시 쉽게 확장할 수 있는 장점도 있었습니다. 이러한 이유로 AI 번역 프로세스의 전처리 단계 구축을 위해 unified와 rehype를 선택하게 되었어요. PoC 구상했던 전처리 프로세스 흐름은 다음과 같았는데요, 본격적인 전처리 프로세스를 구현하기 전에 의도한 동작에 대한 검증을 빠르게 해볼 필요가 있었어요. 저장된 HTML 콘텐츠를 추상 구문 트리로 파싱 트리를 순회하며 불필요 속성값 추출 HTML 문자열로 변환 LLM을 사용한 콘텐츠 번역 번역된 HTML 콘텐츠를 추상 구문 트리로 파싱 트리를 순회하며 추출한 속성값 복원 HTML 문자열로 변환 구현 로컬 환경에서 작은 프로젝트를 하나 만들어서 검증을 시도해 봤어요. 먼저 필요한 의존성을 추가해 줍니다. $ pnpm add unified rehype-parse rehype-stringify unist-util-visit 그다음 PoC를 위한 간단한 테스트 파일 하나를 만들어줬어요. import fs from "node:fs" import path from "node:path" import { unified } from 'unified' import rehypeParse from 'rehype-parse' import rehypeStringify from 'rehype-stringify' import { rehypeExtractAttributes, rehypeRestoreAttributes } from "./lib/rehypeAbstract.js" import { rehypeUnicodeReplace } from "./lib/rehypeUnicodeReplace.js" const fileName = "sample.html" const targetHTML = fs.readFileSync(path.resolve(fileName), "utf-8") const abstracted = await unified() .use(rehypeParse, { fragment: true }) // HTML 파싱 후 AST(hast)로 변환 .use(rehypeExtractAttributes) // AST(hast)의 세부 속성들 임시 제거(보관) .use(rehypeStringify, { allowDangerousHtml: true, allowDangerousCharacters: true }) // AST(hast)를 다시 HTML로 변환 .process(targetHTML) const translatedHTML = abstracted // TODO: LLM을 사용한 번역 const resultHTML = await unified() .use(rehypeParse, { fragment: true }) // 변환된 HTML 파싱 후 다시 AST(hast)로 변환 .use(rehypeRestoreAttributes) // 임시로 제거된 프로퍼티 복구 .use(rehypeUnicodeReplace) // 변환 과정에서 nbsp 등의 유니코드 문자가 깨지는 것 대응 .use(rehypeStringify, { allowDangerousHtml: true, allowDangerousCharacters: true }) // AST(hast)를 다시 HTML로 변환 .process(translatedHTML) fs.writeFileSync(path.resolve("output-"+fileName), String(resultHTML), "utf8") 이 과정에서 앞서 말했던 트리를 순회하며 불필요한 속성값 추출, 추출한 속성값 복원을 위해 커스텀 플러그인을 두 개 만들어주었어요. rehypeExtractAttributes, rehypeRestoreAttributes import { visit } from "unist-util-visit" const propertiesCache = { current: new Map() } /** * HTML 요소를 순회하면서 properties를 추출해 propertiesCache에 저장한다. */ export function rehypeExtractAttributes(){ let nodeIndex = 0 const saveProperties = (node) => { const { properties } = node propertiesCache.current.set(++nodeIndex, {...properties}) node.properties = {} } return (tree) => { visit(tree, ['element'], (node) => { saveProperties(node) }) } } export function rehypeRestoreAttributes(){ let nodeIndex = 0 const rollbackProperties = (node) => { const properties = propertiesCache.current.get(++nodeIndex) node.properties = properties } return (tree) => { visit(tree, ['element'], (node) => { rollbackProperties(node) }) } } HTML을 rehypeParse 플러그인으로 파싱한 결과물은 hast(Hypertext Abstract Syntax Tree format)라는 자료구조로 반환되는데요, 트리의 구조가 유지된다면 각 트리의 순회 순서 역시 유지되기 때문에 비교적 간단히 HTML Attributes(properties)를 추출하고 또 복원할 수 있었어요. 이 과정에서 non-breaking space에 해당하는 유니코드 문자 \u00a0에 대한 이슈가 있어 replace 처리를 위한 플러그인도 하나 구현해 주었는데요, 직관적인 인터페이스와 API 덕분에 빠르고 간단하게 만들 수 있었어요. 이 과정에서 새삼 unified 생태계의 확장성과 편의성을 다시 체감할 수 있었어요. rehypeUnicodeReplace import { visit } from "unist-util-visit" export function rehypeUnicodeReplace(){ return (tree) => { // 텍스트 노드만을 순회하며 공백 유니코드 문자를 교체한다. visit(tree, ['text'], (node) => { node.value = node.value.replaceAll("\u00a0", " ") }) } } 검증 샘플 블로그 콘텐츠들을 통해 테스트해 본 결과, 원본 HTML의 프로퍼티가 그대로 잘 보관되었다가 LLM 번역 이후 성공적으로 복원되는 것을 알 수 있었습니다. 토큰 절감 효과 오른쪽은 전처리 전의 콘텐츠, 왼쪽은 전처리 이후 LLM에 사용되는 토큰과 문자열의 양이에요. 동일한 콘텐츠에 대해 약 40%(1722/2897 = 0.59)의 토큰 절감 효과가 있었는데요, 이를 통해 비용 절감과 사용량 제한에 대한 개선뿐 아니라 LLM의 환각 등 잠재적인 문제들에 대한 위험성도 줄일 수 있었어요. 마치며 오늘은 LLM 번역 과정에서 HTML 파싱을 통한 전처리 프로세스를 도입하여 보다 경제적이고 안전한 번역 프로세스를 구축하는 내용을 공유해 드렸어요. 최근에는 크리에이트립 내부에 rehype를 사용한 여러 플러그인이 추가되어 HTML로 작성된 블로그 콘텐츠 내의 여러 속성을 안전하고 빠르게 수정할 수 있는 요구사항에도 대응하고 있습니다. (href url의 locale 변경 등) unified 생태계에 있는 여러 플러그인과 도구들을 사용한다면 비단 HTML뿐만 아니라 마크다운, plain text 등 우리 주변에서 자주 다루는 데이터를 쉽게 다룰 수 있고, 이를 통해 다양한 형식의 콘텐츠를 효율적으로 처리하고 최적화할 수 있어요. unified와 rehype에 대해 더 알고 싶거나, 이를 직접 사용해 보고 싶은 분들은 unified 공식 문서와 rehype 플러그인 목록을 참고해 보시면 도움이 될 것 같아요. 긴 글 읽어주셔서 감사합니다. 참고 unified Content as structured data: unified compiles content and provides hundreds of packages to work with content unifiedjs.com GitHub - rehypejs/rehype: HTML processor powered by plugins part of the @unifiedjs collective HTML processor powered by plugins part of the @unifiedjs collective - rehypejs/rehype github.com rehype/doc/plugins.md at main · rehypejs/rehype HTML processor powered by plugins part of the @unifiedjs collective - rehype/doc/plugins.md at main · rehypejs/rehype github.com GitHub - syntax-tree/hast: Hypertext Abstract Syntax Tree format Hypertext Abstract Syntax Tree format. Contribute to syntax-tree/hast development by creating an account on GitHub. github.com 여담으로 텍스트 컨텐츠의 불평등한 표현을 검증하는 오픈소스인 alex 역시 retext 플러그인을 통한 자연어 검증을 기본으로 사용하고 있습니다. (alex는 vercel/next 깃헙 레포지토리에도 적용되어 있습니다) GitHub - get-alex/alex: Catch insensitive, inconsiderate writing Catch insensitive, inconsiderate writing. Contribute to get-alex/alex development by creating an account on GitHub. github.com Unified Rehype WYSIWYG Hast Published in creatrip 13 Followers ·Last published 3 days ago Creatrip 기술 블로그입니다. Subscribe Written by creatrip-jonghak 2 Followers ·4 Following Subscribe No responses yet Help Status About Careers Press Blog Privacy Rules Terms Text to speech