비용, 성능, 안정성을 목표로 한 지능형 로그 파이프라인 도입

비용, 성능, 안정성을 목표로 한 지능형 로그 파이프라인 도입
네이버 Logiss의 로그 파이프라인 운영 문제와 개선 과정을 다뤘습니다. Storm Kafka spout 수정과 멀티 토폴로지 도입으로 비용·성능·안정성을 높이려 했습니다.
#Kafka#Storm
111005분
네이버 Logiss의 로그 파이프라인 운영 문제와 개선 과정을 다뤘습니다. Storm Kafka spout 수정과 멀티 토폴로지 도입으로 비용·성능·안정성을 높이려 했습니다.


품절 조회를 Oracle 함수 중심 구조에서 Kafka Streams 기반 EDA로 전환해 실시간 재고 처리를 개선했습니다. 그 결과 올영세일 기간 Oracle 함수 호출량을 크게 줄이며 서비스 안정성을 높였습니다.

MongoDB 커넥션 풀 사용률이 80%를 넘을 때 실시간 알림이 가도록 모니터링 시스템을 구축했습니다. 이를 통해 이벤트성 트래픽 급증을 사전에 감지하고 풀 설정도 조정했습니다.


약진통상이 Amazon Bedrock 기반 AI 스타일 라이브러리로 의류 검색과 샘플 개발을 고도화했습니다. 멀티 리전 처리와 설정 파일 중앙화로 성능과 운영 효율도 함께 개선했습니다.

레거시 검색 시스템을 OpenSearch 기반 MSA로 분리해 안정성과 운영성을 높였습니다. 대규모 마이그레이션과 문서화, 모니터링 체계를 정비해 향후 AI 검색 확장 기반도 마련했습니다.
자연어 질의에 맞지 않던 기존 검색 구조를 개선하기 위해 하이브리드 인덱스를 설계했습니다. OpenSearch와 임베딩 기반 벡터 검색을 결합해 검색 품질과 운영 효율을 높였습니다.


OpenSearch KNN과 필터 조합에서 결과 누락이 발생한 원인을 쿼리 구조에서 찾았습니다. pre-filtering 기반 Efficient KNN Filtering으로 검색 품질과 지연 시간을 함께 개선했습니다.

올리브영이 SpringCamp 2025에서 물류·재고 시스템 개선 사례를 발표하고 외부 개발자와 소통했습니다. Kafka, Redis, OpenSearch 기반 운영 경험과 커뮤니티 활동을 함께 공유했습니다.


비개발자 5인 팀이 AWS Gen AI로 안면 인식 기반 초개인화 키오스크를 구현해 해커톤 3위를 수상했습니다. 고객 식별, 메뉴 추천, 매출 분석을 Bedrock과 OpenSearch로 연결한 경험을 공유했습니다.
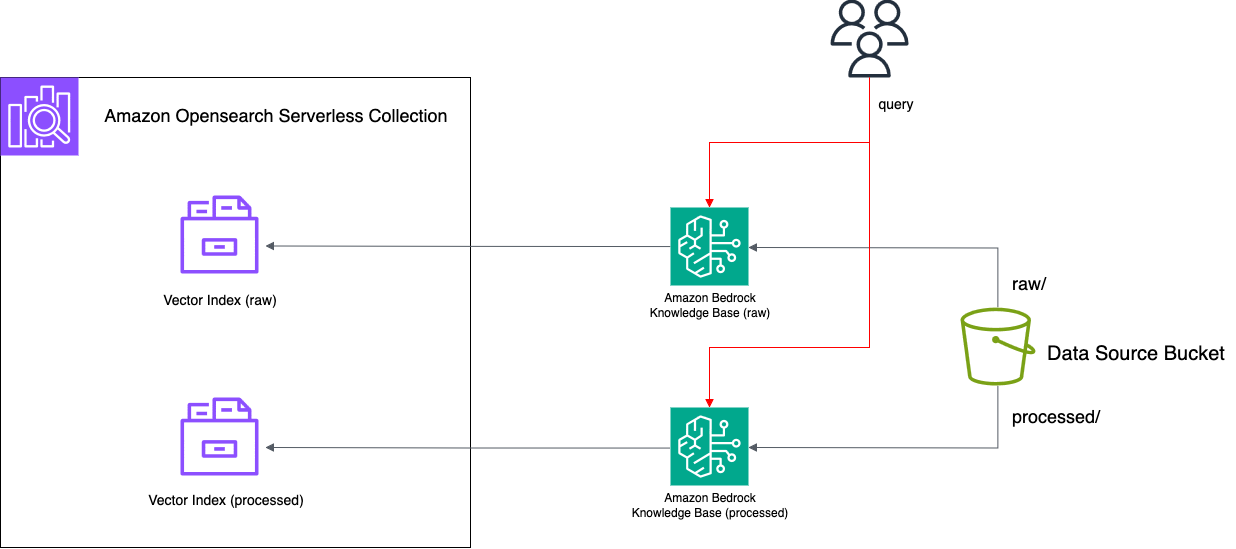
FAQ 같은 짧은 구조화 데이터는 일반 청킹보다 No Chunking이 더 적합했습니다.\nCSV와 메타데이터를 활용해 검색 정확도와 검증 편의성을 높이는 방법을 소개했습니다.

SmartThings 기록 시스템이 HBase 한계를 극복하기 위해 OpenSearch로 교체했습니다. 읽기 성능은 약 19% 향상되고 쓰기 비용은 약 38% 절감했습니다.
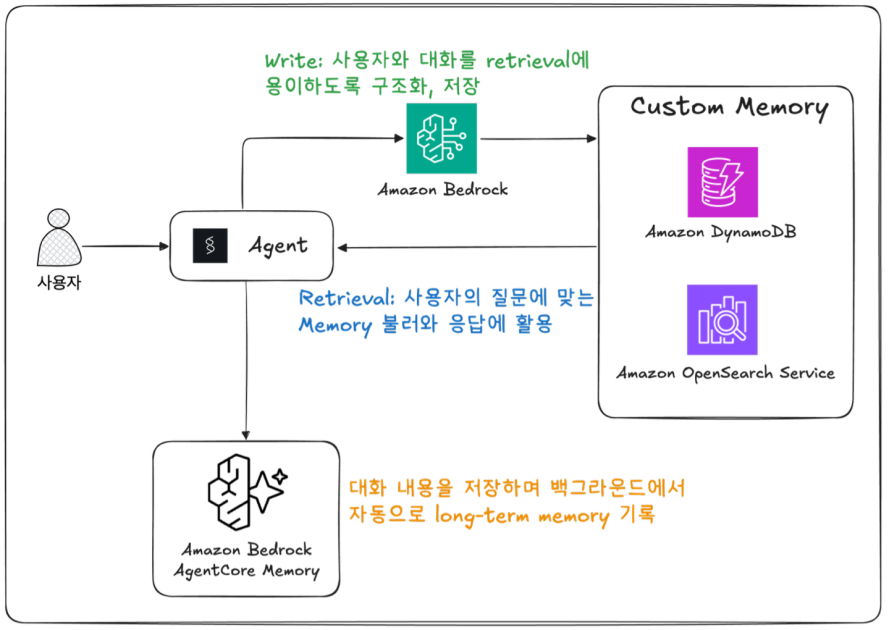
Amazon Bedrock AgentCore Memory와 Custom Memory로 쇼핑 에이전트의 개인화 추천을 구현한 사례를 소개했습니다. 긴 대화 전체보다 중요한 정보만 메모리로 구조화해 더 적은 토큰으로 높은 추천 품질을 얻는 방법을 설명했습니다.