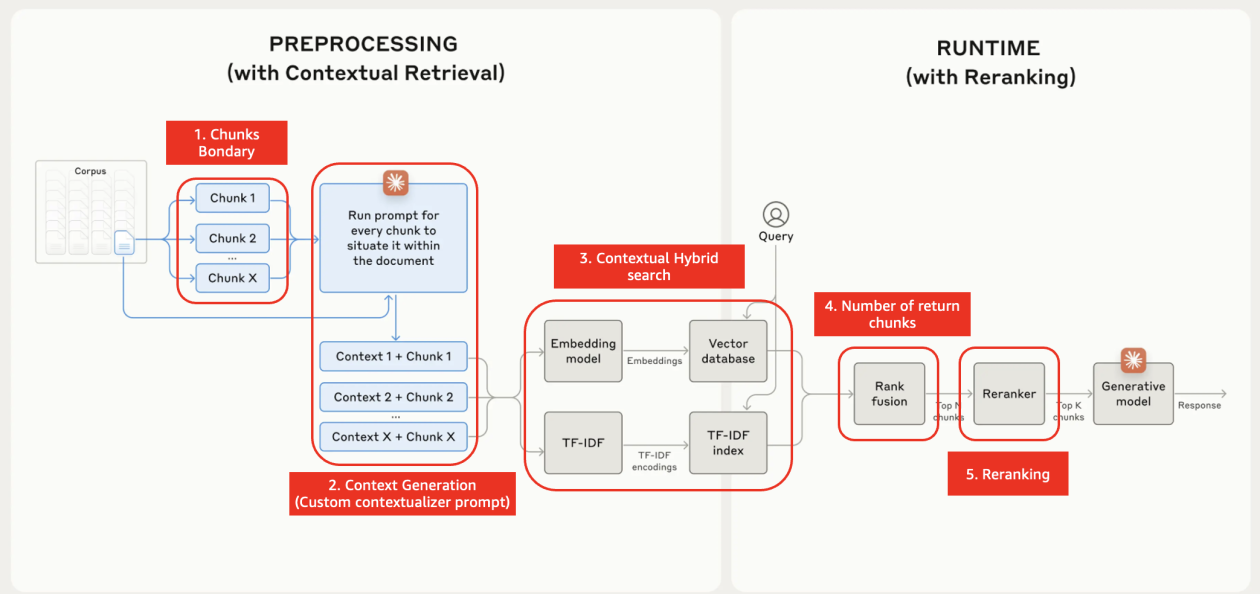

Amazon Bedrock기반에서 Contextual Retrieval 활용한 검색 성능 향상 및 실용적 구성 방안
Amazon Bedrock에서 Contextual Retrieval로 RAG 검색 정확도를 높이는 방법을 설명했습니다. 전처리 컨텍스트 생성, 하이브리드 검색, 리랭킹, 프롬프트 캐싱까지 실무 구성을 함께 다뤘습니다.
#RAG#Amazon Bedrock
77005분
Amazon Bedrock에서 Contextual Retrieval로 RAG 검색 정확도를 높이는 방법을 설명했습니다. 전처리 컨텍스트 생성, 하이브리드 검색, 리랭킹, 프롬프트 캐싱까지 실무 구성을 함께 다뤘습니다.


Gemma와 MediaPipe로 차량 제어용 On-Device AI를 프롬프팅만으로 구현한 실험 과정을 공유했습니다. 기본 명령은 잘 처리했지만, area 인식과 응답 일관성 보완을 위해 파인튜닝이 필요했습니다.

네이버 FE 엔지니어들이 25년 4월 FE News에서 LLM 실패 사례, 프롬프트 엔지니어링, Vibe Coding 등을 소개했습니다. 웹과 AI 관련 주요 기술 소식을 월간으로 큐레이션해 공유했습니다.

Chain-of-Draft는 LLM이 핵심만 간결하게 추론하도록 유도해 토큰 사용량과 지연 시간을 줄이는 프롬프팅 기법을 소개했습니다. 다양한 벤치마크에서 CoT와 비슷한 정확도를 유지하면서도 효율을 높인 결과와 한계를 함께 정리했습니다.

AI와 협업해 코드를 생성하는 바이브 코딩의 개념과 장점을 설명했습니다. 다만 정확성, 의존성, 저작권 문제 같은 한계도 함께 짚었습니다.

생성형 AI 모델 기반 코딩 어시스턴트의 개념과 역할을 소개했습니다. 자연어와 코드 학습을 통해 개발 생산성을 높이는 방향을 설명했습니다.
호텔 검색에서 LLM을 sLLM으로 옮기기 위해 지식 증류를 적용한 과정을 다뤘습니다. 성능과 효율을 함께 확보하기 위한 모델 선정, 데이터 구성, 학습 기법 개선을 설명했습니다.
LLM과 블로그 POI 데이터를 활용해 호텔 검색의 복잡 질의, 다국어, 콘텐츠 부족 문제를 개선했습니다. 검색 엔진 전환과 자동 품질평가로 커버리지와 성과도 함께 높였습니다.

LLM 애플리케이션을 직군에 상관없이 쉽게 만들고 배포할 수 있는 환경 구축 사례를 소개했습니다. Prompt Store, Langflow, 자동 배포 구조로 개발과 피드백 주기를 단축했습니다.

여러 LLM의 응답을 계층적으로 결합해 최종 답변 품질을 높이는 MoA 기법을 소개했습니다. 기존 모델을 바꾸지 않고도 성능과 비용 효율성을 동시에 개선할 수 있음을 설명했습니다.

카카오모빌리티 사내 AI 해커톤 AI 카모톤의 운영 과정과 수상작 사례를 소개했습니다. 짧은 기간에 AI 도구로 프로토타입을 만들고 교육·심사·회고까지 진행한 행사였습니다.

휴리봇을 만들며 얻은 프롬프팅 팁을 소개했습니다. 역할 부여, 자연스러운 말투, OCR 활용, 반복 테스트가 핵심이었습니다.