요기요 검색에서 형태소 분석기의 한계와 극복

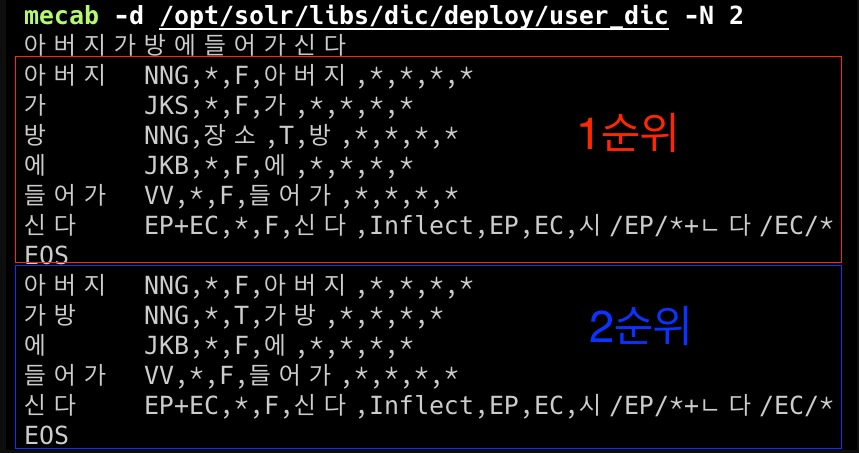
안녕하세요, 요기요 Search Platform 팀의 정승한입니다. 저번 글에서는 검색엔진의 Analyzer, 형태소 분석기 ≠ 토크나이저를 소개해 드렸다면, 이번 글에서는 형태소 분석기에 대해 이야기해 보려고합니다. 요기요 검색에서 사장님들이 본인의 가게가 특정 키워드로 검색되지 않아 문의하시는 경우가 있습니다. 검색엔진에 해당 가게의 문서가 색인이 누락되어 발생할 수 있지만, 종종 문서가 색인에 포함되어 있음에도 검색되지 않는 경우도 종종발생합니다. 이러한 문제에는 다양한 원인이 있지만, 오늘은 그 중에서도 형태소 분석기의 오분석에 관해 이야기해보겠습니다. 요기요 검색에서 형태소 분석기는 답이아니다. 요기요 검색 서비스에서는 현재 은전한닢 프로젝트의 오픈소스 mecab-ko 형태소 분석기를 사용하고 있습니다. 하지만 요기요 검색 서비스가 주로 가게 이름에 대한 검색을 다루기 때문에, 이러한 형태소 분석기로는 해결하기 어려운 점들이 있습니다. 이러한 부분들을 하나씩설명하겠습니다. 1. 형태소 분석기는 문법에 특화되어있다. mecab-ko 형태소 분석기는 문법(문장구조)에 대한 학습을 통해서 만들어진 모델입니다. 그래서 해당 분석기에서 사용하는 사전의 단어들에는 항상 품사들이 붙어있습니다. mecab-ko 사전의 일부:: 품사태그설명 그래서 해당 형태소 분석기는 문장을 쪼갤 수 있는 다양한 경우의 수 중에서, 가장 합리적인 문장구조가 되는 경우를 계산하여 결과를제공합니다. 다음은 형태소 분석기 분야에서 가장 유명한 문장(?) 아버지가방에들어가신다를 mecab-ko 형태소 분석기로 분석한 1, 2 순위결과입니다. 1순위는 “아버지가∨방에∨들어가신다”입니다. 2순위는 “아버지∨가방에∨들어가신다”입니다. 1순위가 우선되는 이유는 아버지라는 명사와 -가라는 조사의 결합이 아버지와 가방의 결합보다 확률적으로 높다고 계산되기때문입니다. 여기서 오해하지 말아야 할 점은, 형태소분석기가 방과 가방의 의미의 차이를 알고서 분석하는 것이 아니라는 것입니다. mecab-ko 형태소 분석기는 단어 자체의 의미는 전혀 알지 못하며, 오로지 문장 구조적으로 가장 합리적이라고 판단되는 결과를제공합니다. 그렇다면, 이러한 형태소 분석기의 특성이 왜 걸림돌이 될까요? 형태소 분석기가 문장 구조와 문법에 특화되어 있다는 것은, 문법적으로 맞지 않은 문장을 제대로 분석하기 어렵다는 뜻입니다. 가게명은 고유명사이기 때문에 문법에 어긋나게 독특하게 지어지는 경우가 많습니다. 아래는 그예시들입니다. 파슷타애요는 파스타와 -에요를 맞춤법에 맞지 않게 표기했기 때문에 형태소 분석기는 이를 제대로 분석할 수 없습니다. 파슷타와 -애요는 사전에 존재하지 않기때문입니다. 닭갈비가싸닭은 언어유희로 싸다를 싸닭으로 표기했습니다. 닭은 분석할 수 있지만, 싸를 어떻게 처리해야 할지 형태소 분석기 입장에서는난감해집니다. 또한, 가장 합리적인 구조 한 가지 결과만 사용한다는 것도 문제가 됩니다. 아버지가방에들어가신다처럼 중의적인 문장이 존재하기 때문입니다. 예를 들어, 신반점 키워드를 생각해 보면, 이는 두 가지 의미로 해석될 수있습니다. 신' + 반점' 인천광역시 서구 석남동에 위치한중국집 신반' + 점' 경상남도 의령군 부림면 신반리 지역의지점명 두 경우 모두 신반점이라고 검색했을 때 노출되어야 하지만, 형태소 분석기는 한 가지 방식의 분석 결과만 사용하기 때문에 나머지 하나는 검색되지 않게됩니다. 2. 형태소 분석은 서로소(disjoint) 분할이다. 이때까지의 형태소 분석 결과 예시들을 보면, 형태소들끼리 음절을 공유하지 않습니다. 신반점 예시를 다시 보면, 신+반점 이거나 신반+점 두 경우만 존재하지, 반 음절을 공유해서 두 형태소 신반+반점으로 나뉘는 경우는 없습니다. 하지만 이렇게 음절을 공유하도록 형태소를 분석해야 하는 경우도존재합니다. 예시로 가게명 김치찜질방'의 형태소 분석을 생각해 봅시다. 이 가게는 김치찜을 파는 가게이기 때문에 김치찜 형태소가 필요합니다. 형태소 분석기는 서로소 분할을 하기 때문에 선택지는 아래 두가지입니다. 김치+찜질방 김치찜+질방 두 가지 중에 가장 합리적인 김치+찜질방으로 분석하게 됩니다. 왜냐하면 질방은 사전에 없는 단어이기 때문입니다. 그래서 항상 서로소로 분할하는 형태소 분석기의 특성은 여기서 걸림돌이됩니다. 비슷한 예)쭈꾸미술관 3. 분석되고자 하는 형태소가 사전에 반드시 있어야한다 mecab-ko 형태소 분석기가 우리가 기대하는 대로 분석되려면, 필수적으로 나오길 기대하는 형태소들이 형태소 분석기 사전 안에 있어야합니다. 아래는 돼지게티라는 가게이름을 형태소 분석한결과입니다. 비록 돼지라는 단어는 사전에 있지만, 돼지와 이어질 적절한 게티를 나타낼 형태소가 사전에 없기 때문에 엉뚱한 분석 결과가나옵니다. 이러한 고유어외에도 신조어 (ex.먹킷리스트) 줄임말 (ex.짜계치) 외래어 (ex.밥밥디라라) 등은 사전을 기반으로 하는 형태소 분석기만으로 대응하기 어렵습니다. 새로운 형태소가 등장할 때마다 사전에 등록해야 하기때문입니다. Search Platform 팀에서는 형태소 분석기의 오분석 문제를 형태소 분석기의 성능을 개선하여 해결하려고 했지만, 앞서 언급한 형태소 분석기의 특성들로 인해 요기요에서는 애초에 형태소 분석기가 답이 아니라는 것을확신했습니다. N-gram을 통한 형태소분석기 한계를보완 그래서 우리는 과감하게 N-gram을 도입했습니다. N-gram은 불필요한 토큰이 많이 만들어져 의도치 않은 매칭이 발생할 수 있다는 문제점이 있습니다. 하지만 저희가 개선한 방식은 기존 Analyzer를 N-gram 기반의 Analyzer로 전면 교체하는 방식이 아닌, 서로의 단점을 보완하는 방식으로개발하였습니다. 기존에 사용하던 형태소 분석기 기반의 Analyzer를 사용하는 필드 외에 N-gram Analyzer를 사용하는 필드를 추가했습니다. 이 필드에서는 색인의 경우에만 N-gram을 사용하도록 했는데, 이때는 2-gram부터 사용합니다. 왜냐하면, 굴 같은 1음절 키워드로 검색했을 때 굴렁쇠 같은 가게명과 매칭되지 않게 하기위해서입니다. 예시로 김치찜질방을 분석하면 아래의 term들을 색인하게됩니다. 2-gram 김치, 치찜, 찜질,질방 3-gram 김치찜, 치찜질,찜질방 색인에서 이렇게 처리하면, 김치찜, 찜질방으로 모두 검색이 가능해집니다. 기존에는 김치와 찜질방 두 가지 term밖에 없어서 김치찜으로는 검색이 불가능했던 것과는 다른결과입니다. 그리고 쿼리에서는 형태소 분석기 기반 Analyzer를 사용하니 사전에 없을 만한 치찜, 질방 등은 term으로 나오지 않기 때문에 N-gram에서 염려되는 불필요한 매칭은 일어나지않습니다. 하지만 2-gram부터 사용하기 때문에 신반점의 문제는 이것만으로는 해결되지 않습니다. 2-gram부터 사용하면 나오는 term은 다음과같습니다. 2-gram 신반,반점 3-gram 신반점 하지만 쿼리에서는 신+반점 또는 신반+점이 나오기 때문에 한 글자 term인 신과 점의 매칭이 일어나지 않습니다. 그래서 쿼리문 전체를 term으로 추출하여 신반점 색인 term과 매칭되도록추가하였습니다. 마무리 이번 개선을 통해서 형태소분석기 오분석으로 인한 검색 미노출 CS가 2분기 0건을 기록(1분기 30건 대비 100% 감소)하였습니다. 검색에서 주로 형태소 분석기를 많이 사용하지만, 이것이 능사는 아닙니다. 플랫폼마다 색인어들의 특성이 있고, 그에 맞는 Analyzer를 설계하는 것이 중요합니다. 끝까지 정독해 주신 분들께 감사드리며, 다음에 또 흥미로운 주제로찾아뵙겠습니다. 요기요 검색에서 형태소 분석기의 한계와 극복 was originally published in YOGIYO Tech Blog - 요기요 기술블로그 on Medium, where people are continuing the conversation by highlighting and responding to this story.