


FMS(Fleet Management System) 주행이벤트 파이프라인 개선기
주행 이벤트 파이프라인에서 데이터 순서 보장과 대량 IoT 트래픽 처리를 위해 구조를 두 차례 개선했습니다. Kafka, NoSQL, 멱등성 설계로 비동기 실시간 처리와 정합성을 높였습니다.
#Kafka#NoSQL
37005분
새로운 기술 블로그가 추가되었어요
주행 이벤트 파이프라인에서 데이터 순서 보장과 대량 IoT 트래픽 처리를 위해 구조를 두 차례 개선했습니다. Kafka, NoSQL, 멱등성 설계로 비동기 실시간 처리와 정합성을 높였습니다.

실시간 광고 사용자 ID 매핑 시스템과 그 설계 과정을 다룬 발표 세션을 공개했습니다. gRPC, Spark Structured Streaming, Kafka를 활용한 마이크로서비스 구성과 그래프 기반 매핑 방식을 소개했습니다.


Spring Boot에서 R2DBC Connection Pool이 초기화되지 않는 원인과 해결 과정을 소개합니다. IntelliJ를 활용해 문제를 재현하고 원인을 추적한 사례입니다.


pNFS는 기존 NFS의 단일 서버 병목을 줄이기 위해 나온 병렬 파일 시스템 구조를 소개합니다. AI/ML 워크로드의 대규모 데이터 처리와 고성능 스토리지 수요에 맞는 기술로 설명했습니다.


전시 딜 정보를 내재화해 MongoDB 기반으로 전환한 과정을 회고했습니다. OracleDB 의존으로 생기던 조회·운영 비효율을 줄이려는 개선 사례입니다.


부스터스의 주문 수집부터 WMS 출고까지의 내부 플로우와 구축 배경을 정리한 글입니다. 주소 잘림과 중복 실행 이슈, 그리고 격리 수준을 활용한 정합성 방어를 다뤘습니다.


검색엔진의 Analysis 흐름과 Analyzer의 역할을 정리하고, 형태소 분석기와 토크나이저의 차이를 설명했습니다. 또한 동의어·n-gram·stop filter로 검색 품질을 조정하는 방법을 소개했습니다.

실시간 장바구니 추천 모델을 위한 서빙 아키텍처와 운영 체계를 소개했습니다. TorchServe, Kubernetes, ArgoCD, MLOps와 모니터링 적용 사례를 정리했습니다.

캐시 미스와 만료 구간에서 발생하는 Thundering Herd 문제를 줄이기 위해 req-shield를 설계했습니다. 락과 TTL 갱신 전략으로 중복 조회를 억제하고 부하 테스트로 성능 향상을 확인했습니다.


AWS Aurora/RDS와 DynamoDB를 GCP Cloud SQL for MySQL로 이전한 과정을 정리했습니다. 쿼리와 스키마 점검, 병렬 복제, binlog 설정으로 다운타임과 비용을 줄인 사례입니다.

MessagingHub 확장으로 늘어난 질문과 커뮤니케이션 비용을 줄이기 위해 서버 SDK와 문서를 정비했습니다.\n연동 허들을 낮추고 질문을 코드와 가이드 중심으로 바꿔 실무 몰입도를 높였습니다.
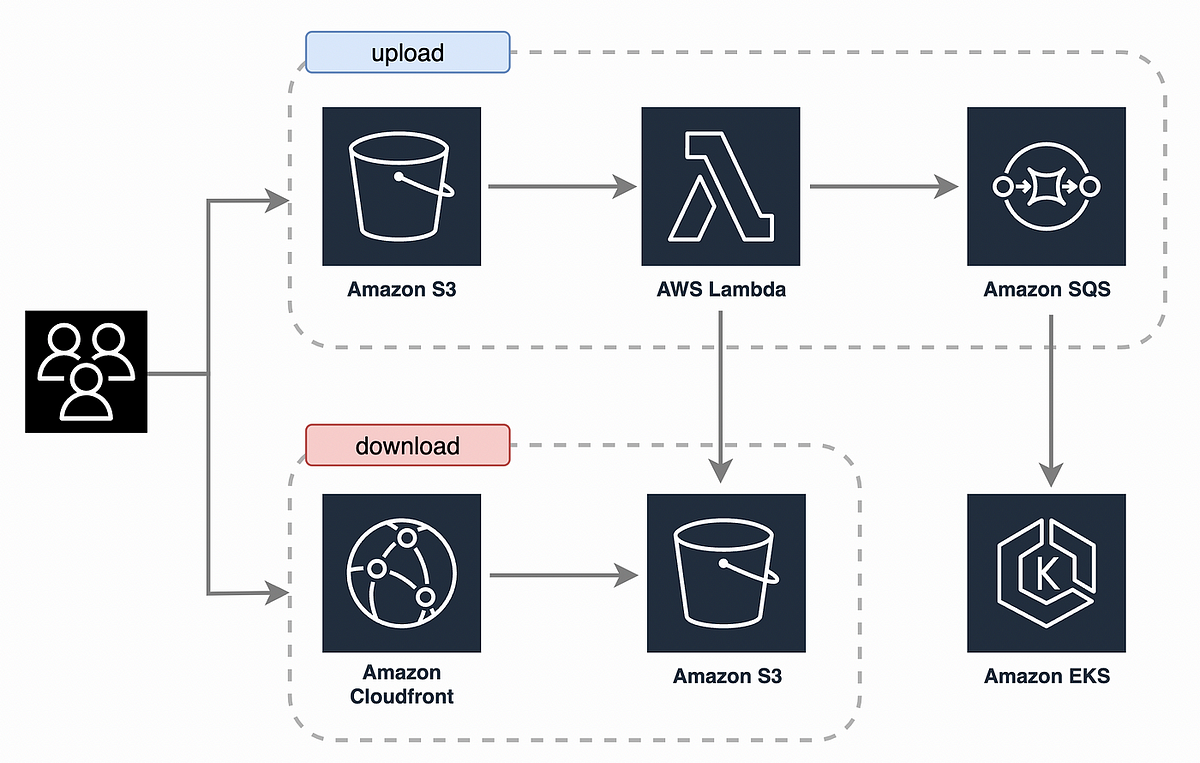
AWS S3 Object Lambda로 On-Demand 이미지 변환 서비스를 구축한 사례를 소개했습니다. 사전 저장 방식의 비용과 복잡도를 줄이고 CloudFront 연동으로 성능과 운영 효율을 개선했습니다.