


vLLM로 효율적인 모델 서빙하기
vLLM을 활용한 LLM 서빙 최적화 방법을 배치 전략, 어텐션 최적화, 추론 전략으로 나눠 설명했습니다. 온라인 서빙과 오프라인 서빙의 차이와 간단한 구현 예시도 함께 소개했습니다.
#vLLM#LLM
86005분
새로운 기술 블로그가 추가되었어요
vLLM을 활용한 LLM 서빙 최적화 방법을 배치 전략, 어텐션 최적화, 추론 전략으로 나눠 설명했습니다. 온라인 서빙과 오프라인 서빙의 차이와 간단한 구현 예시도 함께 소개했습니다.

무신사는 GitHub Copilot의 생산성 효과를 30명 규모의 데이터와 설문으로 검증했습니다. 일부 지표는 개선됐지만 코드 품질 관리와 가이드라인의 중요성도 확인했습니다.

Google Cloud Vision API로 OCR을 수행하는 방법을 정리했습니다. API Key 방식과 서비스 계정 인증 방식을 비교하며 Colab에서의 사용법을 소개했습니다.


산업 현장에 맞는 Vertical AI 에이전트 구현 방식과 설계 원칙을 소개했습니다. Agent Flow와 Autonomous Agent를 조합해 예측 가능한 문제와 예외 상황을 함께 다뤘습니다.

LLM 추론 효율을 높이기 위한 배치 전략과 어텐션 개선 방법을 정리한 글입니다. FlashAttention, 페이지 어텐션, 추측 디코딩의 개념과 장점을 설명했습니다.

LLM 애플리케이션을 직군에 상관없이 쉽게 만들고 배포할 수 있는 환경 구축 사례를 소개했습니다. Prompt Store, Langflow, 자동 배포 구조로 개발과 피드백 주기를 단축했습니다.
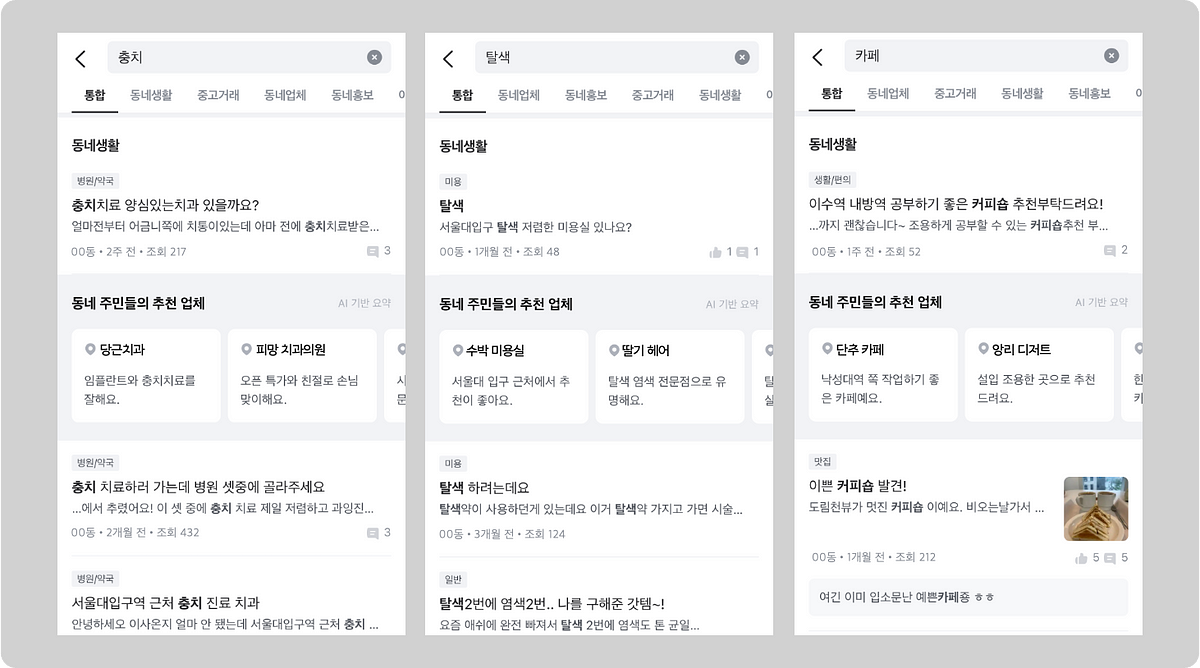
동네생활 게시글과 댓글에서 업체 추천 정보를 찾아 RAG 기반 검색 서비스로 연결했습니다.\n벡터 검색, LLM 요약, 적절성 필터링을 거쳐 신뢰도 높은 추천 결과를 제공했습니다.


깃허브 코파일럿의 기본 기능과 VSCode에서의 활용법을 정리했습니다. 컨텍스트를 충분히 주고 슬래시 명령어와 챗 변수를 쓰면 더 유용하게 사용할 수 있습니다.

LLM 파인튜닝에서 배치 크기, 시퀀스 길이, 메모리 최적화 기법의 영향을 실험 기반으로 정리했습니다.\nGPU 제약과 데이터 특성에 맞춰 직접 실험하며 최적값을 찾는 접근을 강조했습니다.

PTQ의 성능 저하 한계를 보완하기 위한 QAT 개념과 원리를 설명했습니다.\nNVIDIA pytorch-quantization으로 QAT를 수행하고 ONNX/TensorRT로 변환하는 절차를 소개했습니다.

아마존 베드락을 활용해 사내 지식저장소를 구축하고 AI챗봇과 코드리뷰봇을 개발한 경험을 공유했습니다. 업무도우미 AI봇에 춘식이 요소를 더한 소개 글입니다.

여러 LLM의 응답을 계층적으로 결합해 최종 답변 품질을 높이는 MoA 기법을 소개했습니다. 기존 모델을 바꾸지 않고도 성능과 비용 효율성을 동시에 개선할 수 있음을 설명했습니다.