
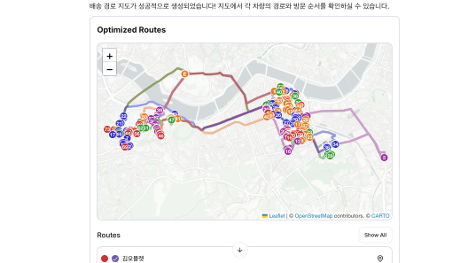

Amazon Bedrock을 활용한 Omelet의 경로 최적화 AI 에이전트, TOAST
Amazon Bedrock을 활용해 경로 최적화 AI 에이전트 TOAST를 구현한 사례를 소개했습니다. 자연어 입력, 다중 에이전트 구조, 시각화와 재최적화를 통해 활용성을 높였습니다.
#Amazon Bedrock#LLM
72005분
새로운 기술 블로그가 추가되었어요
Amazon Bedrock을 활용해 경로 최적화 AI 에이전트 TOAST를 구현한 사례를 소개했습니다. 자연어 입력, 다중 에이전트 구조, 시각화와 재최적화를 통해 활용성을 높였습니다.


Gemma 3n의 멀티모달 온디바이스 특징과 오디오·이미지 입력 예제를 소개했습니다. 다양한 입력 방식을 활용해 오프라인 환경에서도 응용할 수 있음을 보여주었습니다.

Context Engineering을 기존의 context 관리 실천과 Linear MCP 도입 사례로 설명했습니다. 티켓 메타데이터와 상태 연동으로 계획, 소통, 구현을 통합하는 방식을 공유했습니다.

Ray를 활용해 GPU Util 100% 배치 처리와 확장 가능한 모델 서빙 아키텍처를 소개했습니다. Ray Serve와 vLLM 기반 LLM 추론 파이프라인 및 운영 사례도 다뤘습니다.
Cursor와 MCP로 유저챗 대응과 PR 리뷰를 자동화해 반복 업무 시간을 크게 줄인 사례를 소개했습니다. 업무 절차를 문서화하고 파이프라인화해 AI가 분석과 리뷰를 돕도록 구성했습니다.

PIM은 메모리 내부에서 연산을 수행해 데이터 이동을 줄이는 기술입니다. 폰 노이만 구조의 병목과 전력 문제를 줄이며 AI·빅데이터 처리 효율을 높입니다.
Cursor 전사 도입 6개월 동안 개발팀이 AI 중심 워크플로로 전환된 과정을 공유했습니다. 문제 정의와 설계에 집중하고, 다양한 AI 도구로 생산성을 높인 사례를 소개했습니다.

Amazon Bedrock과 MCP로 기업 AI 에이전트가 공통 도구를 표준화해 쓰는 중앙 허브 구조를 소개했습니다. 분산 개발과 중앙 거버넌스를 결합해 확장성, 보안, 운영 효율을 높이는 방식입니다.

사내 노션과 슬랙 지식을 연결하는 RAG 기반 챗봇 라포위키 개발 과정을 소개했습니다. 내부 용어집, 메타데이터, 청크 임베딩으로 검색 정확도와 최신성을 높였습니다.
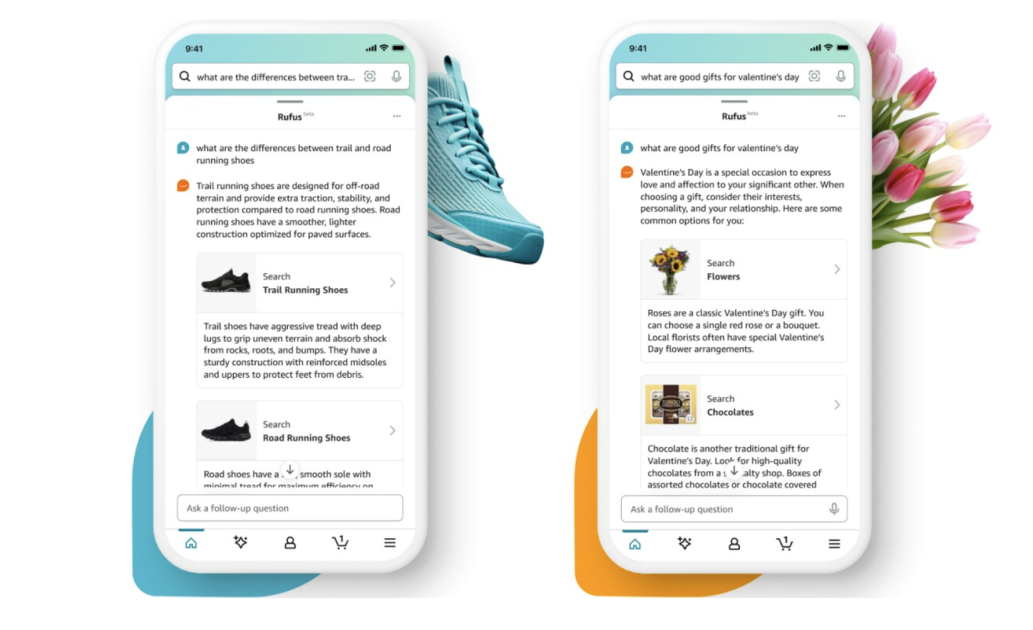
Amazon Bedrock과 AWS 서비스 조합으로 Rufus 같은 쇼핑 어시스턴트를 구현하는 방법을 소개했습니다. Tool 최적화, 컨텍스트 사전 로딩, prompt caching으로 응답 속도를 줄이는 방식을 설명했습니다.


AI 코딩 어시스턴트의 시장 동향과 국내외 도입 사례, 모델·솔루션 비교를 한 번에 정리했습니다.파일럿 검증을 거쳐 성능, 보안, 비용을 함께 고려한 점진적 도입 전략을 제안했습니다.

OpenSearch Service의 AI Search Flow 빌더로 Semantic 검색과 멀티모달 RAG를 빠르게 구성하는 방법을 소개했습니다. Ingest/Search Pipeline과 템플릿, AI 제공업체 연동으로 미들웨어 없이 검색 기능을 확장하는 흐름을 설명했습니다.