복잡한 비즈니스 로직, 파이프라인으로 다듬기

복잡한 비즈니스 로직, 파이프라인으로 다듬기
대출 심사 로직의 복잡도를 줄이기 위해 Pipeline, Job, Store 구조를 적용한 사례를 소개했습니다. 정책 변경과 테스트를 더 쉽게 만들기 위한 설계 고민을 정리했습니다.
#GitLab#CI/CD
81005분
대출 심사 로직의 복잡도를 줄이기 위해 Pipeline, Job, Store 구조를 적용한 사례를 소개했습니다. 정책 변경과 테스트를 더 쉽게 만들기 위한 설계 고민을 정리했습니다.

PostgreSQL에서 ES로의 CDC 파이프라인을 Kafka Connect로 구성한 뒤의 트러블슈팅 글입니다. 제공된 본문만으로는 구체적 문제와 해결 내용은 확인되지 않습니다.
CDC 파이프라인 정합성 검사 Spark 잡의 최적화 방법을 다룬 후속 글입니다. 앞선 코드 설계편에 이어 Spark 잡 성능 개선과 운영 관점을 소개했습니다.

시계열 분석용 AI 모델 개발에서 전처리와 훈련 자동화를 위한 MLOps 파이프라인 구축 경험을 소개했습니다. 상세 본문은 확인되지 않아 핵심 주제만 파악할 수 있었습니다.
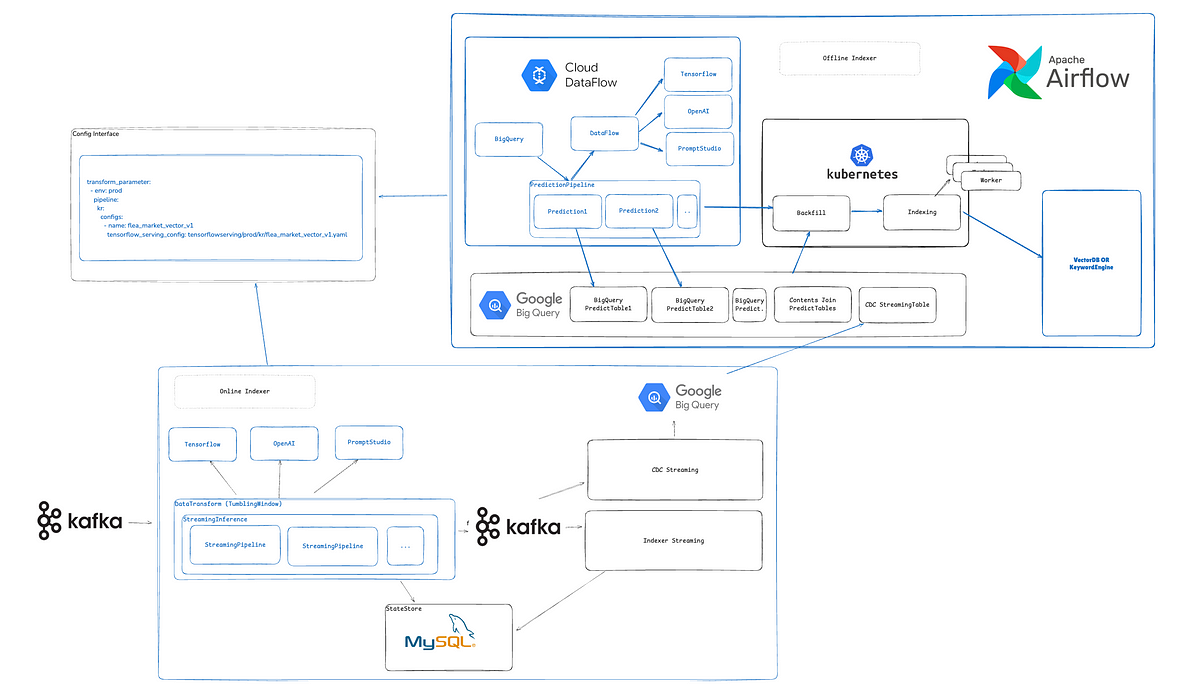
검색 색인 파이프라인의 생산성과 안정성을 높이기 위해 설정 기반 자동화, Offline Storage 활용, 배치 처리 구조를 도입했습니다. 이를 통해 대용량 이벤트와 풀색인 비용 문제를 줄이고 운영 효율을 개선했습니다.


GitLab Secret Detection으로 리포지터리의 시크릿 유출을 자동 탐지하는 방법을 소개했습니다.\nPipeline 설정, 전체 히스토리 스캔, 취약점 리포트 활용까지 실무 적용 흐름을 정리했습니다.


허깅페이스 Trainer API로 KLUE/ynat 텍스트 분류 모델을 학습하고 평가하는 과정을 정리했습니다. 또한 학습한 모델을 허브에 업로드하고 pipeline으로 추론하는 방법도 함께 소개했습니다.
X