
[외부 초청 세션] AWS가 DynamoDB를 만든 방법
AWS가 DynamoDB를 설계하고 운영하는 핵심 원칙과 내부 구조를 소개했습니다. 대규모 트래픽, 셀 기반 아키텍처, 배포·라우팅 최적화 사례를 함께 다뤘습니다.
#DynamoDB#AWS
51005분
AWS가 DynamoDB를 설계하고 운영하는 핵심 원칙과 내부 구조를 소개했습니다. 대규모 트래픽, 셀 기반 아키텍처, 배포·라우팅 최적화 사례를 함께 다뤘습니다.


LINE Games가 Amazon Bedrock 기반 AI Agent로 퍼블리싱 기술 지원을 자동화한 사례입니다. 문서 수집·정제·검색을 고도화하고 스트리밍과 캐싱으로 응답 속도와 운영 효율을 높였습니다.
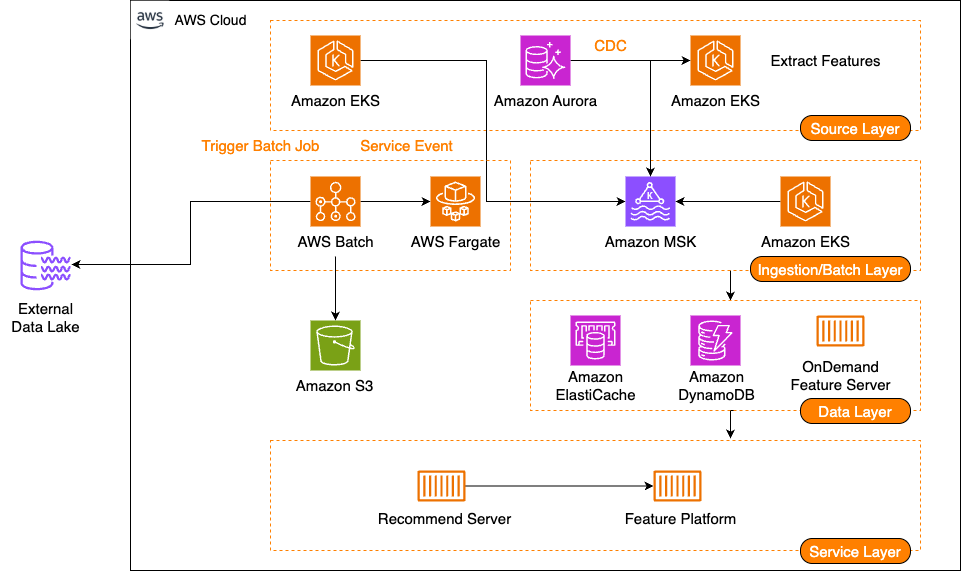
당근은 AWS 기반 피처 플랫폼의 수집 계층을 스트림과 배치로 나누어 구성했습니다. 대규모 이벤트와 배치 작업을 안정적으로 처리하며 운영상의 개선점도 함께 정리했습니다.

당근은 추천 시스템 고도화를 위해 AWS 기반 피처 플랫폼을 설계하고, 다단계 캐시와 일관된 스키마로 피처 서빙을 구성했습니다. 캐시 미스, 정합성, 관통 문제를 완화하며 대규모 트래픽을 안정적으로 처리하는 구조를 소개했습니다.

에이전트 서비스의 실행 이력과 툴 매핑을 DynamoDB, Redshift, Valkey로 나눠 설계하는 방법을 설명했습니다. 액세스 패턴 기반 스키마와 분석·캐시 구조로 성능과 추천 정확도를 높이는 방향을 제안했습니다.

디프로모션은 성장 과정에서 기존 데이터 구조의 한계를 보완하기 위해 DynamoDB, zero-ETL, ElastiCache Serverless를 도입했습니다. 실시간 동기화와 캐시 최적화로 응답 속도와 운영 효율을 함께 개선했습니다.

Amazon ElastiCache가 Valkey 8.0을 지원하며 더 빠른 스케일링과 개선된 메모리 효율을 제공했습니다. 서버리스 확장 속도와 노드 기반 클러스터의 메모리 사용량이 모두 개선되었습니다.