
Trino로 타임아웃 개선하기
로그 누적으로 발생한 대시보드 타임아웃과 slow query 문제를 Trino 도입으로 개선한 사례를 다뤘습니다. OBS와 Parquet, MySQL tier down 구조를 통해 집계 성능과 저장 효율을 함께 고려했습니다.
#Trino#MySQL
35005분
로그 누적으로 발생한 대시보드 타임아웃과 slow query 문제를 Trino 도입으로 개선한 사례를 다뤘습니다. OBS와 Parquet, MySQL tier down 구조를 통해 집계 성능과 저장 효율을 함께 고려했습니다.

Kafka Connect와 JDBC 소스 커넥터로 DB 데이터를 Kafka에 연동하는 방법을 설명했습니다. 쿼리 기반 CDC의 한계와 데이터 누락을 줄이는 설정도 함께 정리했습니다.

LLM으로 중고 스마트폰 게시글에서 시세 산정용 정보를 추출하고 후처리하는 서비스를 구축했습니다. BigQuery, MySQL, 벡터 DB를 조합해 시세 조회와 유사 게시글 추천을 구현했습니다.

Exposed와 MySQL 조합에서 발생한 SQLSyntaxErrorException의 원인을 단계적으로 추적했습니다. 임시 해결책보다 근본 원인을 찾는 디버깅 접근을 다뤘습니다.


DataHub를 그대로 노출하지 않고 OpenSearch와 DB를 직접 활용해 데이터카탈로그에 맞는 검색·리니지·BI 통합 기능을 구현했습니다. 또한 버전업과 수집 성능 문제를 개선해 운영 적합성을 높였습니다.


RDS MySQL에서 Aurora로 이전할 때 다운타임을 줄이는 절차를 정리했습니다. 스냅샷 마이그레이션과 복제 동기화, binlog 관리가 핵심이었습니다.


Aurora Serverless v2의 동작 방식과 Aurora MySQL 대비 특징, 성능 및 비용 차이를 정리했습니다.\n트래픽 변동성이 큰 서비스에 적합하지만, 고정 부하에서는 비용 효율을 다시 검토해야 했습니다.

JDBC Driver 변경 이후 발생한 OOM 원인을 DB Connection 누수로 추적하고 Heap Dump로 확인했습니다. mysql-connector-j 업그레이드와 cleanup thread 비활성화로 문제를 해결했습니다.

온라인 DDL 테스트를 자동화해 알고리즘 선정과 사전 검증 과정을 표준화했습니다. 클론 생성, 비동기 실행, 히스토리 저장, Slack 알림으로 운영 효율과 안정성을 높였습니다.
JdbcPagingItemReader와 MySqlPagingQueryProvider의 페이지네이션 동작과 주의사항을 정리했습니다.\nsort key와 group clause 설정에 따라 데이터 누락과 SQL 오류가 발생할 수 있어 조심해야 했습니다.
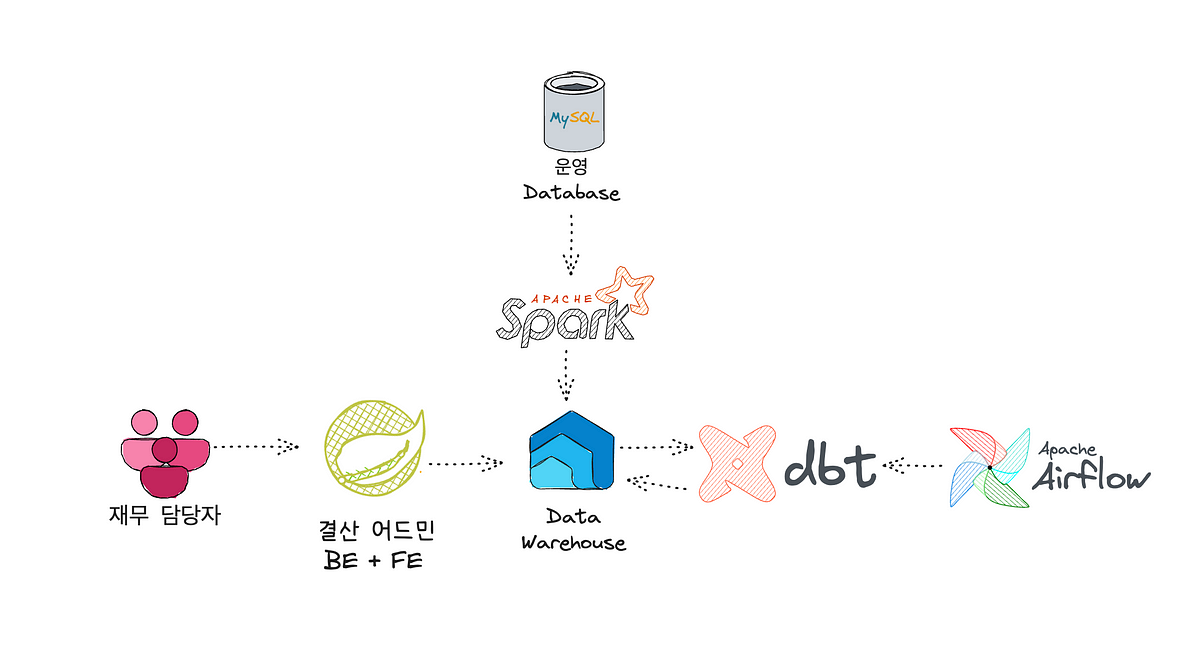
매월 반복되던 재무 결산을 Spring Batch와 코드 중심 구조에서 Airflow와 dbt 기반 데이터 파이프라인으로 전환했습니다. SQL 수정만으로 결산 대응이 가능해져 유연성과 가시성을 높였습니다.


광고 업체 유효성 검사 시스템을 직접 API 호출에서 캐시와 Kafka 기반 실시간 처리로 개선한 과정을 정리했습니다. gRPC와 표준화된 필드로 성능, 확장성, 유지보수성을 높였습니다.