급증하는 트래픽 안정적으로 처리하기: 개선편(2) 논리적 파티셔닝

급증하는 트래픽 안정적으로 처리하기: 개선편(2) 논리적 파티셔닝
단일 Queue의 HOL Blocking과 인스턴스 단위 스케일링 비효율을 논리적 파티셔닝으로 개선했습니다. Partition별 독립 스케일링으로 10만 건 처리 시간을 25분에서 4분으로 줄였습니다.
#Redis#Kafka
0005분
단일 Queue의 HOL Blocking과 인스턴스 단위 스케일링 비효율을 논리적 파티셔닝으로 개선했습니다. Partition별 독립 스케일링으로 10만 건 처리 시간을 25분에서 4분으로 줄였습니다.
단일 큐에서 발생하던 HOL Blocking을 논리적 파티셔닝으로 완화했습니다. Coordinator 기반 독립 스케일링으로 10만 건 처리 시간을 84% 줄였습니다.


레거시 알림톡 발송을 트랜잭션 커밋 이후 Kafka 기반 구조로 분리했습니다. 데이터 정합성과 확장성을 높이며 공통 발송 체계를 만들었습니다.


OpenTelemetry와 ClickHouse로 대용량 로그 파이프라인을 다시 설계한 사례를 소개했습니다. 하루 41TB 로그를 20초 이내 처리하고 비용을 크게 줄인 과정을 정리했습니다.

오프라인 매장의 종이라벨을 전자라벨로 전환하며 메시지 기반 데이터 파이프라인을 구축했습니다. 비동기 동기화와 중앙 관제로 운영 효율과 데이터 일관성을 높였습니다.
정산 도메인의 특성에 맞춰 이벤트 처리와 배치 처리를 분리한 하이브리드 구조를 설명했습니다. Kafka, Spring Batch, Argo Workflow로 실패와 재처리를 전제로 한 정산 시스템을 구현했습니다.
정산을 사람의 기억이 아닌 시스템의 책임으로 옮기기 위한 MASS 설계 원칙을 다뤘습니다. 멱등성, 결정적 계산, 고정 반올림으로 재처리와 재계산에도 동일한 결과를 보장했습니다.

외부 채널 입고 정보를 안전하게 동기화하기 위해 아웃박스 패턴과 재시도 토픽을 적용한 사례를 소개했습니다. Spring Kafka와 Namastack Outbox로 원자성, 재시도, 실패 알림을 정리했습니다.
![[VOD] re:COMMIT 오늘부터 스타트업 개발자입니다: 서비스 설계에서 놓치기 쉬운 것들](https://tech.goorm.io/wp-content/uploads/2025/12/REcommit_thumbnail-1024x570.png)

스타트업 개발자가 서비스 설계에서 마주하는 핵심 의사결정 포인트를 다룹니다. 가상의 SNS 설계를 통해 기술 선택과 운영 관점을 함께 살펴봅니다.
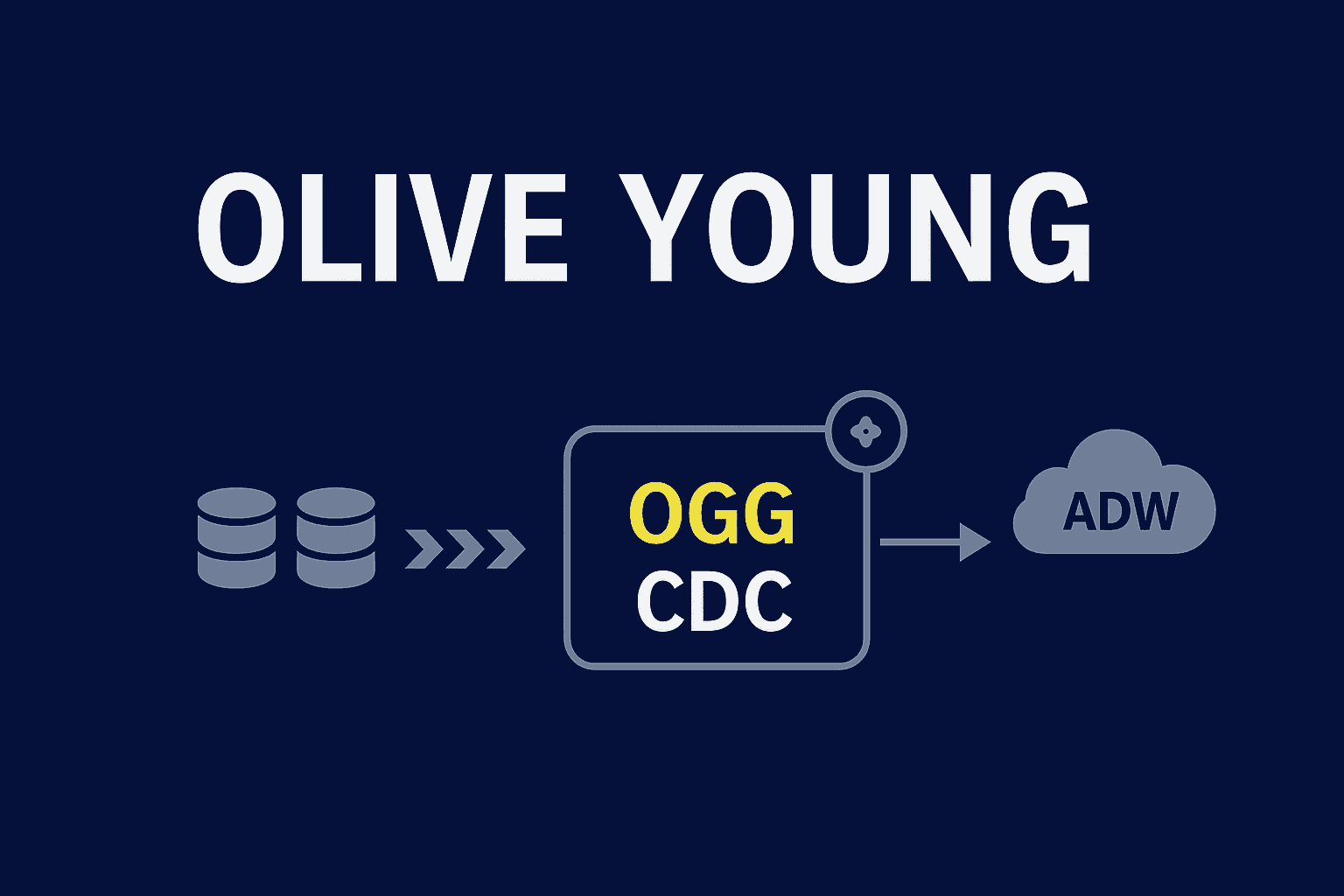
ODI 배치 기반 캠페인 동기화를 OGG와 Kafka 기반 CDC로 전환한 사례를 다뤘습니다. 메시지 순서 문제는 Retry, DLT, 복구 배치로 보완했고 실시간 정합성과 운영 모니터링을 강화했습니다.

도메인별로 분산 운영되던 8개 Kafka 클러스터를 공통 Kafka로 통합하는 전환 과정을 정리했습니다. MirrorMaker2 기반 점진 전환으로 서비스 영향 없이 데이터 일관성과 Offset을 유지했습니다.

네이버 Logiss의 로그 파이프라인 운영 문제와 개선 과정을 다뤘습니다. Storm Kafka spout 수정과 멀티 토폴로지 도입으로 비용·성능·안정성을 높이려 했습니다.