우리 팀엔 자바스크립트 상차만 하는 프런트엔드가 있었다

우리 팀엔 자바스크립트 상차만 하는 프런트엔드가 있었다
프런트엔드의 index.html을 백엔드에서 분리해 독립 배포 구조로 전환했습니다. S3, CloudFront, Lambda@Edge를 활용해 성능과 운영 효율을 함께 개선했습니다.
#React#TypeScript
42005분
프런트엔드의 index.html을 백엔드에서 분리해 독립 배포 구조로 전환했습니다. S3, CloudFront, Lambda@Edge를 활용해 성능과 운영 효율을 함께 개선했습니다.
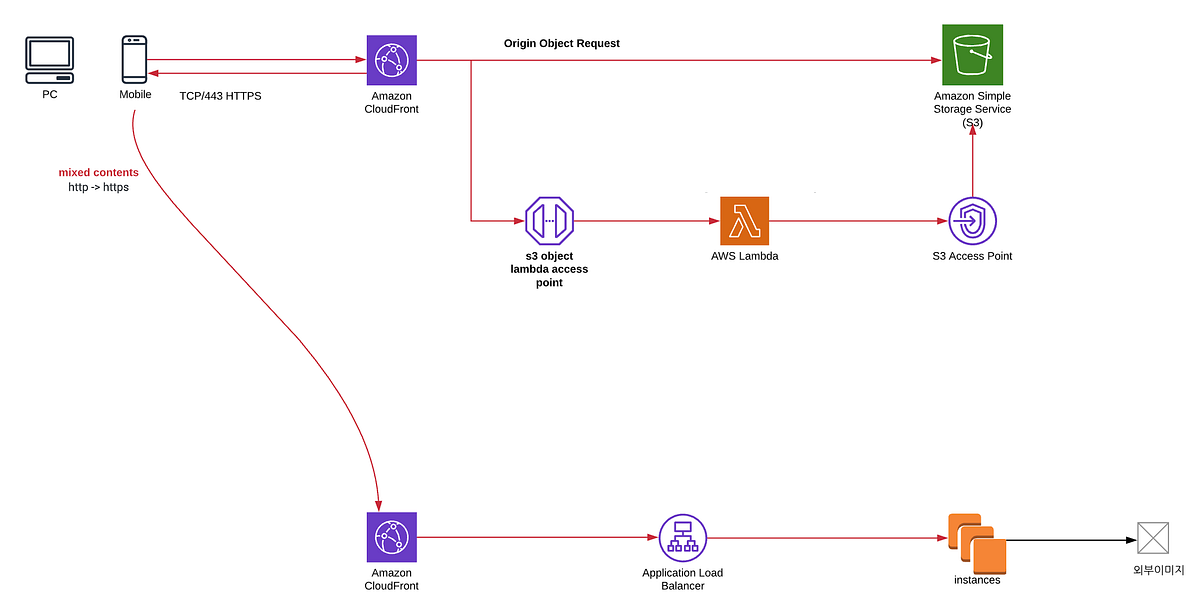

롯데ON이 외부 이미지 솔루션을 대신해 LLIS를 자체 구축한 사례를 다뤘습니다. S3 Object Lambda와 CloudFront 캐시로 비용을 줄이면서 실시간 이미지 처리 성능을 유지했습니다.


정산시스템의 대용량 엑셀 출력에서 OOM과 재시도 폭주를 해결한 사례를 다뤘습니다. 날짜 단위 병렬 처리와 DB Cursor, S3 업로드로 메모리 부담 없이 비동기 다운로드 구조를 만들었습니다.


보이저엑스는 Wan2.1과 ComfyUI, Ray Serve를 결합해 AI 비디오 생성 파이프라인을 구축했습니다. AWS 환경에서 로딩·추론 최적화와 AMI 표준화로 비용 효율과 확장성을 확보했습니다.


Kafka 소비 결과를 Parquet으로 변환해 S3에 적재하는 실시간 수집 파이프라인을 설계하고 구축했습니다. 또한 Flush, 커밋, 모니터링 체계를 통해 누락 없이 안정적으로 운영하는 방법을 정리했습니다.


검색 광고의 랭킹 부스트 기능을 설계하고, 노출 수 예측 대신 순위 상승 보장 방식으로 전환했습니다.\n데이터 수집, Delta Score 계산, Elasticsearch 가중치 주입과 A/B 테스트 검증 과정을 정리했습니다.
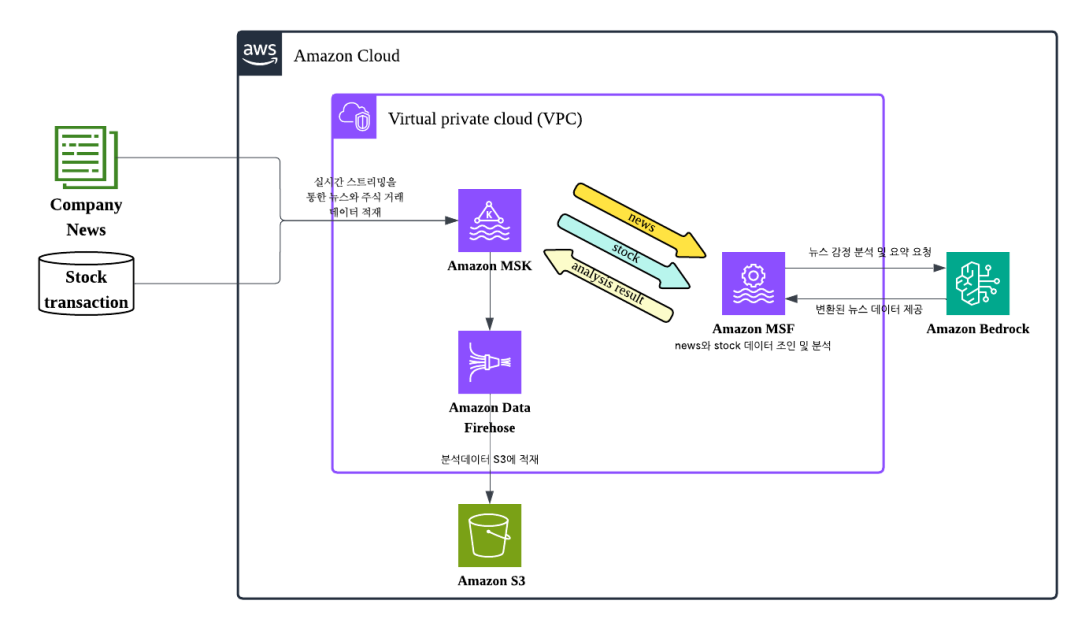
AWS 관리형 서비스로 뉴스와 주가를 실시간 결합해 분석하는 스트리밍 아키텍처를 소개했습니다. Flink, Bedrock, MSK, S3를 연동해 감정 분석과 시계열 분석 흐름을 구성했습니다.

Amazon Bedrock에서 Nova 모델 지식 증류와 온디맨드 배포, 평가 흐름을 실험 사례로 정리했습니다. 표준 벤치마크와 LLM as a Judge를 함께 활용해 성능과 비용 효율을 비교했습니다.

피그마 플러그인 ‘커틀러리’를 직접 만들어 더미 데이터 주입과 레이어 매핑 작업을 자동화한 경험을 공유했습니다. CORS, 이미지 요청 한도, 협업 문서화 과정에서의 시행착오와 해결 과정을 정리했습니다.


AWS Lambda와 S3 트리거로 MediaConvert 변환 작업을 요청하고, 완료 이벤트를 가공해 콜백 API로 전달하는 과정을 설명했습니다. HLS 출력과 썸네일 생성, 환경 변수와 IAM 설정, 데이터 정제 예시까지 함께 정리했습니다.


Airflow와 Databricks로 디자인허브 정산 파이프라인을 리팩토링한 과정을 정리했습니다. 운영 DB 부하를 줄이고 멱등성, 가시성, 협업 체계를 함께 개선했습니다.

LG전자가 Amazon Bedrock으로 소셜미디어 제품 트렌드 모니터링 시스템을 구축한 사례를 다뤘습니다. DeepEval 기반 평가와 모델 비교를 통해 정확도, 속도, 비용을 함께 검증했습니다.