

관계형 데이터베이스만이 답일까? DynamoDB가 보여준 새로운 가능성
삼쩜삼이 대용량 데이터와 트래픽 집중 문제를 해결하기 위해 DynamoDB와 S3로 저장 구조를 분리했습니다. 또한 운영 단계에서 처리량 예열, GSI 설계, 읽기 일관성 대응으로 안정성을 높였습니다.
#DynamoDB#Amazon S3
133005분
삼쩜삼이 대용량 데이터와 트래픽 집중 문제를 해결하기 위해 DynamoDB와 S3로 저장 구조를 분리했습니다. 또한 운영 단계에서 처리량 예열, GSI 설계, 읽기 일관성 대응으로 안정성을 높였습니다.


SmartThings 기록 시스템이 HBase 한계를 극복하기 위해 OpenSearch로 교체했습니다. 읽기 성능은 약 19% 향상되고 쓰기 비용은 약 38% 절감했습니다.

삼성 계정의 리전 단위 장애 대응을 위해 Active-Active DR 아키텍처와 트래픽 전환 체계를 고도화한 사례입니다. Route 53 ARC와 CloudFront를 적용해 잔여 트래픽과 네트워크 지연을 줄였습니다.
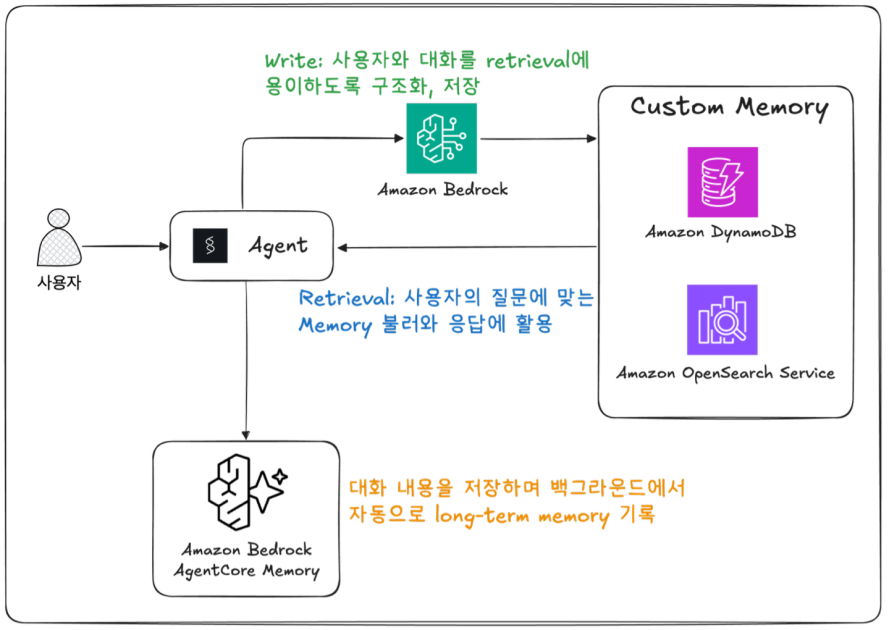
Amazon Bedrock AgentCore Memory와 Custom Memory로 쇼핑 에이전트의 개인화 추천을 구현한 사례를 소개했습니다. 긴 대화 전체보다 중요한 정보만 메모리로 구조화해 더 적은 토큰으로 높은 추천 품질을 얻는 방법을 설명했습니다.

에이전트 서비스의 실행 이력과 툴 매핑을 DynamoDB, Redshift, Valkey로 나눠 설계하는 방법을 설명했습니다. 액세스 패턴 기반 스키마와 분석·캐시 구조로 성능과 추천 정확도를 높이는 방향을 제안했습니다.


AWS CDK로 Vision AI API 서비스를 구축한 실전 경험을 공유했습니다. 스택 분리, 비용 최적화, 모니터링, CI/CD와 장애 대응 방안을 정리했습니다.
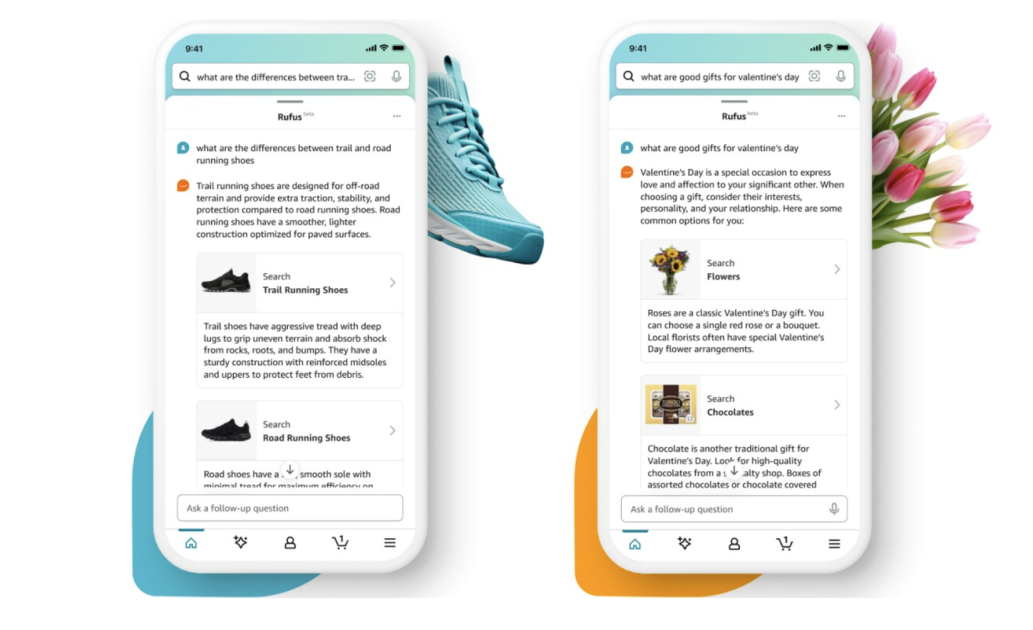
Amazon Bedrock과 AWS 서비스 조합으로 Rufus 같은 쇼핑 어시스턴트를 구현하는 방법을 소개했습니다. Tool 최적화, 컨텍스트 사전 로딩, prompt caching으로 응답 속도를 줄이는 방식을 설명했습니다.


금융 용어를 AI가 쉽게 설명하고 관련 상품까지 추천하는 사전 서비스를 만들었습니다. 응답 지연은 캐싱으로 줄이고, 프롬프트 구조화를 통해 원하는 형식의 답변을 유도했습니다.

DynamoDB 변경 이벤트를 Firehose와 Iceberg S3 Tables로 실시간 복제하는 파이프라인 구성을 소개했습니다. Athena와 QuickSight로 분석 가능한 구조와 권한 설정, 변환 시 주의점까지 정리했습니다.

AWS Bedrock과 Claude 3.5 기반 챗봇으로 뷰티샵 예약과 샵 정보 상담을 자동화했습니다. 스키마, 프롬프트, 세션 관리와 메시지 묶음 처리로 응답 품질과 비용 효율을 함께 개선했습니다.

AWS Instance Scheduler에 한국 공휴일을 자동 반영하는 서버리스 구성을 소개했습니다. 공공데이터포털, Lambda, EventBridge로 스케줄을 자동 전환해 운영 부담과 비용을 줄였습니다.

디프로모션은 성장 과정에서 기존 데이터 구조의 한계를 보완하기 위해 DynamoDB, zero-ETL, ElastiCache Serverless를 도입했습니다. 실시간 동기화와 캐시 최적화로 응답 속도와 운영 효율을 함께 개선했습니다.