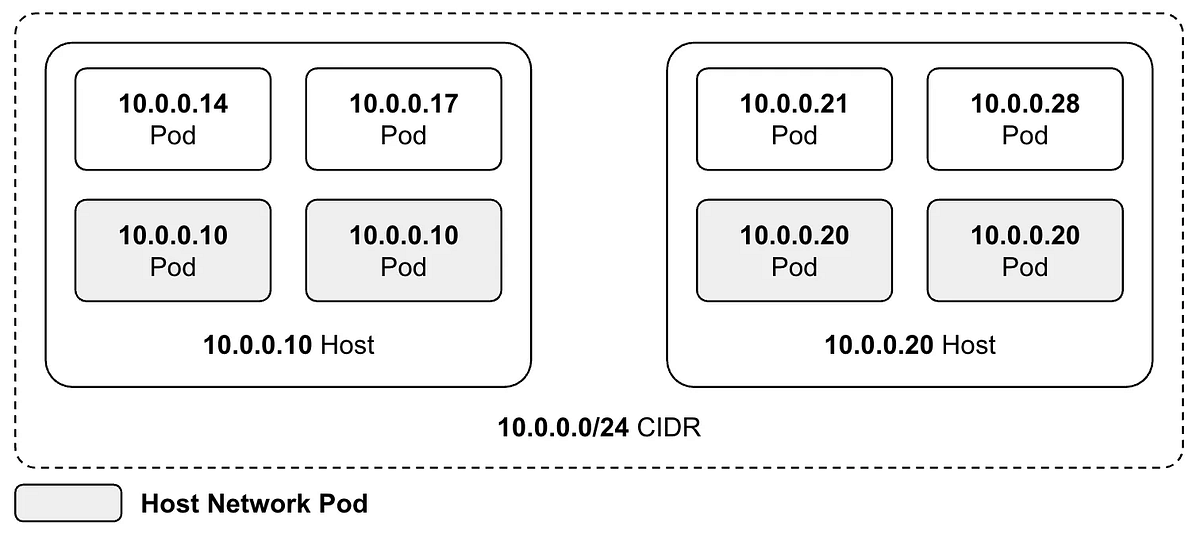
쿠버네티스 파드에 Host Network 도입기
쿠버네티스 파드에 Host Network를 적용한 배경과 효과를 정리했습니다. DaemonSet의 IP 절약과 Job 파드의 생성 지연 개선 사례를 함께 소개했습니다.
#Kubernetes#SRE
118005분
쿠버네티스 파드에 Host Network를 적용한 배경과 효과를 정리했습니다. DaemonSet의 IP 절약과 Job 파드의 생성 지연 개선 사례를 함께 소개했습니다.


카카오페이증권이 고객 관점의 장애 가시화와 대응 자동화를 위해 핑크와드를 구축했습니다. 장애 탐지부터 담당자 호출, 요약, 보고서 작성까지 통합해 대응 시간을 크게 줄였습니다.

서비스의 건강을 수치로 보기 위해 SLI와 SLO를 정의하고 운영하는 방법을 소개했습니다. 29CM 사례를 통해 지표 설계, 모니터링, 지속 개선 체계를 설명했습니다.


AI가 SRE의 역할을 장애 대응 중심에서 예측과 품질 관리 중심으로 바꾸고 있음을 설명했습니다. 메르카리와 AIOps 사례를 통해 AI 신뢰성과 인간 협업의 필요성을 정리했습니다.
AI가 SRE를 장애 대응자에서 예측·자동화 중심의 운영 전략가로 바꾸고 있습니다. 메르카리 사례처럼 품질 검증과 안전장치를 갖춘 인간-AI 협업이 중요합니다.

Kubernetes 기반 마이크로서비스의 가시성을 확보하기 위해 OpenTelemetry와 SigNoz를 활용한 Observability 구축 과정을 정리했습니다. Collector 파이프라인과 Auto-Instrumentation, 운영 효율 개선 포인트를 함께 소개했습니다.


AWS Summit Seoul 2025에서 클라우드 스케일링 자동화와 비즈니스 중심 모니터링 사례를 공유했습니다. 급격한 트래픽에 대비해 분류 기준, 증설 대상, 자동화 흐름을 정리했습니다.


데브시스터즈가 제2회 엔지니어링 데이 - Data를 열고 데이터 조직의 고민과 사례를 공유했습니다. 로그 파이프라인, 준실시간 처리, 게임 DW 공통화와 데이터 활용 경험을 소개했습니다.

예측 가능한 장애를 사전에 검증하기 위해 카오스 엔지니어링을 도입한 사례를 소개했습니다. 특히 mitmproxy로 API 응답에 null을 주입하는 Application Level 테스트 방법을 다뤘습니다.

WhaTap에서 RDS Failover/Reboot 관제를 위해 선행 스크립트로 RDS 목록을 자동 수집하는 방법을 소개했습니다. AWS CLI, 크론, 권한 분리 등 운영 시 주의사항도 함께 정리했습니다.
AWS Cloud9를 개발 테스트용으로 생성하고 Private 네트워크와 SSM으로 접근하는 방법을 안내했습니다. 또한 디스크 리사이즈, 파일 전송, 내부 브라우저 확인 절차를 정리했습니다.
AWS RDS 업그레이드 사례를 순단 시간 기준에 따라 Normal, Near Real Time, B/G Deploy로 나누어 정리했습니다. DMS 복제와 HAProxy, Blue/Green 배포로 점진적 전환과 롤백 방식을 소개했습니다.