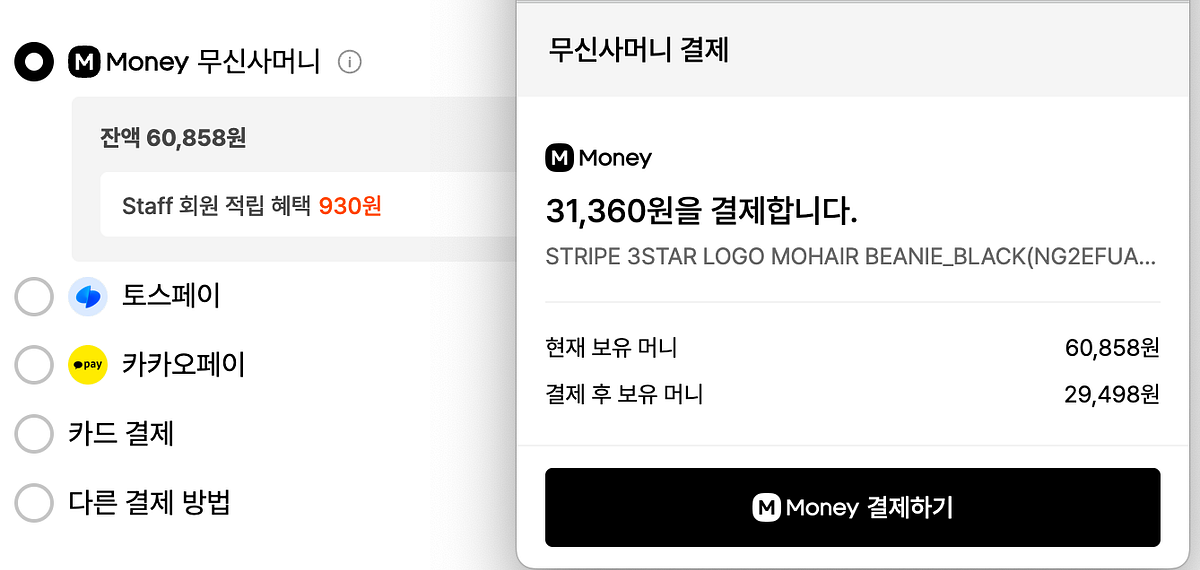
29CM 에서 무신사머니 사용하기
29CM 주문서에 무신사머니를 외부 연동 방식으로 도입하며 안정성과 연속성을 우선해 설계했습니다. 점진적 기능 저하와 서킷 브레이커, 모니터링과 증설 전략으로 운영 안정성을 확보했습니다.
#Spring Boot#Java
119005분
29CM 주문서에 무신사머니를 외부 연동 방식으로 도입하며 안정성과 연속성을 우선해 설계했습니다. 점진적 기능 저하와 서킷 브레이커, 모니터링과 증설 전략으로 운영 안정성을 확보했습니다.

테스트 자동화 환경을 Master Jenkins와 Mac Node 구조로 통합했습니다. IP 변경, 장애 전파, 자원 분산 문제를 줄이고 운영 효율과 안정성을 높였습니다.

Kafka Broker request log와 METADATA API를 활용해 서비스와 Topic 연결을 실시간으로 추적하는 방법을 소개했습니다. ClickHouse, conntrack, Lag metric 조인으로 소스 수정 없이 MSA 관측성을 높였습니다.


검색서비스팀의 SCAR 모니터링 시스템 고도화와 전체 구조를 소개했습니다. 기존 로그 기반 방식의 한계를 짚고, 수집·집계·시각화 분리와 품질 지표 확장을 다뤘습니다.

서비스의 건강을 수치로 보기 위해 SLI와 SLO를 정의하고 운영하는 방법을 소개했습니다. 29CM 사례를 통해 지표 설계, 모니터링, 지속 개선 체계를 설명했습니다.

Nginx 설정을 공통화하고 멀티사이트 구조로 통합한 인프라 개선 사례를 소개했습니다. Promtail과 Loki, Ansible을 연계해 로그 수집과 배포 자동화까지 확장했습니다.

토스증권이 H100 GPU의 자원 낭비를 줄이기 위해 MIG 기반 GPU 가상화를 도입한 과정을 정리했습니다. Kubernetes 연동과 모니터링 설정까지 포함해 운영 관점의 적용 방법을 설명했습니다.

DevLake로 DORA Metrics 수집과 시각화를 도입한 사례를 정리했습니다. Jira 커스텀 필드와 쿼리를 내부 운영 기준에 맞게 조정한 과정도 다뤘습니다.

AWS GPU 스팟 인스턴스와 EKS로 GPU 모니터링 PoC를 구축하는 과정을 정리했습니다. NVIDIA GPU Operator, Prometheus, Grafana로 GPU 메트릭을 수집하고 시각화했습니다.


Playwright로 로그인 세션을 자동 구성한 뒤 Lighthouse를 실행해 인증 페이지 성능 측정을 자동화했습니다. 수집한 지표는 CloudWatch와 Grafana로 연동해 지속적으로 모니터링할 수 있게 했습니다.


CI/CD 옵저버빌리티는 파이프라인 전 과정을 관찰해 병목과 장애 지점을 찾는 접근입니다.\n조직 목표에 맞는 메트릭을 선정하고 모니터링과 알림을 자동화하는 것이 중요합니다.
CI/CD 옵저버빌리티의 개념과 필요성, 구현 방식, 모범 관행을 정리했습니다. 조직 목표에 맞는 메트릭을 정하고 파이프라인 가시성을 높이는 방법을 다뤘습니다.