

AI & Event Driven 오디오 데이터 LinkedIn 글 자동 발행 (feat. Apache Flink)
오디오를 텍스트로 바꾸고 GPT로 LinkedIn 글을 자동 생성하는 이벤트 기반 워크플로를 소개했습니다. 프론트엔드와 AI 처리를 분리해 확장성과 유지보수성을 높인 점이 핵심입니다.
#Next.js#OpenAI API
49005분
오디오를 텍스트로 바꾸고 GPT로 LinkedIn 글을 자동 생성하는 이벤트 기반 워크플로를 소개했습니다. 프론트엔드와 AI 처리를 분리해 확장성과 유지보수성을 높인 점이 핵심입니다.


토스증권은 Nasdaq Smart Options 실시간 시세를 국내에 안정적으로 전송하기 위해 글로벌 인프라와 EKS 기반 소비 구조를 구축했습니다. 또한 Sliding Window Counter와 장애 대응 체계를 적용해 지연과 유실을 줄였습니다.


쿠폰 적용 가능 상품을 실시간으로 조회하기 위해 이벤트 기반 반정규화와 Elasticsearch 인덱싱 구조를 구축했습니다. 복잡한 매핑과 갱신 조건을 단순화하고 검색 성능과 운영성을 함께 개선했습니다.
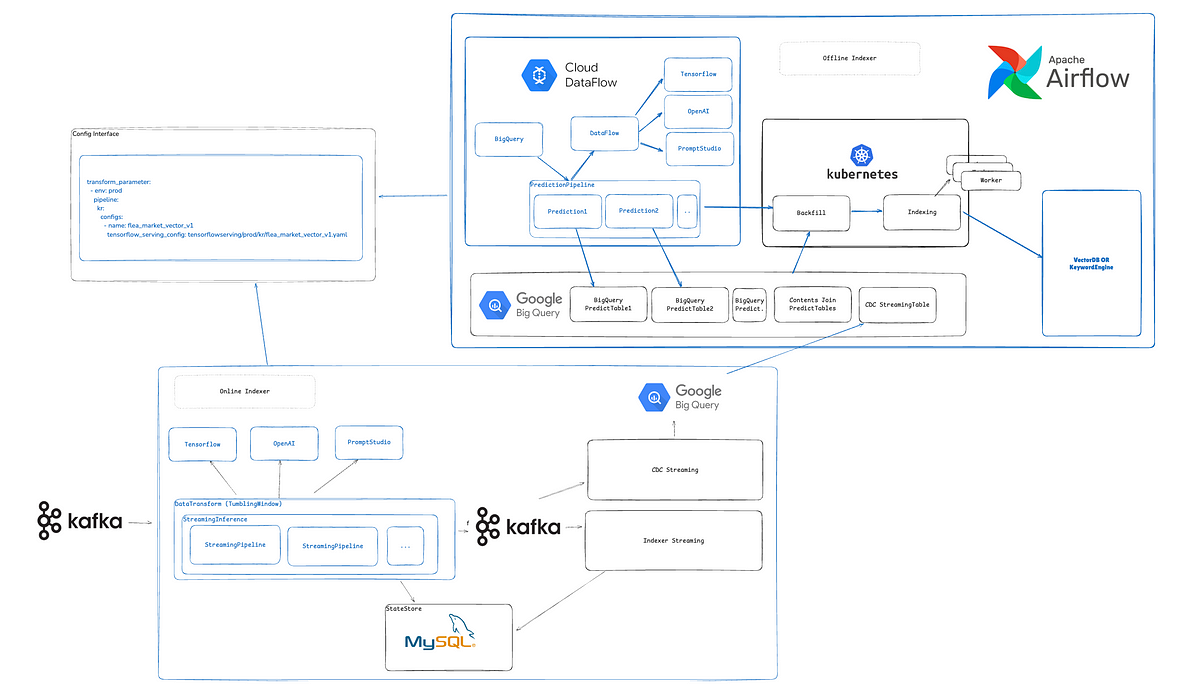
검색 색인 파이프라인의 생산성과 안정성을 높이기 위해 설정 기반 자동화, Offline Storage 활용, 배치 처리 구조를 도입했습니다. 이를 통해 대용량 이벤트와 풀색인 비용 문제를 줄이고 운영 효율을 개선했습니다.

당근은 피드 콘텐츠를 Feed-Entity로 표준화해 여러 서비스의 데이터를 한 구조로 관리했습니다. 수집·변환·검증·서빙을 모듈화하고 지역별 캐시로 읽기 성능과 확장성을 높였습니다.

약관 서버의 DB 부하를 줄이기 위해 Redis 캐시와 강한 일관성 전략을 적용했습니다. 캐시 무효화 실패와 이벤트 순서 문제는 트랜잭션 동기화와 정책으로 해결했습니다.
![[BigData] Spark 개요 정리](https://bespin-wordpress-bucket.s3.ap-northeast-2.amazonaws.com/wp-content/uploads/2025/03/image-10.png)

Spark의 개요와 주요 구성요소, 장점을 정리한 글입니다. 대용량 데이터 처리에서 Pandas보다 Spark가 더 적합한 성능 사례도 비교했습니다.

데이터와 AI의 발전을 두 번의 대전환으로 정리하며, 빅데이터의 양적 성장과 AI 결합의 흐름을 설명했습니다. 데이터 품질, 실시간 처리, 거버넌스의 중요성도 함께 짚었습니다.
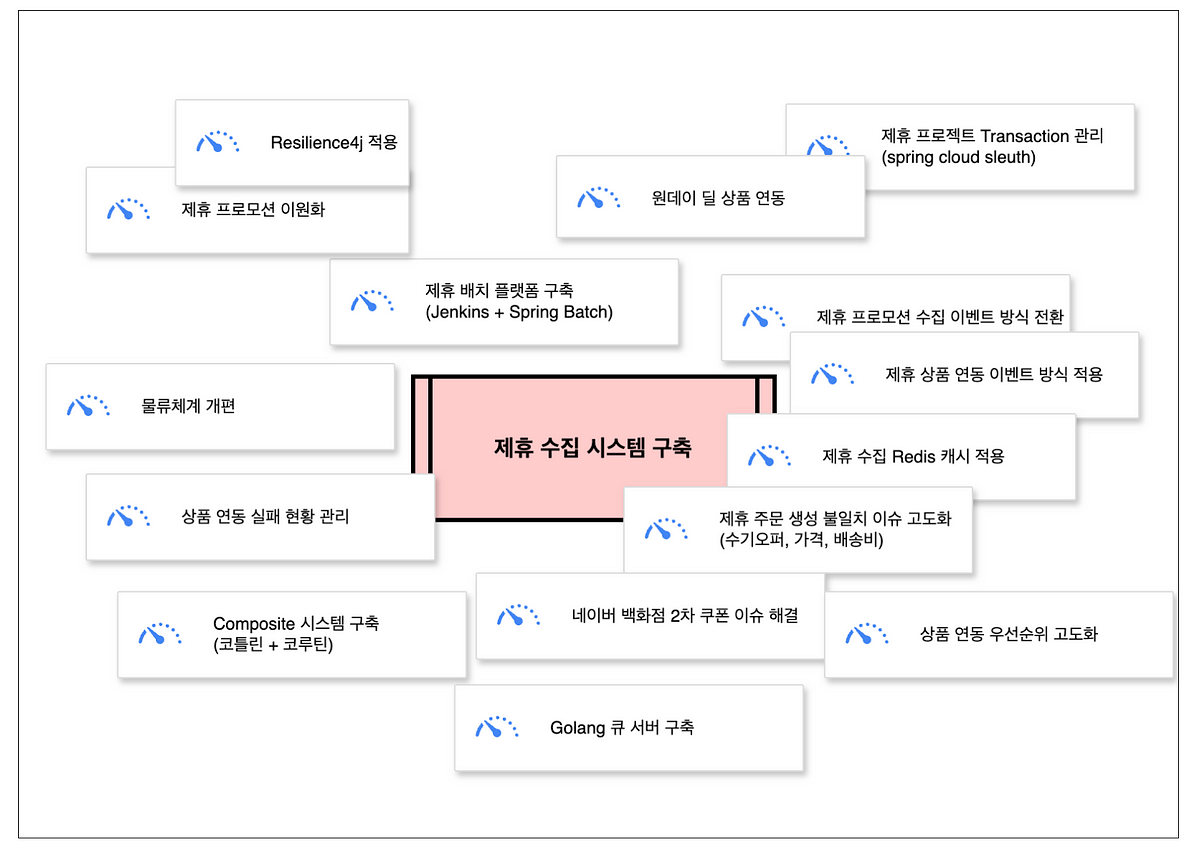

제휴 서비스 수집 시스템의 레거시 한계를 개선해 이벤트 기반, CQRS, Zero Payload 구조로 재설계했습니다.실시간 연동과 부하 분산을 통해 속도, 정합성, 운영 효율을 높인 과정을 공유했습니다.

Elasticsearch 기반 로그 저장 구조의 비용과 확장성 한계를 해결하기 위해 Iceberg 기반 Alaska를 도입했습니다. Kafka 로그를 오브젝트 스토리지에 직접 적재하고, 실시간 조회와 장기 보관을 분리해 운영 효율을 높였습니다.


로그 인리치먼트로 감사로그의 컨텍스트를 보강한 설계와 구현 사례를 다뤘습니다. 비동기 처리, 메타데이터 저장소, S3 적재와 중복 제거 전략을 설명했습니다.
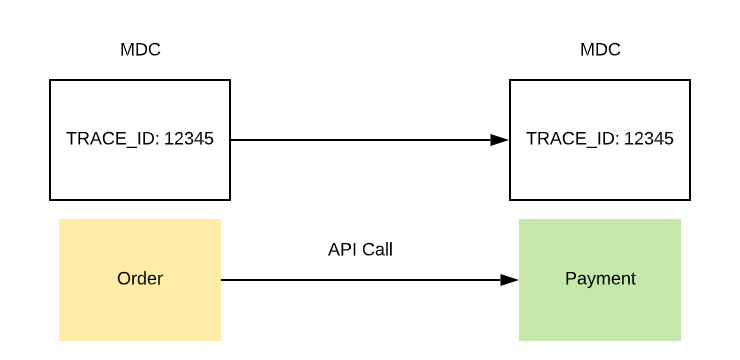

인터페이스 이력 관리 시스템을 AOP와 MDC, Kafka Interceptor로 구현한 과정을 정리했습니다. 멀티스레드 전파와 호출 스택 누락 문제를 여러 차례 개선한 시행착오를 공유했습니다.