
비용, 성능, 안정성을 목표로 한 지능형 로그 파이프라인 도입

비용, 성능, 안정성을 목표로 한 지능형 로그 파이프라인 도입
네이버 Logiss의 로그 파이프라인 운영 문제와 개선 과정을 다뤘습니다. Storm Kafka spout 수정과 멀티 토폴로지 도입으로 비용·성능·안정성을 높이려 했습니다.
#Kafka#Storm
111005분
새로운 기술 블로그가 추가되었어요
네이버 Logiss의 로그 파이프라인 운영 문제와 개선 과정을 다뤘습니다. Storm Kafka spout 수정과 멀티 토폴로지 도입으로 비용·성능·안정성을 높이려 했습니다.

쿠버네티스 기본 배포의 한계를 줄이기 위해 Argo Rollouts로 카나리 배포를 자동화했습니다. Nginx Ingress와 Datadog 연동으로 점진적 전환과 무인 롤백 구조를 구축했습니다.


n8n으로 DevOps·AI 콘텐츠를 자동 수집하고 한국어로 요약하는 워크플로를 구축했습니다. 수집·요약 분리, 중복 방지, 에러 모니터링까지 운영 관점의 구현 방법을 정리했습니다.

Grafana OnCall과 Amazon Connect를 연동해 Target Group 비정상 상태를 자동 감지하고 전화 알림까지 연결한 온콜 시스템 구축 사례입니다. 비용을 줄이면서도 담당자 식별, 알림 제어, 에스컬레이션을 하나의 흐름으로 묶었습니다.
OpenTelemetry와 Kafka를 활용해 마이크로서비스 환경의 Observability 파이프라인을 구축한 사례를 소개했습니다.\n자동 계측, 중앙 Collector, Signal별 분리로 안정성과 확장성을 높였습니다.
Elasticsearch 롤링 재시작 시 캐시 미준비 노드로 트래픽이 유입돼 지연과 장애가 발생하는 문제를 다뤘습니다. search-coordinator 프록시로 워밍업 완료 노드에만 검색 트래픽을 보내는 구조를 소개했습니다.
AI 인프라를 하이브리드 구조로 재설계해 비용과 운영 리스크를 줄인 사례를 다뤘습니다. Cilium, NLB, OpenTelemetry, Gateway API로 지연과 확장성을 함께 최적화했습니다.
Elasticsearch 데이터 노드 재시작 시 캐시 미적재로 레이턴시가 급증하는 문제를 다뤘습니다. search-coordinator와 웜업 절차로 배포 중에도 안정적으로 트래픽을 받도록 개선했습니다.


AWS DMS의 Data Resync 기능으로 마이그레이션 중 데이터 불일치를 자동으로 수정하는 방법을 소개했습니다. Full load와 CDC 작업에서의 구성 방식과 운영 시 주의점도 함께 설명했습니다.
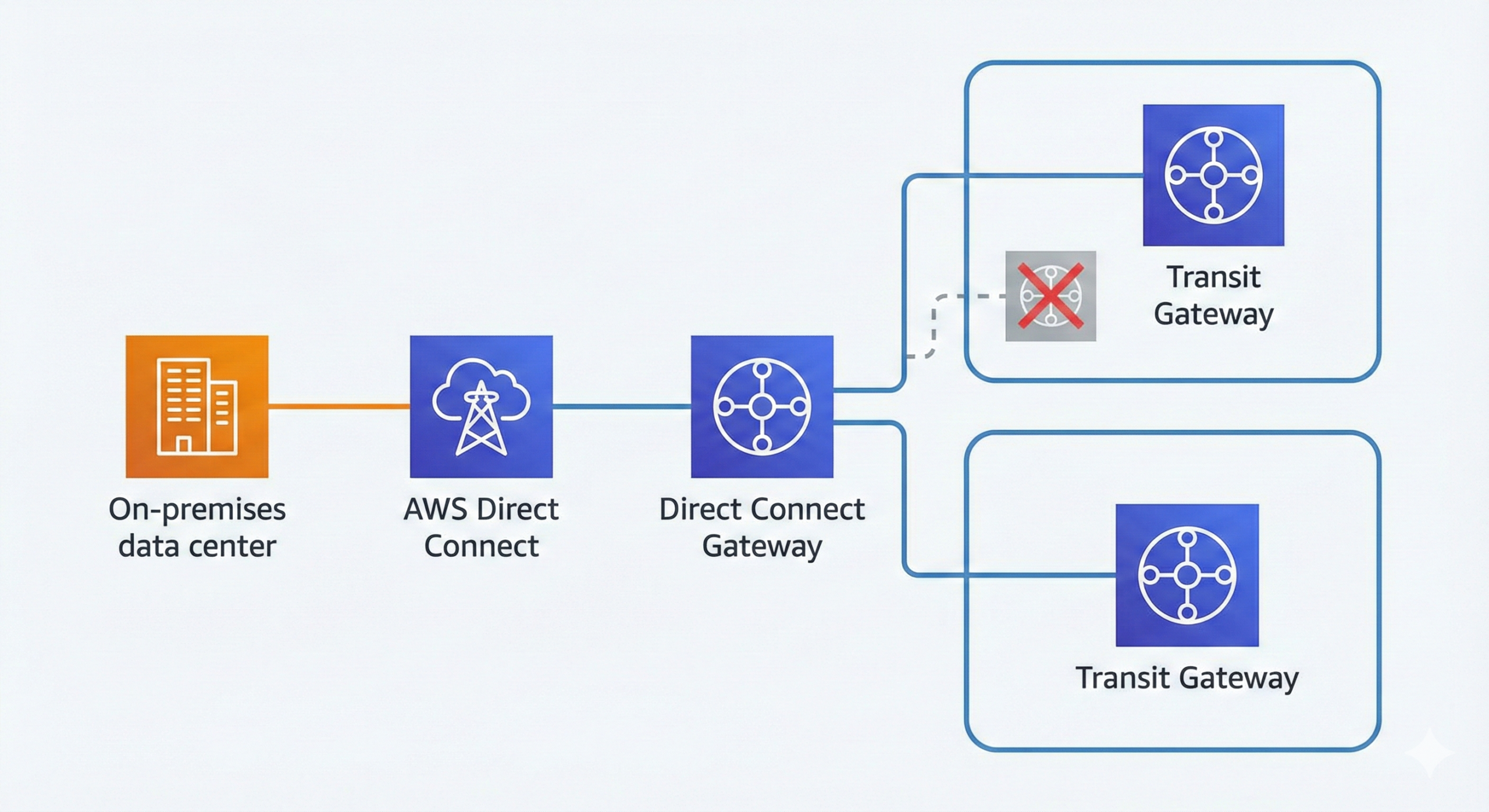

여러 계정의 TGW를 하나의 DXGW에 연결해도 동일 리전에서는 실제로 하나만 동작했습니다. 리전당 TGW 1개 제약을 고려해 단일 TGW 중심으로 구조를 단순화했습니다.
EKS에서 EBS 볼륨의 AZ 종속성 때문에 파드 어태치 실패가 발생하는 사례를 정리했습니다. 멀티 AZ가 필요하면 Affinity로 고정하거나 EFS로 전환하는 방식이 핵심입니다.
Amazon Linux 1 지원 종료로 EKS 노드그룹 전환이 필요해졌습니다. 운영 구조를 유지하려면 새 노드그룹 교체가 기본 전략이 되고, 필요 시 신규 클러스터도 고려해야 했습니다.