


올리브영 전시영역 MongoDB 도입하기
전시영역의 비규칙적인 데이터 구조를 개선하기 위해 MongoDB를 도입한 사례를 소개했습니다. 문서지향 저장과 버저닝으로 관리 효율과 롤백 안정성을 높였습니다.
#MongoDB#NoSQL
58005분
새로운 기술 블로그가 추가되었어요
전시영역의 비규칙적인 데이터 구조를 개선하기 위해 MongoDB를 도입한 사례를 소개했습니다. 문서지향 저장과 버저닝으로 관리 효율과 롤백 안정성을 높였습니다.
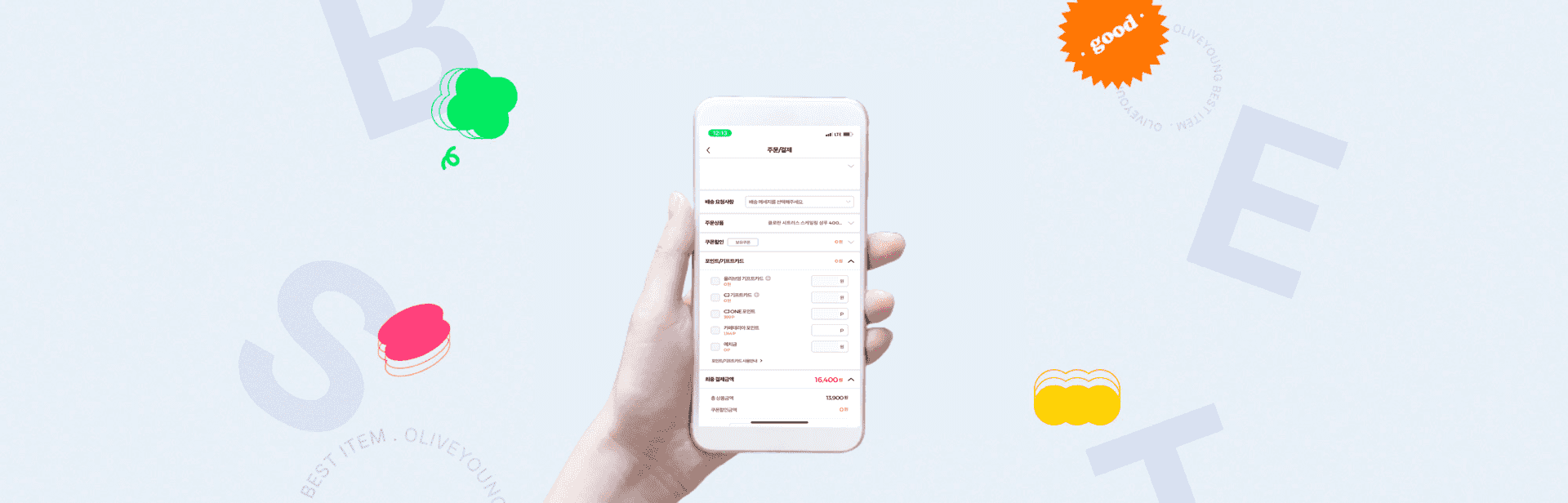
주문 완료 과정의 단일 트랜잭션 구조로 인해 동시 구매 시 DB Lock과 Dead Lock이 발생했습니다. 트랜잭션을 개별 분리한 뒤 부하 테스트와 운영 모니터링으로 성능 개선을 검증했습니다.


CockroachDB를 쿠키런: 킹덤의 메인 데이터베이스로 선택한 이유와 운영 시 고려할 점을 정리했습니다. 분산 구조, 복제, MVCC, 핫스팟 대응 같은 핵심 개념도 함께 설명했습니다.


리워드 광고 플랫폼 성장에 따라 MySQL 기반 광고 서버의 수평 확장 한계가 드러났습니다. 이를 해결하기 위해 엘라스틱서치로 전환해 타게팅과 송출 구조를 개선했습니다.
![[if kakao 2022] Batch Performance를 고려한 최선의 Aggregation](https://tech.kakaopay.com/_astro/thumb.84295604_1klCAm.png)

대량 데이터를 집계하는 배치에서 성능을 고려한 aggregation 설계 노하우를 다룬 글입니다. 배치 처리 효율을 높이기 위한 접근을 공유합니다.
![[if kakao 2022] Batch Performance를 고려한 최선의 Reader](https://tech.kakaopay.com/_astro/thumb.f4bb869d_1nQPYR.png)
대량 데이터를 배치로 읽을 때의 성능 고려와 Reader 선택 노하우를 공유합니다.\n배치 처리 특성에 맞는 읽기 방식과 성능 관점을 정리했습니다.

무형상품 서비스에 글로벌 캐시를 적용한 배경과 구성을 정리했습니다. Spring Boot와 Redis 기반 `@Cacheable`로 조회 성능을 높이는 방법을 설명했습니다.

DB Trigger를 제거하고 Kafka 기반 비동기 분산처리로 전환하는 과정에서 재시도 로직을 구현한 사례를 소개했습니다. Spring Cloud Stream을 이용한 적용 과정을 기술적으로 공유했습니다.


십수년간 운영된 오라클 DB Function 기반 프로모션 조회를 Java API로 전환한 사례를 공유했습니다. 장애 대응, 테스트, 유지보수, 트래픽 분산 한계를 해결하고 성능 개선까지 목표로 삼았습니다.


스토리지 엔진의 사용 언어를 C/C++에서 Go로 변경한 과정을 소개했습니다. Cgo를 거쳐 Go로 옮겨가는 전환 흐름을 중심으로 다뤘습니다.

Elasticsearch 색인 구조를 Kafka와 Debezium 기반 이벤트 처리로 전환한 사례를 소개했습니다. ECK를 함께 적용해 색인 속도와 운영 안정성을 함께 높였습니다.


Hive 사용량 통계를 수집해 하둡 플랫폼 운영 효율을 높인 개발 사례를 소개했습니다. 크롤링 한계를 로그 분석과 실시간 처리 구조로 개선하고 Iceberg 적재 방식도 조정했습니다.