

컬리의 BigQuery 도입기 - 2부
BigQuery 도입으로 정형·비정형 데이터 파이프라인을 분리해 구축하고, CDC 기반 적재와 Merge Procedure로 원본 정합성을 맞췄습니다. 또한 데이터 레이크하우스화, 쿼리 성능 개선, 비용 절감 효과를 얻었습니다.
#BigQuery#Kafka
27005분
새로운 기술 블로그가 추가되었어요
BigQuery 도입으로 정형·비정형 데이터 파이프라인을 분리해 구축하고, CDC 기반 적재와 Merge Procedure로 원본 정합성을 맞췄습니다. 또한 데이터 레이크하우스화, 쿼리 성능 개선, 비용 절감 효과를 얻었습니다.
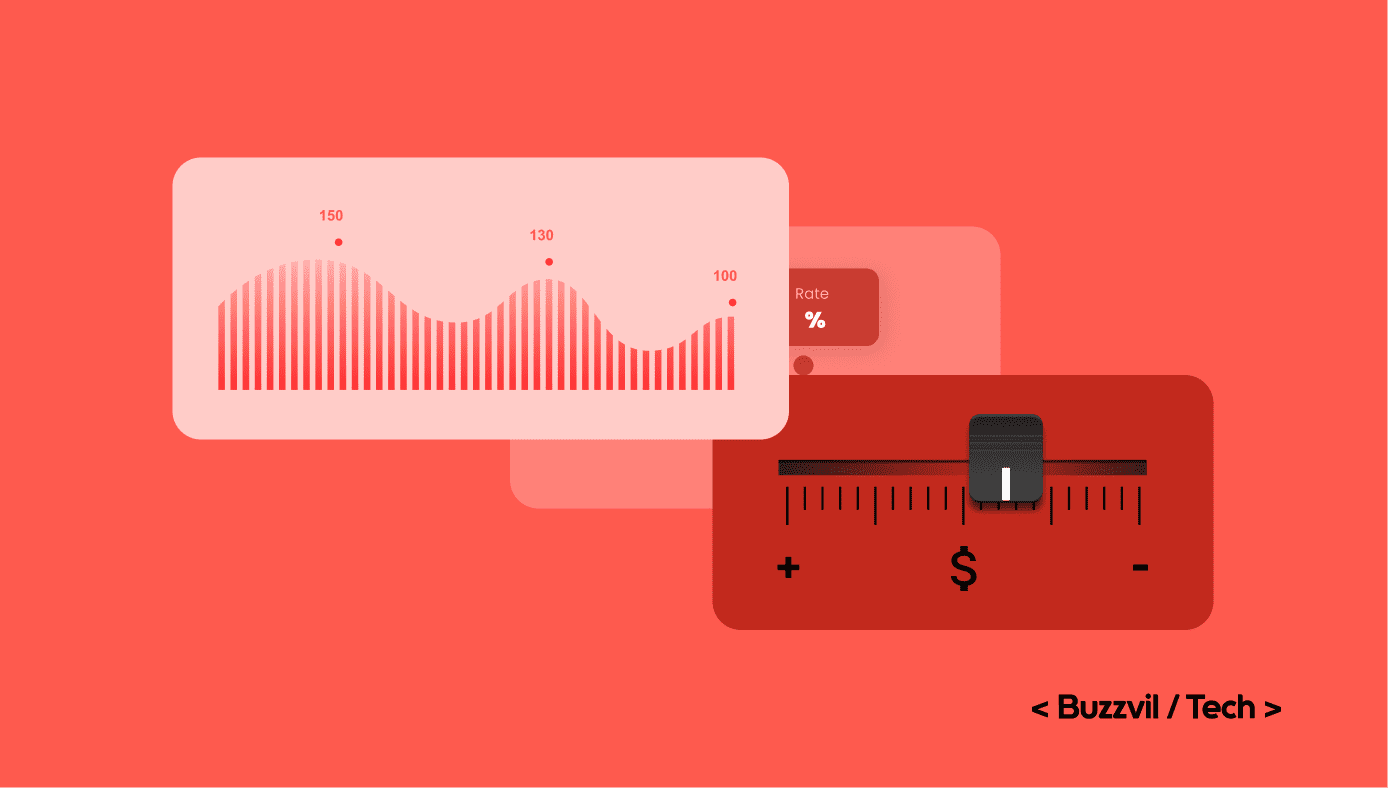

광고 예산 제어 시스템을 더 정교하게 개선한 사례와 그 성과를 소개했습니다. 예산을 더 자주, 더 세밀하게 통제하는 방향으로 문제를 풀었습니다.

레거시 Redirect 서버를 Spring Boot 기반으로 리팩토링해 클릭 요청, 캐시, 로그 구조를 개선했습니다. 푸시 연동과 Short URL 처리까지 통합해 확장 가능한 형태로 설계했습니다.
Elasticsearch의 페이지네이션 방식으로 Scroll API와 Search After를 비교해 성능을 점검했습니다. 대용량 조회에서는 병렬 처리와 PIT 조합이 중요하며, 사용 목적에 따라 방식을 선택해야 했습니다.


DataHub의 Protobuf nested message 주석 미표시 문제를 원인 분석 후 코드와 테스트로 수정했습니다. 오픈소스 기여 과정에서 Slack 커뮤니케이션과 Checkstyle 대응도 함께 경험했습니다.

광고 플랫폼의 예산 제어 시스템을 개선하는 연재의 첫 글입니다. 캠페인 예산을 안정적으로 분배하지 못하면 조기 소진과 지출 스파이크가 발생할 수 있음을 다뤘습니다.
기존 데이터 파이프라인의 지연과 복잡성을 줄이기 위해 컬리가 BigQuery 도입 배경과 주안점을 정리했습니다. 스트리밍 적재, 파티션 관리, 프로젝트 분리로 성능과 비용을 함께 고려했습니다.
FCM 푸시의 TOKEN, TOPIC 개념과 발송 흐름을 정리하고 서버 설계 사례를 소개했습니다. 또한 멀티 FirebaseApp 관리, iOS APNs 이슈, FCM의 한계점까지 함께 다뤘습니다.
.png)

GraphQL Federation의 개념을 설명하고 여러 GraphQL 서비스를 통합하는 방법을 소개했습니다. Apollo Federation을 이용한 구현 방향을 함께 다뤘습니다.


동시성 프로그래밍의 핵심 개념을 여러 언어 예시로 비교하며 정리했습니다. 쓰레드, 쓰레드 풀, 경량쓰레드, Promise/Future, Async-Await의 관계와 활용 차이를 설명했습니다.


마이크로 서비스 환경에서 흩어진 API 문서를 OpenAPI로 통일해 공용 문서 서버를 구축했습니다. GitHub Action과 S3로 배포마다 문서를 자동 갱신해 관리 부담을 줄였습니다.
트렌비는 UI 테스트의 속도와 유지보수 한계를 보완하기 위해 API 테스트 자동화를 도입했습니다. Python Requests와 GitHub Actions로 핵심 유저 시나리오를 검증하고 배포 검증 효율을 높였습니다.