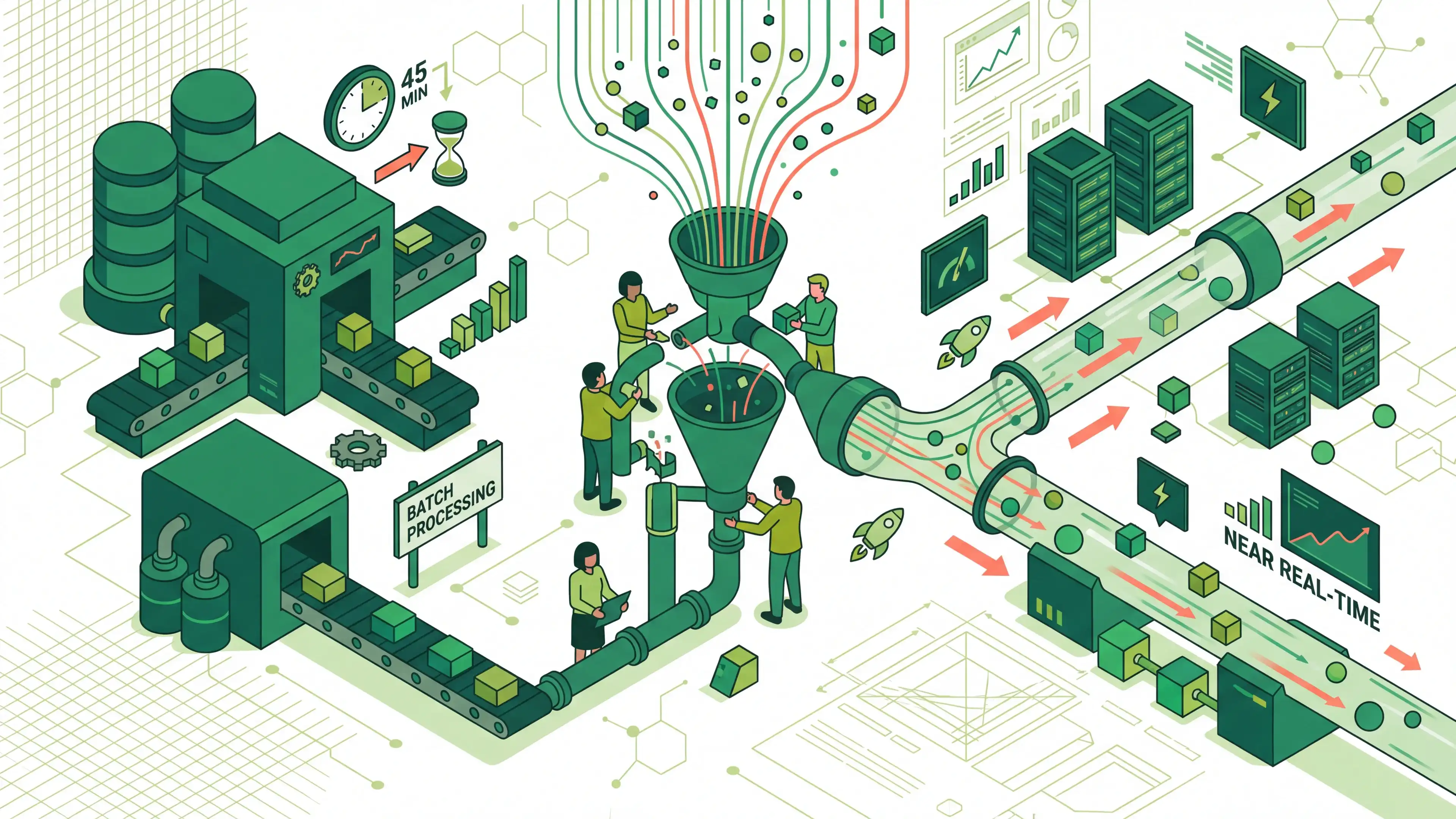

45분 배치에서 준실시간으로! 다수 도메인 데이터를 Kafka로 통합한 전환기
상품·쿠폰·증정·프로모션 데이터를 Kafka 기반 준실시간 구조로 전환한 사례입니다.\nRedis Pub/Sub, Aggregation Topic, Shadow Table로 정합성과 안전한 이관을 확보했습니다.
#Kafka#Redis
267005분
상품·쿠폰·증정·프로모션 데이터를 Kafka 기반 준실시간 구조로 전환한 사례입니다.\nRedis Pub/Sub, Aggregation Topic, Shadow Table로 정합성과 안전한 이관을 확보했습니다.


Amazon DocumentDB 전환 후 발생한 인덱스와 쿼리 성능 문제를 실제 사례로 정리했습니다. explain, profiler, 인덱스 재설계와 쿼리 변경으로 성능을 개선했습니다.

미리캔버스는 MongoDB Atlas의 IOPS 병목과 비용 문제를 해결하기 위해 Amazon DocumentDB로 전환했습니다. 그 결과 응답속도는 50% 개선되고 인프라 비용은 30% 절감했습니다.

퀸잇 검색 시스템이 MySQL LIKE에서 시작해 Elasticsearch, 벡터 검색, RRF를 거친 하이브리드 구조로 진화한 과정을 정리했습니다. 성능과 품질, 복잡도의 균형을 실험과 장애 대응으로 개선한 사례를 담았습니다.
Spring Boot Startup Time을 90초에서 30초로 줄인 6단계 최적화 과정을 정리했습니다. 프로파일링으로 원인을 찾고, Spring 내부 동작과 오픈소스 패치까지 활용해 병목을 해소했습니다.


Slurm의 내부 구조와 Job 처리 흐름을 중심으로 HPC 스케줄러 활용법을 정리했습니다. 대화형·배치·배열 작업과 QOS, Fairshare, 선점, 의존성 연결까지 실무 패턴을 설명했습니다.
![[미래를 담아낸 뼈대 7/7] 의존성의 방향을 따라](https://flex.team/blog/og/main.jpg)

의존성 그래프를 따라 레포 간 마이그레이션을 자동화하는 Evergreen 구조를 소개했습니다. 빌드 검증과 AI 보조로 버전업과 패치 전파를 빠르게 만드는 방식입니다.
![[미래를 담아낸 뼈대 7/7] 의존성의 방향을 따라](https://cdn.sanity.io/images/v31psllp/production/85a2456afffb0f96fb7c09ce89e31b7ad3400ab7-1684x1030.png)
의존성 그래프를 따라 마이그레이션을 자동 전파하는 Evergreen 구조를 소개했습니다. 표준화된 빌드 규칙과 AI 보조로 대규모 버전업을 빠르게 처리했습니다.

Hive 기반 전체 재작성 ETL의 한계를 Iceberg와 Flink로 개선한 사례를 소개했습니다. 체크포인트, 2PC, 파티셔닝 최적화로 데이터 반영 속도를 12배 높였습니다.

C++ 객체 수명과 암묵적 객체 생성 규칙을 정리하며 reinterpret_cast 사용 시의 UB 가능성을 설명했습니다. C++20의 표준 수용 범위와 std::launder, placement new의 역할도 함께 다루었습니다.
C++에서 타입 퍼닝과 포인터 변환에 `std::bit_cast`와 `reinterpret_cast`를 어떻게 구분해 써야 하는지 정리했습니다. 엄격한 앨리어싱 규칙과 포인터↔정수 변환의 의미론도 함께 설명했습니다.

기획서가 없는 블랙박스 시스템을 내재화하며, 입력·출력 정의와 병렬 검증으로 동일성을 증명했습니다. Kafka와 CDC, OpenSearch를 활용해 조회·업데이트·E2E 전환을 안전하게 검증했습니다.