
당근에서 정보 유실 없이 업체 정보를 모으는 방법
여러 경로로 모은 업체 정보의 중복을 병합으로 정리하고, 변경 이력을 바탕으로 대표 프로필의 값을 고도화했습니다. 필드별 정책을 분리해 더 합리적인 정보를 노출하도록 개선했습니다.
#Kotlin#refactoring
135005분
새로운 기술 블로그가 추가되었어요
여러 경로로 모은 업체 정보의 중복을 병합으로 정리하고, 변경 이력을 바탕으로 대표 프로필의 값을 고도화했습니다. 필드별 정책을 분리해 더 합리적인 정보를 노출하도록 개선했습니다.

실거리 기반 배차 정확도를 높이기 위해 OSRM, Kafka, Redis를 활용한 저장·처리 구조를 설계했습니다. 지역 단위 이벤트 순서 보장과 캐시 재사용으로 대량 경로 계산 부하를 줄였습니다.
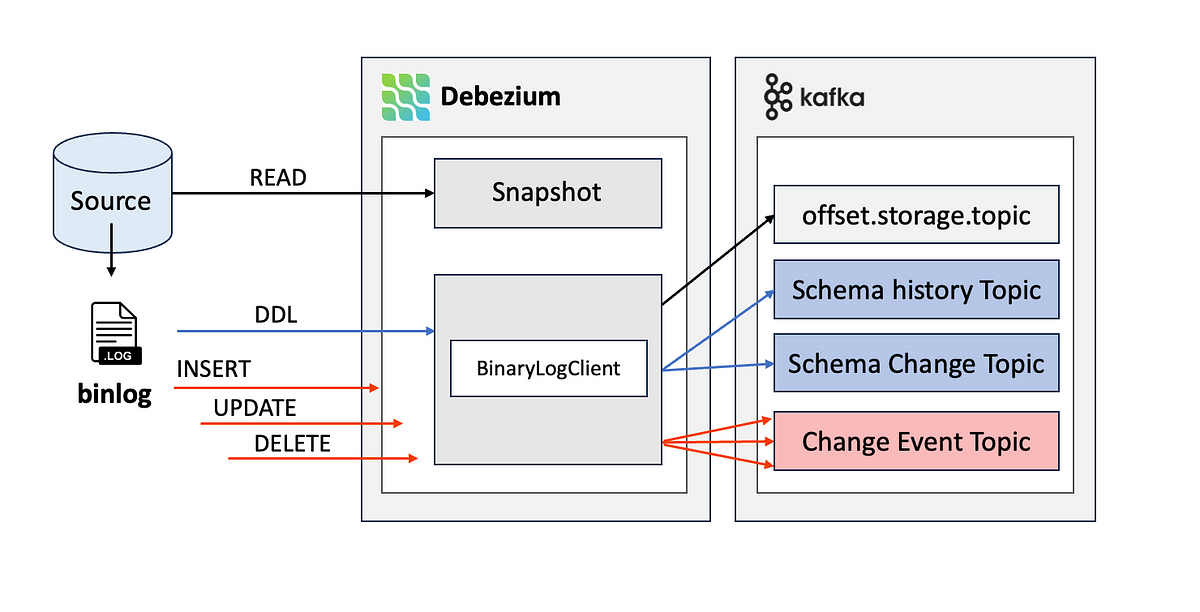

기존 배치 적재의 지연을 줄이기 위해 Debezium 기반 실시간 CDC 파이프라인을 구축한 과정을 정리했습니다. Kafka Connect 구조, 스냅샷, 오프셋 관리와 성능 개선 포인트까지 살펴보았습니다.

플레이스 조회 트래픽 증가로 메인 DB 부담이 커져 Elasticsearch를 조회용 DB로 분산한 사례를 공유했습니다. 조회 DB 선택 이유부터 점진적 도입, 자동 fallback, 운영 팁까지 정리했습니다.


결제 도메인의 오류 처리를 위해 sealed class를 검토한 뒤 Arrow의 Either를 도입한 과정을 정리했습니다. 트랜잭션, 캐시, 예외 처리와의 충돌을 피하기 위해 계층별 경계도 함께 설계했습니다.
ADVoost Shopping의 실시간 유효 광고 선정을 위한 Flink와 Paimon 아키텍처를 소개합니다. Paimon의 기능과 Iceberg 비교, 운영 팁까지 정리했습니다.

결제 시스템 DB를 Nbase-T에서 Vitess로 옮기기 위해 ShardingSphere와 TiDB, Vitess를 PoC로 비교했습니다. 성능과 비용의 균형, 운영 경험을 고려해 Vitess를 최종 선정했습니다.


Python의 `olefile`과 `zlib`로 HWP `DocInfo`를 읽고, 레코드 헤더를 분해해 문서 속성·BinData·글꼴 정보를 파싱하는 방법을 설명했습니다. 또한 가변 길이 데이터와 확장 크기 처리로 HWP의 레코드 기반 구조를 이해할 수 있게 정리했습니다.
HWPX를 ZIP 기반 XML 포맷으로 보고 Python 내장 라이브러리로 메타정보를 추출하는 방법을 설명했습니다. 문서 시작 번호, 커서 위치, 바이너리 목록을 `Document` 객체로 구조화하는 흐름을 다뤘습니다.

Node.js는 싱글스레드처럼 보이지만 내부적으로는 멀티스레드 요소를 활용하는 구조를 설명했습니다. 대용량 데이터 처리에서는 CPU 병목을 스케일아웃과 운영 설계로 풀어낸 사례를 다뤘습니다.


DynamoDB 변경 이벤트를 Firehose와 Iceberg S3 Tables로 실시간 복제하는 파이프라인 구성을 소개했습니다. Athena와 QuickSight로 분석 가능한 구조와 권한 설정, 변환 시 주의점까지 정리했습니다.

Amazon RDS for PostgreSQL과 Aurora PostgreSQL에서 동적 데이터 마스킹을 구현하는 방법을 소개했습니다. 역할 기반 마스킹 뷰와 관련 구성요소, 그리고 적용 시 한계도 함께 설명했습니다.