![[운영가이드] Kubernetes 기반 Fault-Tolerant GPU 클러스터 유지 관리](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fk8pIT%2FdJMcahECjfo%2FAAAAAAAAAAAAAAAAAAAAAIExdCaiKX0378yRRp3c1JOba2jDMlKxI4gPyW5ERxiM%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DEzYyuyMX4AaXtQ4s%252BARKBCrpyzc%253D)

[운영가이드] Kubernetes 기반 Fault-Tolerant GPU 클러스터 유지 관리
Kubernetes 기반 GPU 클러스터를 안정적으로 운영하기 위한 유지 관리 방안을 정리했습니다. 자동화, 관측, 스케줄링 통합, 네트워크·보안 분리를 통해 장애 대응과 성능 안정성을 높이는 방법을 소개했습니다.
#Kubernetes#GPU
7005분
Kubernetes 기반 GPU 클러스터를 안정적으로 운영하기 위한 유지 관리 방안을 정리했습니다. 자동화, 관측, 스케줄링 통합, 네트워크·보안 분리를 통해 장애 대응과 성능 안정성을 높이는 방법을 소개했습니다.


온프레미스 HPC 클러스터를 8단계로 쌓는 순서와 의존성을 정리했습니다. 기본 설정, GPU 스택, 스토리지, 스케줄러, 모니터링, 자동화가 핵심입니다.

Slurm의 내부 구조와 Job 실행 흐름을 설명하며 HPC에서의 자원 관리 방식을 정리했습니다. 또한 대화형 작업, 배치 학습, Job 배열, QOS와 Fairshare 활용법을 실무 예제로 소개했습니다.
Slurm의 내부 구조와 Job 처리 흐름을 중심으로 HPC 스케줄러 활용법을 정리했습니다. 대화형·배치·배열 작업과 QOS, Fairshare, 선점, 의존성 연결까지 실무 패턴을 설명했습니다.
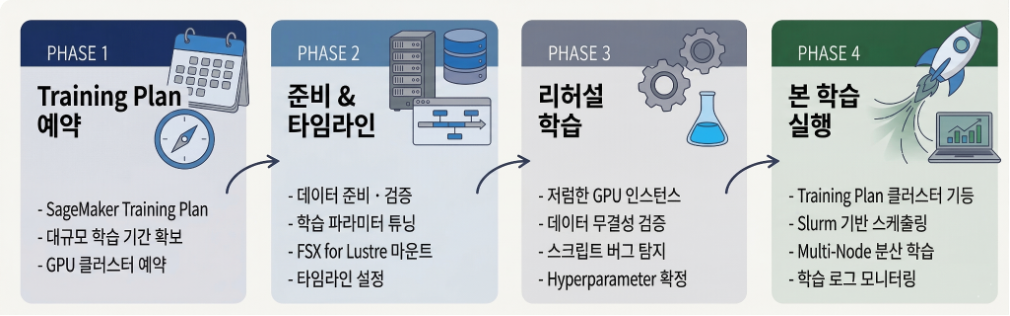

슈퍼브에이아이가 SageMaker HyperPod로 ZERO 모델의 대규모 분산 학습 효율을 높인 사례를 소개했습니다. 저가 리허설과 데이터 사전 로드로 비용과 학습 지연을 줄였습니다.

EKS에서 Slinky로 Slurm을 배포하는 방법과 구성 요소를 소개했습니다. Kubernetes와 Slurm을 함께 써서 AI·HPC 워크로드를 효율적으로 운영하는 방안을 정리했습니다.

AI 모델 개발에서 GPU를 효율적으로 쓰기 위한 HPC의 필요성과 기본 구성요소를 설명했습니다. Slurm, 공유 스토리지, 컨테이너를 통해 대규모 학습 환경을 일관되게 운영하는 방법을 소개했습니다.