CDC가 데이터 플랫폼을 바꾸는 방식: CDC-based Incremental Replication

CDC가 데이터 플랫폼을 바꾸는 방식: CDC-based Incremental Replication
전수 적재의 지연과 정합성 문제를 해결하기 위해 CDC 기반 증분 복제 파이프라인을 설계했습니다. 전체 로우 해시와 사후 검증으로 멱등성과 신뢰도를 높이고, 시간 단위 배치로 최신성을 개선했습니다.
#CDC#Apache Iceberg
0005분
전수 적재의 지연과 정합성 문제를 해결하기 위해 CDC 기반 증분 복제 파이프라인을 설계했습니다. 전체 로우 해시와 사후 검증으로 멱등성과 신뢰도를 높이고, 시간 단위 배치로 최신성을 개선했습니다.
Karrot가 MongoDB 적재 방식의 한계를 해결하기 위해 CDC를 도입한 과정을 공유했습니다. 변경 로그 기반으로 BigQuery 적재를 구성하되, 초기 스냅샷은 별도 도구 활용을 검토했습니다.
MongoDB 덤프의 DB 부하와 SLO 문제를 해결하기 위해 CDC를 도입했습니다. Flink CDC와 Spark, 이중 테이블 구조로 적재와 스키마 변경, 정합성 검증을 묶었습니다.
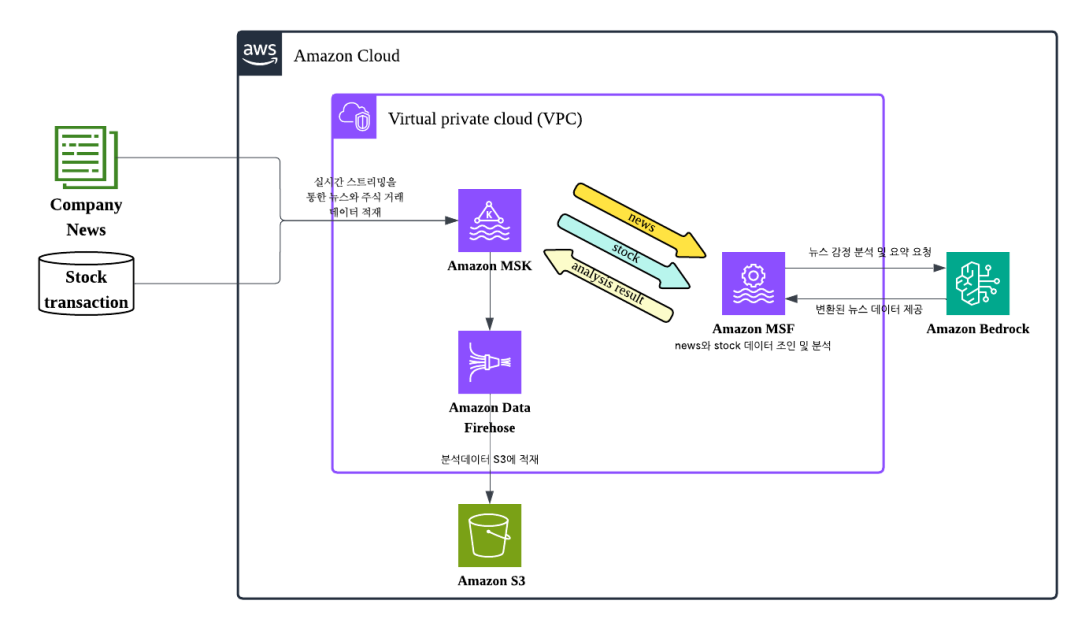

AWS 관리형 서비스로 뉴스와 주가를 실시간 결합해 분석하는 스트리밍 아키텍처를 소개했습니다. Flink, Bedrock, MSK, S3를 연동해 감정 분석과 시계열 분석 흐름을 구성했습니다.

토스증권은 수천 개 실시간 데이터 파이프라인을 DAG 리니지 시각화로 관리했습니다.\nMongoDB Graph Search 기반 탐색과 상세 정보 제공으로 운영 효율과 커뮤니케이션 비용을 줄였습니다.

실시간 마케팅을 위해 SNS-Lambda-Kinesis-Flink-DB 파이프라인 PoC를 진행했습니다. 12k RPS 목표를 기준으로 병목을 찾아 SQS 추가와 Flink 최적화로 개선했습니다.


오디오를 텍스트로 바꾸고 GPT로 LinkedIn 글을 자동 생성하는 이벤트 기반 워크플로를 소개했습니다. 프론트엔드와 AI 처리를 분리해 확장성과 유지보수성을 높인 점이 핵심입니다.


Flink 어플리케이션의 end-to-end latency 병목을 찾기 위해 operator 지표와 flame graph를 활용하는 방법을 소개했습니다. 처리 시간과 처리 외 시간을 분리해 관측하고, 병목 유형별로 다른 개선 방향을 제시했습니다.
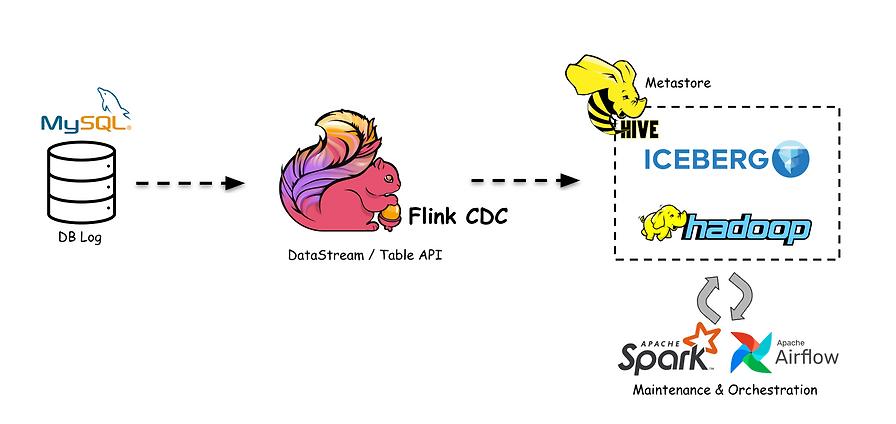

Apache Iceberg와 Flink CDC를 다루는 심층 탐구 글입니다. 발췌만으로는 구체적 내용 확인이 어려워 핵심 주제만 요약했습니다.