![[Tech Series] kt cloud AI 검색 증강 생성(RAG) #4 : 임베딩(Embedding)과 벡터 인덱싱 기술](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fn6a0Z%2FdJMcacWKKeh%2FAAAAAAAAAAAAAAAAAAAAAIdjQntIXbTdvMG54_-sZ7V6TbWffZFi4hNxV3nyIWrO%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DrVslgOQRjGesCsglq1mAxQlFuFo%253D)

[Tech Series] kt cloud AI 검색 증강 생성(RAG) #4 : 임베딩(Embedding)과 벡터 인덱싱 기술
RAG에서 임베딩과 벡터 인덱싱의 원리, 모델 선정 기준, 최적화 기법을 정리했습니다. 특히 한국어 환경에서는 다국어 적합성과 메모리 비용을 함께 검증해야 한다고 설명했습니다.
#RAG#임베딩
78005분
RAG에서 임베딩과 벡터 인덱싱의 원리, 모델 선정 기준, 최적화 기법을 정리했습니다. 특히 한국어 환경에서는 다국어 적합성과 메모리 비용을 함께 검증해야 한다고 설명했습니다.


한국어 텍스트와 이미지를 함께 처리하는 멀티모달 임베딩 모델 개발기를 소개했습니다. 자연어 기반 사진 검색과 유사 상품 추천 사례를 중심으로 설명했습니다.
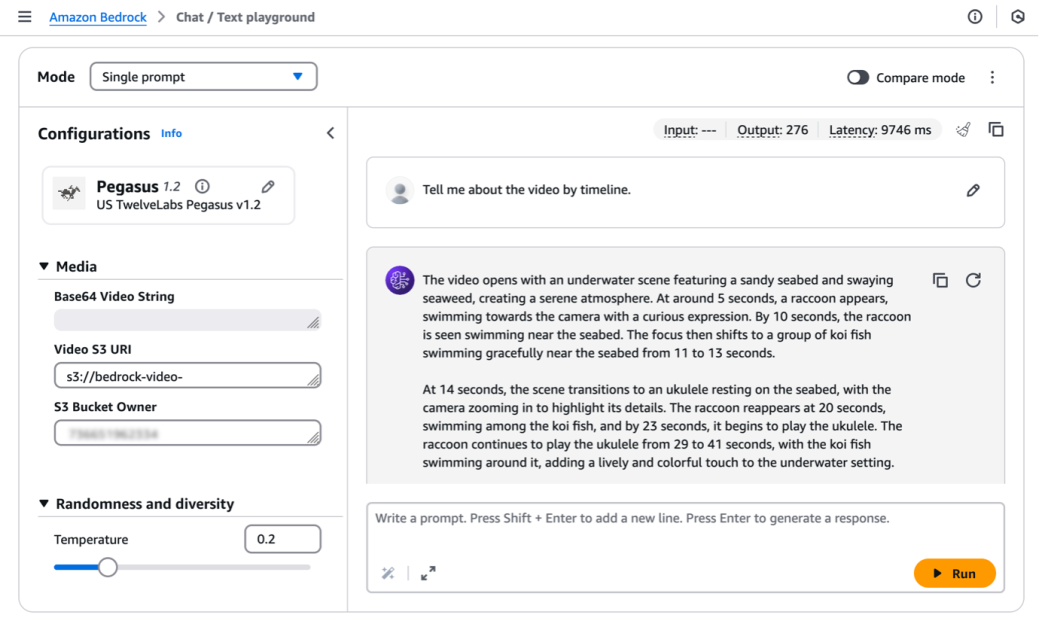

Amazon Bedrock에서 TwelveLabs의 비디오 이해 모델 사용법과 주요 기능을 소개했습니다. 자연어 기반 검색과 요약, 임베딩 생성으로 비디오 분석 애플리케이션을 구축할 수 있습니다.

당근이 AI 실험을 통해 새로운 사용자 경험을 만드는 과정을 소개했습니다. 호기심을 행동으로 바꾸는 설계와 반복 개선의 중요성을 강조했습니다.

X

LLM으로 중고 스마트폰 게시글에서 시세 산정용 정보를 추출하고 후처리하는 서비스를 구축했습니다. BigQuery, MySQL, 벡터 DB를 조합해 시세 조회와 유사 게시글 추천을 구현했습니다.


텍스트를 숫자와 벡터로 표현하는 여러 방법과 문장 임베딩 기반 의미 검색을 정리했습니다. 또한 BERT, FAISS, 하이브리드 검색의 구조와 활용 방향을 소개했습니다.


실시간 행동 이력과 위치 정보를 반영하는 추천 시스템의 요구사항을 기술 문제로 풀어냈습니다. 벡터 검색 도입 과정에서 pre filter와 ANN의 한계를 검토하고 후보군 실험을 진행했습니다.