서비스 조직에서 Kafka를 사용할 때 알아 두어야 할 것들 (3)

서비스 조직에서 Kafka를 사용할 때 알아 두어야 할 것들 (3)
Kafka Client가 클러스터 상태를 파악하는 metadata 동작 방식을 설명했습니다. 서비스 개발 시 관련 옵션을 어떻게 설정하면 좋은지도 다뤘습니다.
#Kafka#event
198005분
Kafka Client가 클러스터 상태를 파악하는 metadata 동작 방식을 설명했습니다. 서비스 개발 시 관련 옵션을 어떻게 설정하면 좋은지도 다뤘습니다.
Kafka 프로듀서 최적화와 압축 기능 활용법을 정리한 발표 내용입니다. 자료 구조, 메시지 전송 흐름, 주요 설정값을 통해 성능 개선 포인트를 소개했습니다.
네이버 홈피드의 개인화 추천 구조와 랭킹 고도화 과정을 소개했습니다.\nLLM, 리트리버, 랭커를 활용해 클릭과 만족도, 다양성을 함께 개선했습니다.

실거리 기반 배차 정확도를 높이기 위해 OSRM, Kafka, Redis를 활용한 저장·처리 구조를 설계했습니다. 지역 단위 이벤트 순서 보장과 캐시 재사용으로 대량 경로 계산 부하를 줄였습니다.
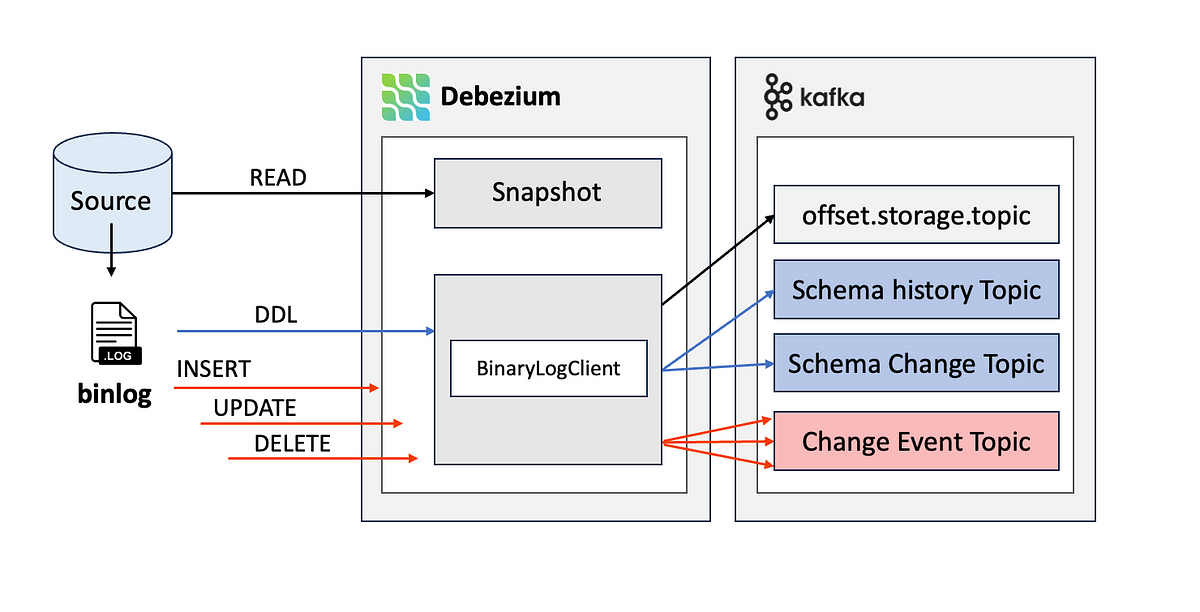

기존 배치 적재의 지연을 줄이기 위해 Debezium 기반 실시간 CDC 파이프라인을 구축한 과정을 정리했습니다. Kafka Connect 구조, 스냅샷, 오프셋 관리와 성능 개선 포인트까지 살펴보았습니다.


분산환경의 메시지 신뢰성과 인가 성능을 동시에 해결하기 위해 구조를 분리한 사례를 소개했습니다. 모든 요청의 권한 체크를 평균 7ms 이내로 처리하도록 설계했습니다.
Kafka 프로듀서 최적화와 압축 기능 활용 방법을 다룬 세션입니다. 실무에서 성능 개선에 도움이 되는 설정과 동작 방식을 정리했습니다.
Kafka Client가 클러스터 상태를 알기 위한 metadata 동작과 교환 방식을 설명했습니다. 서비스 개발에서 관련 옵션을 어떻게 잡아야 하는지도 다뤘습니다.


Azar의 실시간 추천 시스템을 위해 Flink KeyedProcessFunction 기반 스트림 조인과 배포 전략을 구축한 사례를 소개했습니다. Savepoint, Blue-Green 배포, Redis 중복 제거로 무중단과 Exactly Once를 구현했습니다.

Kubeflow로 추천 시스템의 데이터 수집, 학습, 서빙, 튜닝까지 전체 흐름을 구성한 사례를 소개했습니다. 오프라인 추론 전환과 파이프라인 자동화로 응답 속도와 운영 효율을 개선했습니다.

삼성 계정의 대규모 트래픽 환경에서 Kafka를 이용해 개인정보 암호화와 스키마 전환을 다룬 사례입니다. 무중단 운영을 위해 메시지 기반 처리와 단계적 전환을 고려했습니다.


Apache Pinot를 실시간 OLAP 용도로 도입해 운영하며 얻은 안정성·보안·DR 노하우를 정리했습니다. Upsert, Kafka 재개, Trino gRPC 등 실무에서 겪은 주의점과 대응 방법도 함께 소개했습니다.