

코드가 클린 하면 왜 좋아?(feat. 뇌 인지 관점)
클린 코드가 읽기 쉬운 이유를 뇌의 인지 구조 관점에서 설명했습니다. 함수 분리, 중복 제거, 의미 있는 이름이 인지 부하를 줄인다고 정리했습니다.
#클린코드#가독성
23005분
새로운 기술 블로그가 추가되었어요
클린 코드가 읽기 쉬운 이유를 뇌의 인지 구조 관점에서 설명했습니다. 함수 분리, 중복 제거, 의미 있는 이름이 인지 부하를 줄인다고 정리했습니다.
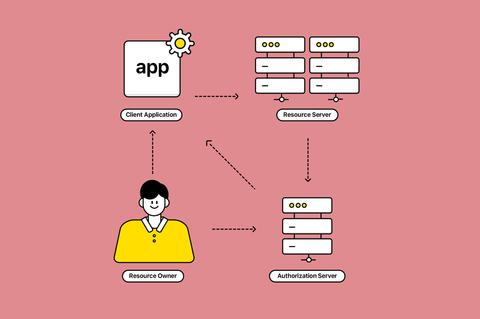

OAuth 2.1 Authorization Server와 Spring Authorization Server 연동 방법을 소개했습니다. Spring 기반으로 인가 서버를 빠르게 살펴보는 내용입니다.


생성형 AI가 데이터 사이언스의 반복 분석과 리포팅을 빠르게 자동화할 가능성을 정리했습니다. 이에 맞춰 조직과 개인이 도메인 이해와 문제 해결 역량을 강화해야 한다고 보았습니다.


ReactorKit을 iOS 앱에 도입한 이유와 핵심 구조를 설명했습니다. 단방향 상태 흐름과 RxSwift 활용 팁으로 실무 적용 포인트를 정리했습니다.

GraphQL을 도입한 배경과 특징을 소개하고, 협업에 어떻게 활용하는지 공유했습니다.\n효과적인 개발 협업을 위한 GraphQL 사용 방식을 간단히 정리했습니다.

S3 업로드를 트리거로 AWS Lambda 이미지 리사이징을 구성한 사례를 정리했습니다. 무한 업로드 방지와 메모리 조정 같은 운영상 주의점도 함께 다뤘습니다.
![[IT TREND] 자율 AI 에이전트, ChatGPT 다음의 메가트렌드?](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fmh9ql%2FbtseNtHZg5L%2FxPmLyTdr51n0VSLiEZWRm0%2Fimg.png)

자율 AI 에이전트와 Auto-GPT의 개념, 작동 방식, 주요 사례를 정리했습니다. 또한 성능·비용·사용성 한계와 함께 ChatGPT 다음 트렌드 가능성을 살펴봤습니다.

Next.js와 d3로 부동산 데이터 시각화 지도를 만들며 구조를 개선한 과정을 정리했습니다. 지도와 시각화 레이어를 분리하고 d3 의존을 줄여 서버 사이드 렌더링도 가능하게 했습니다.

풀필먼트 입고 서비스의 동시성 문제를 해결하기 위해 Redisson 기반 분산락을 적용한 사례를 소개했습니다. AOP와 어노테이션으로 락을 추상화하고 트랜잭션 커밋 이후 해제로 정합성을 보장했습니다.
헤이조이스가 코로나19 대응을 위해 자체 웨비나 시스템을 2주 만에 구축한 과정을 소개했습니다.\nAWS IVS, Sendbird, 서버리스 구성으로 운영 효율과 확장성을 확보한 사례입니다.
Elasticsearch 대용량 인덱스 reindex에서 속도와 안정성을 높이는 설정 조정 사례를 다뤘습니다. replica 분리, refresh 비활성화, throttling과 복구 속도 제한으로 장애를 줄였습니다.


QA 엔지니어의 역량을 네 영역으로 나눠 정리하고, 강점과 약점을 바탕으로 목표를 세우는 방법을 소개했습니다. 작성자는 자신의 현재 위치와 개선 계획, 자동화 테스트 학습 방향도 함께 공유했습니다.