


수식없이 GPT(트랜스포머) 이해하기. 2편
GPT 기반 LLM의 추론 최적화와 양자화 개념을 설명했습니다. DeepSeek의 Latent Vector 기반 방식으로 KV Cache 메모리를 줄이는 사례도 다뤘습니다.
#LLM#KV Cache
69005분
새로운 기술 블로그가 추가되었어요
GPT 기반 LLM의 추론 최적화와 양자화 개념을 설명했습니다. DeepSeek의 Latent Vector 기반 방식으로 KV Cache 메모리를 줄이는 사례도 다뤘습니다.

Perplexity AI의 브라우저 Comet 주요 기능과 활용 사례를 소개했습니다. AI 검색과 자동화가 강점이지만 일부 기능은 아직 보완이 필요했습니다.


사람인 내부 데이터를 활용해 LLM 챗봇을 구축하고, RAG와 Function Calling으로 답변 정확도를 높였습니다. 또한 LangGraph와 멀티테넌시, 모니터링으로 운영성과 확장성을 함께 개선했습니다.

멀티턴 RAG에서 맥락 손실로 생기는 검색 오류를 쿼리 재작성으로 줄이는 방법을 다뤘습니다. Step-Back, HyDE, Multi-Query와 적응형 라우팅으로 품질과 속도를 함께 조정했습니다.

뱅크샐러드 샐러드게임에서 운영자가 안전하게 규칙을 바꾸기 위해 DSL과 LLM을 결합한 방식을 소개했습니다. 한글 지원, 테스트 API, 이중 검토로 환각과 위험을 줄인 점이 핵심입니다.

A2A 프로토콜을 활용한 실무 사례와 동작 구조를 소개했습니다. 호스트 에이전트가 여러 리모트 에이전트를 호출해 결과를 종합하는 흐름을 설명했습니다.


AI 에이전트를 활용한 취약점 관리 자동화 사례를 Claude Code, Opus Security, Cycode, DeepSource 중심으로 정리했습니다.자동화는 탐지와 수정 효율을 높이지만, 수동 검토와 병행해야 한다고 설명했습니다.
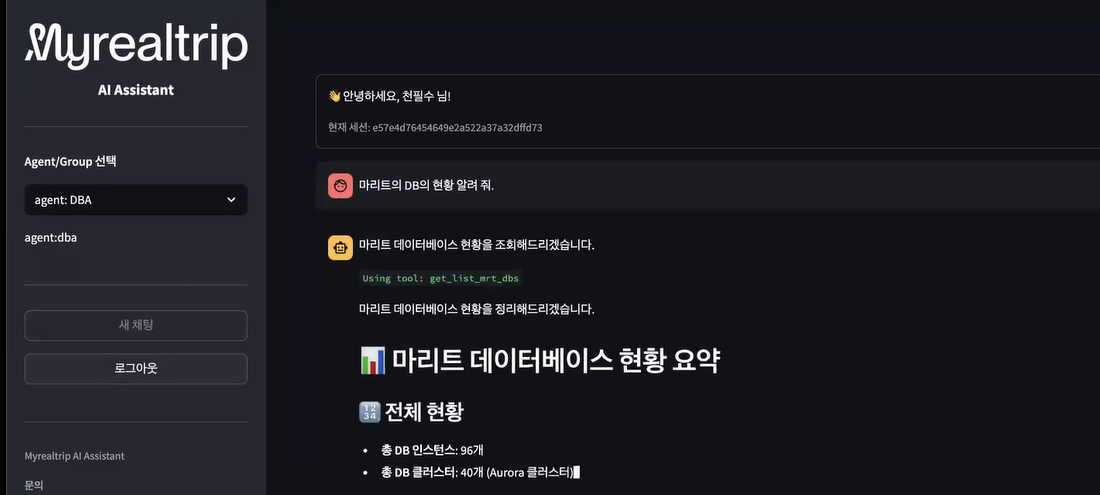
소규모 팀의 DBA 공백 문제를 AI 에이전트로 보완한 사례를 소개했습니다. MCP 도구와 사전 검증으로 안전성을 높이며 MAIA 플랫폼으로 확장했습니다.

실시간 AI 스트리밍에서는 모델 성능뿐 아니라 토큰 전달의 자연스러움이 중요하다고 설명했습니다. WebSocket, Lambda, DynamoDB를 활용한 연결 관리와 백프레셔, 순서 보장 방식을 정리했습니다.
![[에이닷 4.0 QE 여정3] LLM 품질 평가의 진화: SPeCTRA 2.0 톺아보기](https://devocean.sk.com/thumnail/2025/9/2/18a05ae6f560f5663e7ef7428eb491c7362f850ffff2113554dc7f15d3f4db6f.png)
에이닷 4.0 개편에 맞춰 SPeCTRA 2.0이 API 중심 Web 평가 도구로 진화했습니다. 내부 로그와 Memory까지 함께 검증해 품질 평가의 신뢰성과 속도를 높였습니다.

오픈챗 메시지에서 트렌딩 키워드를 뽑는 통계적 방법을 소개했습니다. 빈도 급증 탐지, 중복 제거, NPMI 필터, MMR 다양화로 품질을 높였습니다.
Amazon Bedrock 기반 AI Agent 솔루션 에이블의 AWS Marketplace 등록 소식입니다. 별도 설치 없이 클라우드에서 AI 에이전트를 생성·운영할 수 있고, 기업 데이터 벡터화와 지식 검색 기능을 제공합니다.