
(Airflow #1) 데이터 엔지니어들이 선택하는 Apache Airflow 소개
X
#Airflow
26005분
X


데이터카탈로그를 통해 데이터 디스커버리를 검색, 미리보기, 리니지의 3단계로 풀어낸 사례를 소개했습니다. 데이터 찾기뿐 아니라 이해와 신뢰 확보까지 연결하는 방향을 제시했습니다.


쏘카 데이터 엔지니어링팀 합류 후 온보딩과 프로젝트, 온콜 경험을 회고한 글입니다. 체계적인 문서화와 협업 문화가 실무 적응에 큰 도움이 되었다고 정리했습니다.

검색어와 문서를 함께 고려해 사용자 의도를 세분화하는 LLM 기반 모델을 설계했습니다. 이를 통해 추천의 맥락 정확도를 높이고 CTR도 개선했습니다.


카카오페이 FDS에 지속 성장하는 ML을 적용해 급변하는 사고 패턴에 대응한 사례를 소개했습니다. 지속적 학습과 자가 적응 피처로 신규 유형 사고 탐지 성능을 높였습니다.
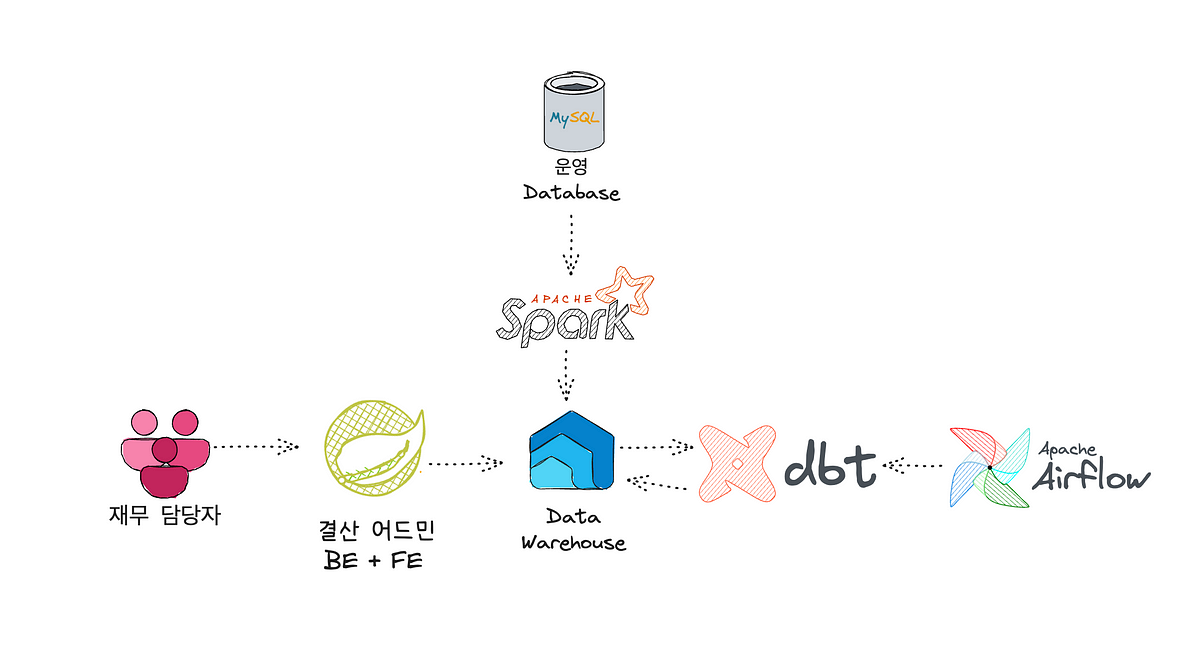
매월 반복되던 재무 결산을 Spring Batch와 코드 중심 구조에서 Airflow와 dbt 기반 데이터 파이프라인으로 전환했습니다. SQL 수정만으로 결산 대응이 가능해져 유연성과 가시성을 높였습니다.

카카오뱅크가 퍼블릭 클라우드에 펀드 시스템을 구축한 사례를 소개했습니다. Airflow로 금융 규제를 충족하며 배치 작업을 효율화한 과정을 다뤘습니다.

Iceberg를 DataLake에 도입해 Kafka·CDC 입수와 테이블 운영을 더 효율적으로 개선했습니다. 또한 자동화된 모니터링과 유지보수로 실시간 조회와 성능 최적화를 함께 달성했습니다.

Hive 배치 기반 파생 데이터 생성 지연 문제를 Spark Streaming으로 실시간 처리하도록 전환한 사례를 소개했습니다. Kafka 오프셋과 처리량, LAG 모니터링으로 안정적인 운영 방법도 함께 설명했습니다.