[Hands-On] AI 에이전트 직접 구현해보기

[Hands-On] AI 에이전트 직접 구현해보기
기본형 AI 에이전트를 직접 구현하며 도구 사용과 반복 추론 구조를 설명했습니다. Gradio 테스트와 DB, Git 시나리오로 실제 동작도 확인했습니다.
#LLM#langchain
132005분
기본형 AI 에이전트를 직접 구현하며 도구 사용과 반복 추론 구조를 설명했습니다. Gradio 테스트와 DB, Git 시나리오로 실제 동작도 확인했습니다.


Spark에서 Rest API 데이터를 수집하는 두 가지 방법을 비교했습니다. 단순 requests 방식과 Spark UDF 방식의 장단점 및 대량 데이터 처리 시 고려점을 설명했습니다.


AI 시대 흐름에 맞춰 LLM과 LangChain의 개념, 한계를 처음 정리한 글입니다. OpenAI API와 Colab으로 gpt-3.5-turbo를 호출하는 간단한 실습도 소개했습니다.
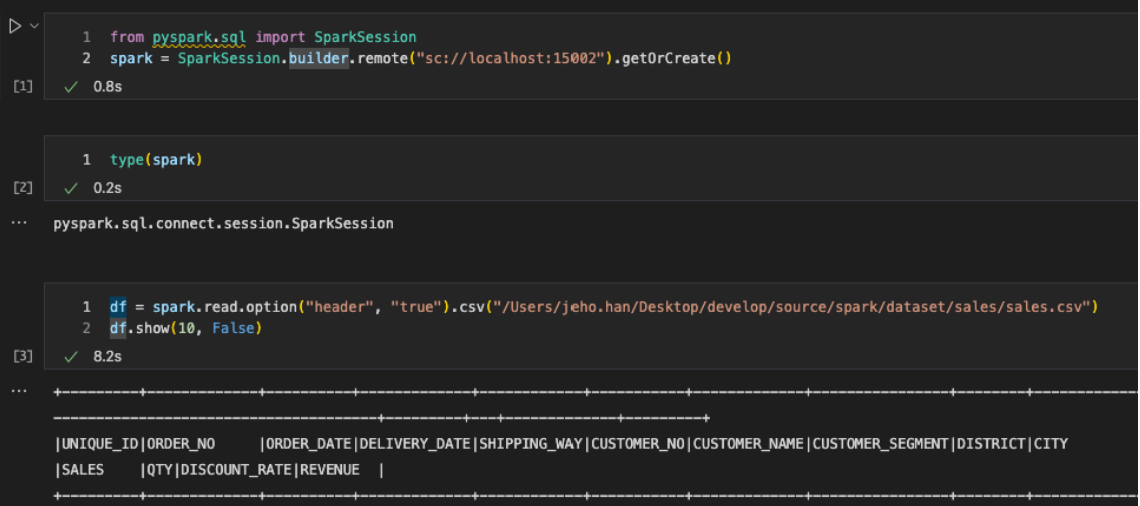
Spark의 원격 연동 한계를 보완하는 Spark Connect의 등장 배경과 동작 방식을 소개했습니다. 서버·클라이언트 환경을 구성해 Jupyter Notebook에서 실제 연결과 실행을 확인했습니다.
![[BigData] Spark 개요 정리](https://bespin-wordpress-bucket.s3.ap-northeast-2.amazonaws.com/wp-content/uploads/2025/03/image-10.png)
Spark의 개요와 주요 구성요소, 장점을 정리한 글입니다. 대용량 데이터 처리에서 Pandas보다 Spark가 더 적합한 성능 사례도 비교했습니다.

Redis 클라이언트 캐시의 최신성 문제를 해결하기 위한 Client Caching 동작 방식을 설명했습니다. Invalidation 메시지로 로컬 캐시를 동기화하는 예제와 적용 흐름도 함께 다뤘습니다.


알라미 유저의 사용 패턴을 Feature Engineering과 KMeans 클러스터링으로 분석한 사례입니다. 숫자 결과에 해석을 붙여 페르소나처럼 설명하고 리텐션까지 확장했습니다.

LLM 기반 AI 에이전트의 Tool Calling 한계를 Code Interpreter로 확장하는 흐름을 설명했습니다. Docker 샌드박스와 LangGraph로 안전하게 적용하는 예시도 함께 다뤘습니다.


개발/테스트용 EC2의 불필요한 실행 비용을 줄이기 위해 자동 시작·중지 구성을 소개했습니다. EventBridge와 Lambda, 태그 기반 필터링으로 업무 시간에만 인스턴스를 제어했습니다.

FastAPI의 Depends()로 의존성 주입을 적용하는 방법을 설명했습니다. 비즈니스 로직과 구현체를 분리해 유연성과 테스트 용이성을 높이는 구조를 소개했습니다.
Amazon Bedrock과 Lambda, API Gateway를 연결해 긴 텍스트 요약 API를 구성하는 과정을 다루었습니다. 요청 전달, IAM 권한, 응답 처리와 테스트 방법까지 실습 중심으로 설명했습니다.

LLMOps 구축 사례를 통해 LLM 애플리케이션의 데이터 준비, 프롬프트, 배포, 테스트를 하나의 흐름으로 관리하는 방법을 소개했습니다. 도메인 전문가 참여와 재사용 가능한 공통 컴포넌트로 협업 효율을 높인 내용입니다.